

论文题目:《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》
论文作者:Qibin Hou, Zihang Jiang, Li Yuan et al.
论文发表年份:2022.2
模型简称:ViP
发表期刊:IEEE Transactions on Pattern Analysis and Machine Intelligence
Abstract
在本文中,我们提出了一种概念简单、数据高效的类似MLP的视觉识别体系结构——视觉置换器(Vision Permutator)。不同于最近的类似MLP的模型大都沿着平坦的空间维度编码空间信息。由于认识到二维特征表示所携带的位置信息的重要性,Vision Permutator通过线性投影分别对沿高度和宽度维度的特征表示进行编码。这使得Vision Permutator可以沿着一个空间方向捕获远程依赖关系,同时保持沿着另一个方向的精确位置信息。由此产生的位置敏感输出,然后以相互补充的方式聚合,形成感兴趣的对象的表达。Vision Permutator由纯1 × 1卷积组成,但可以对全局信息进行编码。Vision Permutator也消除了对自注意力的依赖,因此效率更高。开源代码: https://github.com/Andrew-Qibin/VisionPermutator
Method
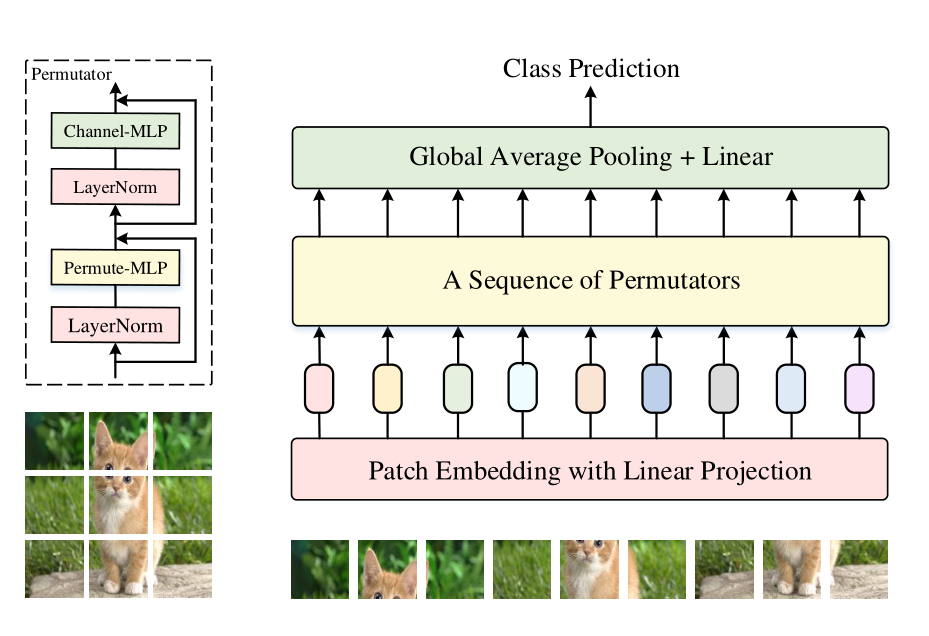

Vision Permutator从与Vision Transformers类似的tokenization操作开始,它将输入图像统一地分割为小块,然后将它们映射到带有线性投影的token embedding。然后将形状为”height×width×channels”的结果token embeddings到Permutator block序列中,每个Permutator block由一个用于空间信息编码的Permute-MLP和一个用于通道信息混合的Channel – MLP组成。Permute-MLP层如下图所示,
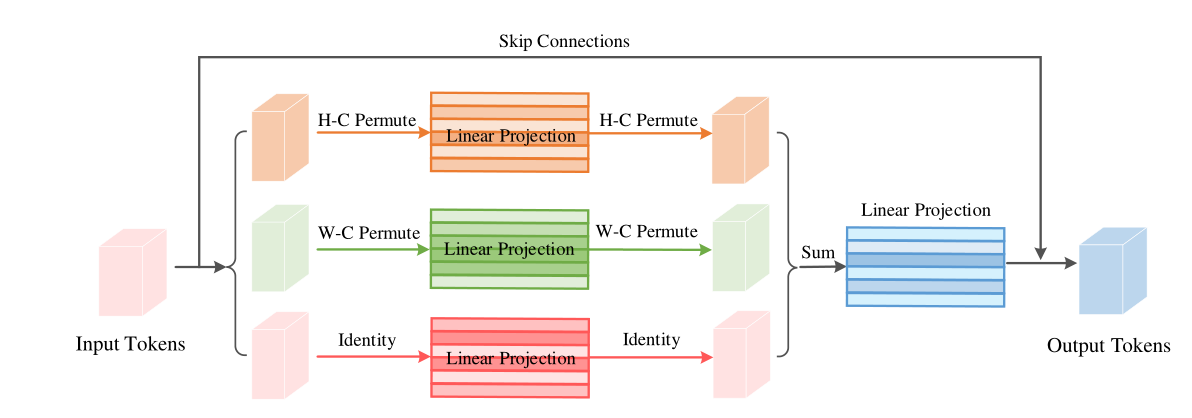
Permute-MLP层由三个独立的分支组成,每个分支沿特定的维度编码特征,即高度、宽度或通道维度。Channel-MLP模块的结构与Transformer中的前馈层相似,包括两个完全连接的层,中间有一个GELU激活。完整的Vip架构公式如下:

