

1 度分布
网络的度分布(p(k))表示了一个随机选择的节点拥有度(k)的概率。我们设度为(k)的节点数目(N_k = \sharp\text{ nodes with degree } k),除以节点数量(N)则可得到归一化后的概率质量分布:
[P(k)=N_k / N(k\in \mathbb{N}) ]
我们有:(\sum_{k \in \mathbb{\mathbb{N}}} P(k)=1)。
对于下面这个网络:
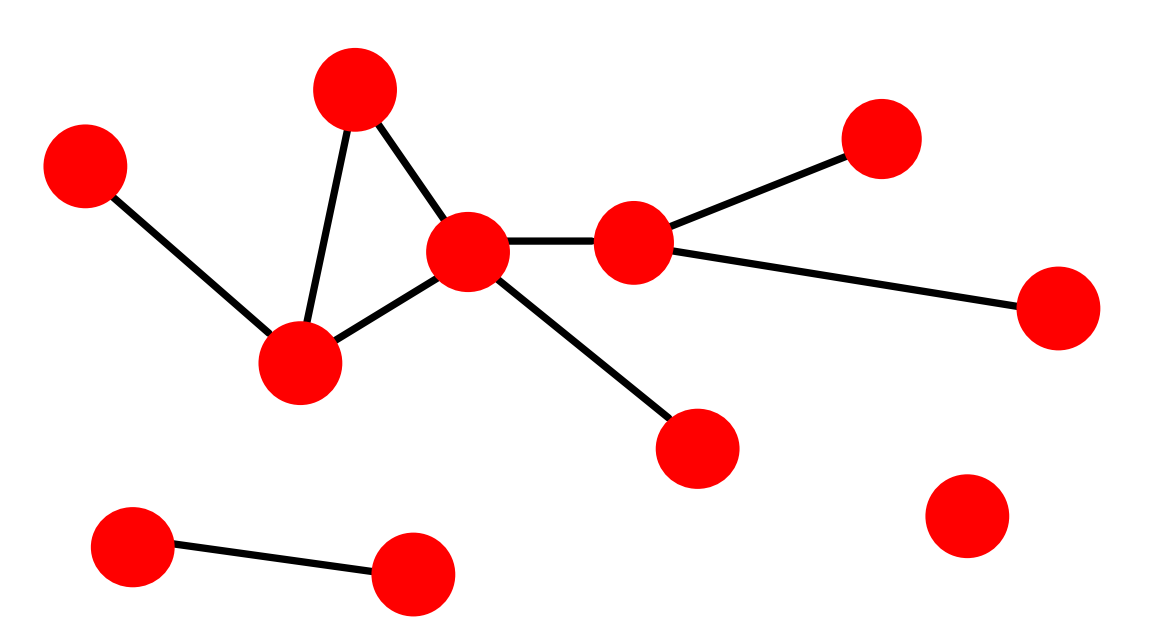

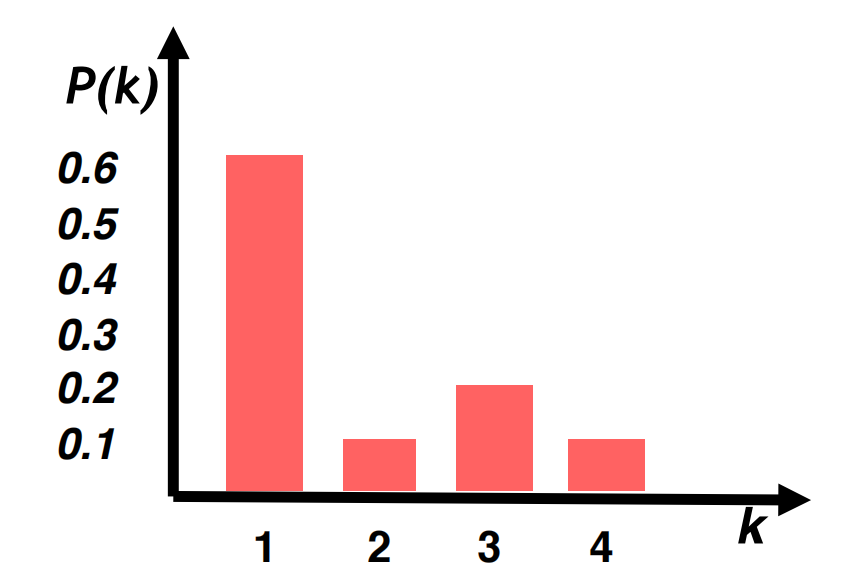
其归一化后的度分布直方图可表示如下:
2 路径
2.1 图的路径
图的路径(path)指一个节点序列,使得序列中的每个节点都链接到序列中的下一个节点(注意:这里的术语不同教材不一样,有的教材把这里的路径定义为漫游(walk),而将术语”路径”保留给简单路径)。路径可以用以下方式进行表示:
[P_n=\left{i_0, i_1, i_2, \ldots, i_n\right} \quad P_n=\left{\left(i_0, i_1\right),\left(i_1, i_2\right),\left(i_2, i_3\right), \ldots,\left(i_{n-1}, i_n\right)\right} ]
一个路径可以通过经过同一条边多次而和它自身相交。如下面这个图中更多路径ABDCDEG就和自身相交。
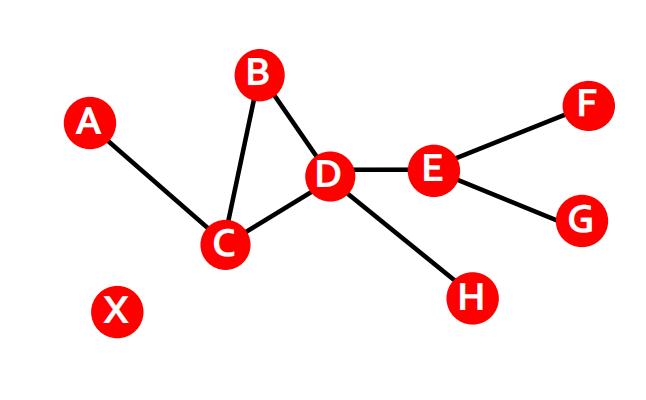
注意,在有向图中路径只能沿着边的方向。
2.2 路径的条数
路径的条数定义为节点(u)和(v)之间的路径数量。我们发现邻接矩阵的幂和路径的条数之间有着关系。
- 长度(h=1)(这里的h可理解为跳数hops)的路径计数矩阵: 只需要考察(u)和(v)之间是否存在长度为(1)的链接,即 [H_{uv}^{(1)} = A_{uv} ]
- 长度(h=2)的路径计数矩阵: 需要考察(u)和(v)之间是否存在长度为(2)的路径,即对满足(A_{u k}A_{k v}=1)的(k)进行计数。 [H_{u v}^{(2)}=\sum_{k=1}^N A_{u k} A_{k v}=\left[A^2\right]_{u v} ]
- 长度(h)的路径计数矩阵: 需要考察(u)和(v)之间是否存在长度为(h)的路径,即对满足(A_{u k_1} A_{k_1 k_2} \ldots . A_{k_{h-1} v}=1)的所有(\langle k_1,k_2,\cdots, k_{h-1}\rangle)序列进行计数。 [H_{u v}^{(h)}=\left[A^h\right]_{u v} ]
上述结论对有向图和无向图都成立。上述定理解释了如果(u)和(v)之间存在最短路径,那么它的长度就是使(A^k_{uv})非零的最小的(k)。