对于Channel信息编码,只需要一个权重WC∈RC×C的全连接层,就可以对输入X进行线性投影,得到XC。对于高度信息编码,首先对传入的分割好的每个tokens作维度变换(ex:Transpose the first (Height) dimension and the third (Channel) dimension: (H, W, C) → (C, W, H).)然后沿着通道维度连接它们作为Premute的输出,传入Linear Projection:连接权重为WH∈RC×C的全连接层,混合高度信息。再通过维度变换复原输入维度。对宽度信息编码作类似处理,最后讲三个分支的输出加和作为最后全连接层的输入。Linear Projection的输出公式表示如下:(最后输出再与input tokens作跳跃连接得到最终Permute-MLP的输出。)
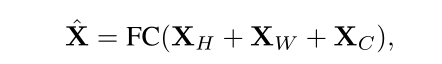
Weighted Permute-MLP:上述方法只是简单地将所有三个分支的输出通过元素相加来融合。在这里,我们通过重新校准不同分支的重要性,进一步改进了上述Permute-MLP,并提出加权Permute-MLP。这可以通过利用分散注意力(split attention)实现。不同的是,分散注意力应用于XH、XW和XC,而不是由分组卷积生成的一组张量。在下文中,我们默认使用Permutator中的加权Permute-MLP。
Experiment
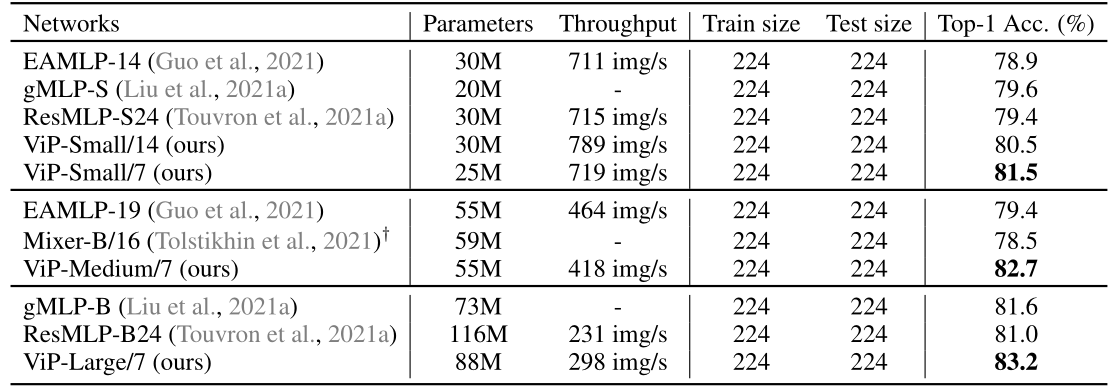
与ImageNet上最近的类MLP模型比较Top-1精度,所有模型都是在没有外部数据的情况下进行训练的。在相同的计算量和参数约束下,我们的模型始终优于其他方法。
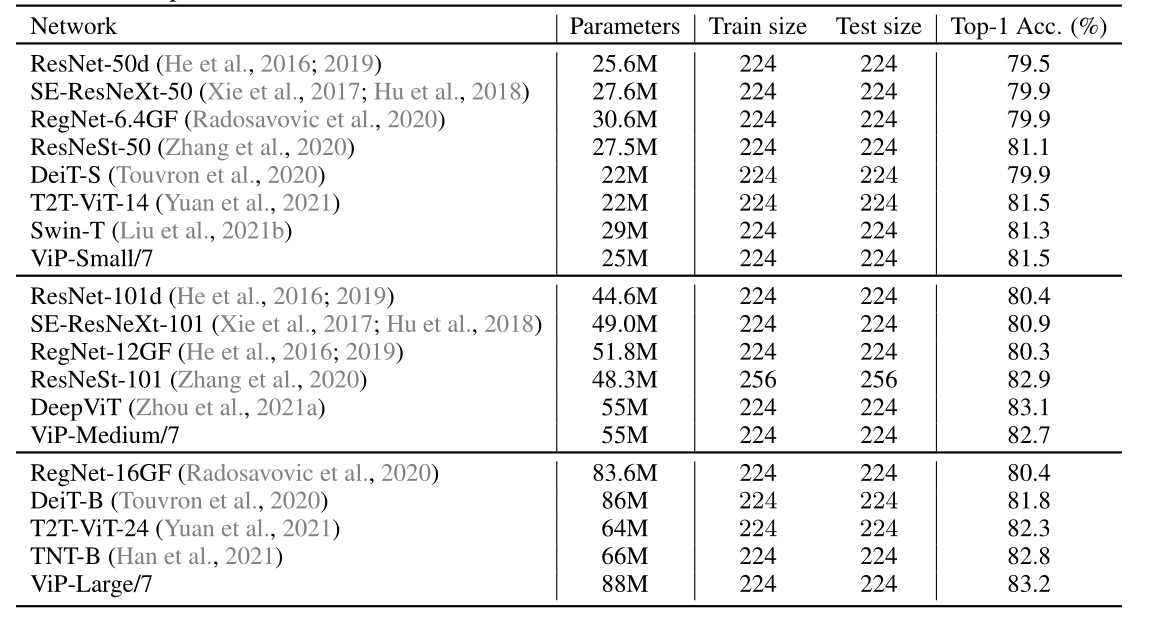
与ImageNet上的经典CNN和Vision Transformer的精度比较。所有模型都是在没有外部数据的情况下进行训练的。在相同的计算和参数约束下,我们的模型可以与一些强大的基于CNN和基于Transformer的模型竞争。
.
Original: https://www.cnblogs.com/AllFever/p/16727241.html
Author: AllFever
Title: 《Vision Permutator: A Permutable MLP-Like ArchItecture For Visual Recognition》论文笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/804805/
转载文章受原作者版权保护。转载请注明原作者出处!