进一步推论可知,在一个(n)个节点的图中找到所有最短路径的一个简单方法是一个接一个地对图的邻接矩阵(A)做连续的幂计算,知道第(n-1)次,观察使得每一个元素首次变为正值的幂计算。这个思想在Folyd-Warshall最短路径算法中有着重要应用应用。
2.3 距离
图中两个节点之间的距离(distance)定义为两个点最短路径中的边数(如果两个点没有连通,距离通常定义为无穷大)。
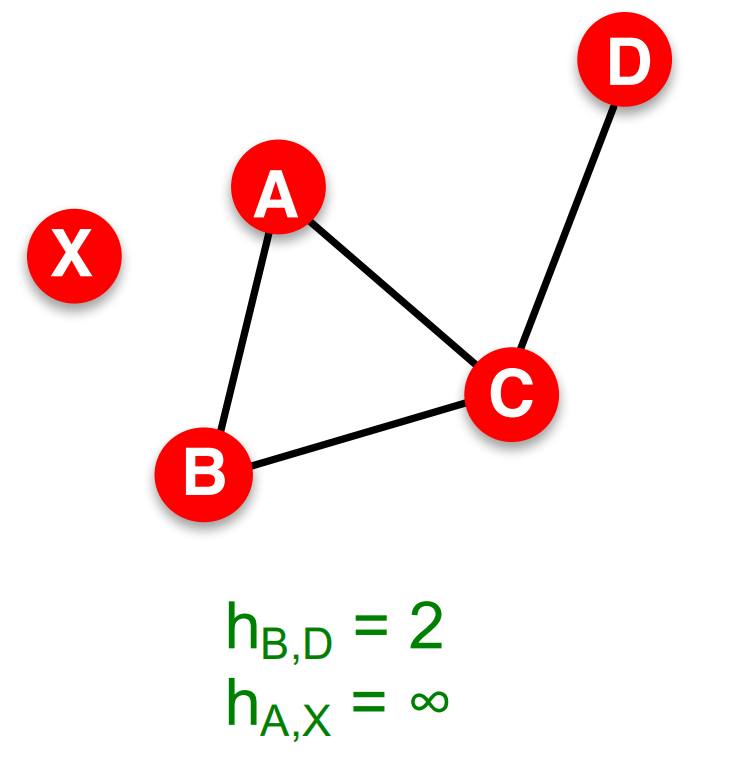
如对下面这个图我们有(B)、(D)之间的距离(H_{B,D}=2),(A)、(X)之间的距离(h_{A, X}=\infty)。
注意,在有向图中距离必须沿着边的方向。这导致有向图中的距离不具有对称性。比如下面这个图中我们就有(h_{A, C} \neq h_{C, A})。
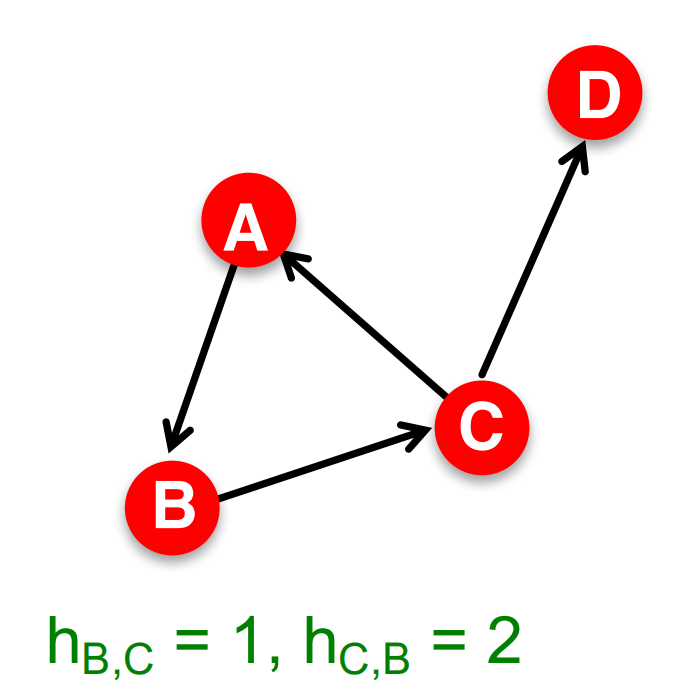
我们定义两两节点之间距离的最大值为图的直径(diameter)。
2.4 平均路径长度
无向连通图(连通分量)或有向强连通图(强连通分量)的平均路径长度(average path length)定义为:
[\bar{h}=\frac{1}{2 E_{\max }} \sum_{i, j \neq i} h_{i j} ]
这里(h_{ij})是节点(i)到(j)的距离。(E_{max}=\frac{n(n-1)}{2}),这里(2E_{max})中的系数(2)可要可不要,不同教材定义方法不一样。
在计算平均路径长度时,我们通常只计算连通节点之间的距离(也即忽略长度为”无穷”的路径)
2.5 寻找最短路径
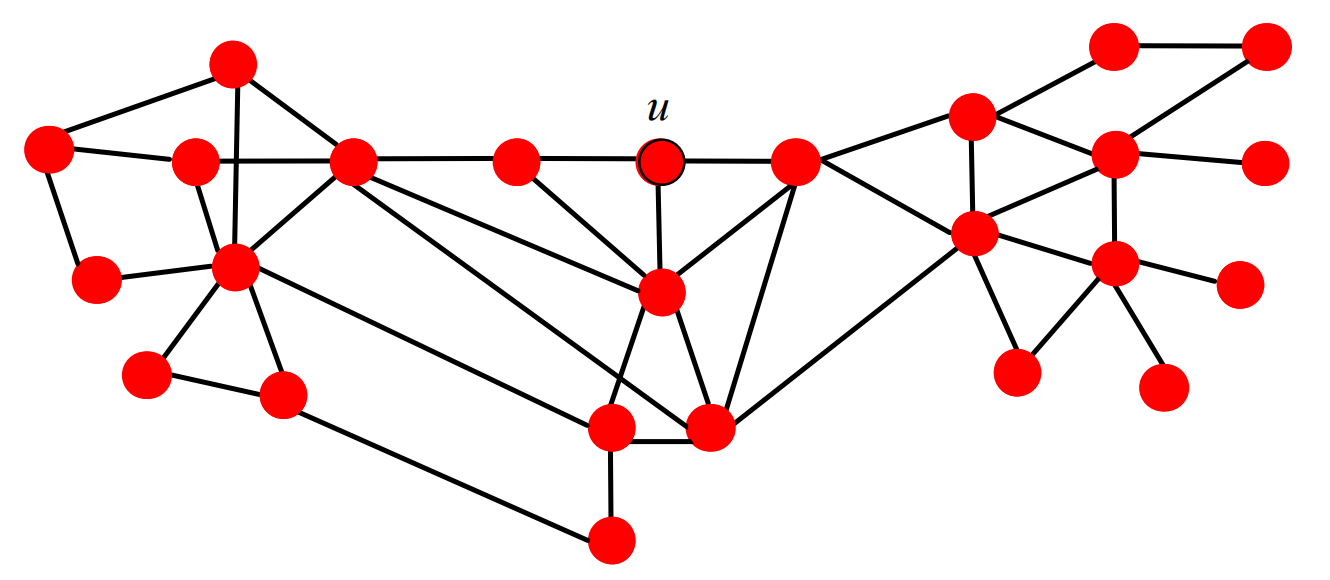
对于无权图,我们可以由宽度优先搜索(BFS)搜寻图的最短路径。
- 从节点(u)开始,将其标注为(h_u(u)=0),并将其加入队列。
- 当队列不为空时:
- 将队首元素(v)移出队列,将其未标注的邻居加入队列并标注为(h_u(w) = h_u(v) + 1)。
- 循环往复。
对于带权图,我们当然就得寻求Dijkstra、Bellman-Ford等算法啦,此处不再赘述.
3 节点中心性
节点(i)的中心性(centrality)可以用于度量节点(i)的重要程度。节点的中心性有许多种类,下面我们介绍介数中心性(betweeness centrality)和接近中心性(closeness centrality)。
3.1 介数中心性
介数中心性基于这样一个思想:如果一个节点在许多其它节点之间的最短路径上,那么这个节点就是重要的。于是我们可以将节点(i)的介数中心性定义为:
[c_v=\sum_{s \neq v \neq t} \frac{#(\text { shortest paths betwen } s \text { and } t \text { that contain } v)}{#(\text { shortest paths between } s \text { and } t)} ]
以下面这个图为例:
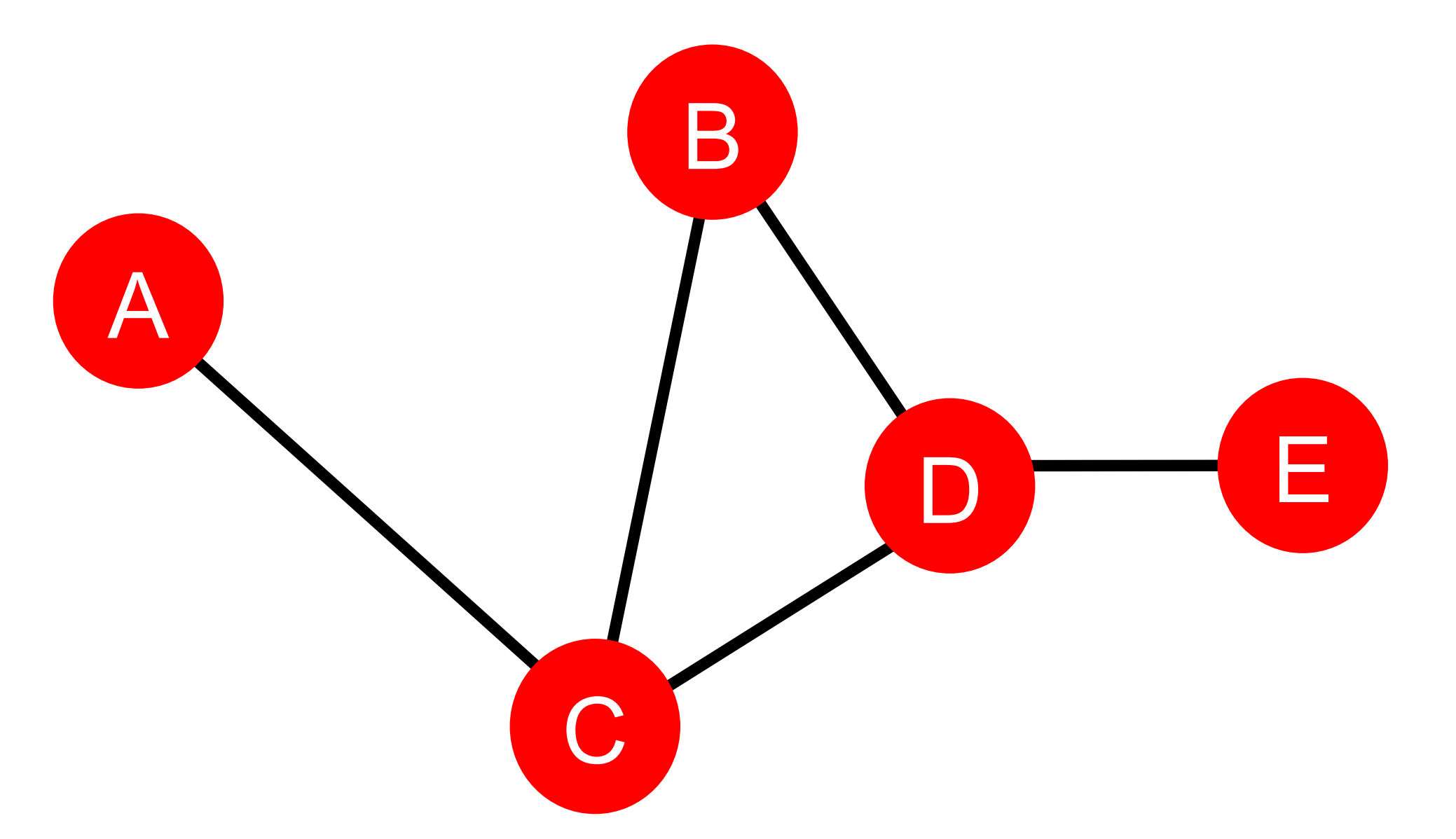
[c_A=c_B=c_E=0\ c_C=3\ (\text{A-C-B}, \text{A-C-D}, \text{A-C-D-E})\ c_D=3\ (\text{A-C-D-E}, \text{B-D-E}, \text{C-D-E}) ]
3.2 接近中心性
接近中心性基于这样一个思想:如果一个节点到其它所有节点的最短路径长度都很小,那么这个节点就是重要的。于是我们可以将节点(i)的接近中心性定义为:
[c_v=\frac{1}{\sum_{u \neq v} \text { shortest path length between } u \text { and } v} ]
还是以上面那个图为例,在该图中有:
[c_A=1 /(2+1+2+3)=1 / 8 \ (\text{A-C-B}, \text{A-C}, \text{A-C-D},\text{A-C-D-E})\ c_D=1 /(2+1+1+1)=1 / 5 \ (\text{D-C-A}, \text{D-B}, \text{D-C}, \text{D-E}) ]
4 聚类系数
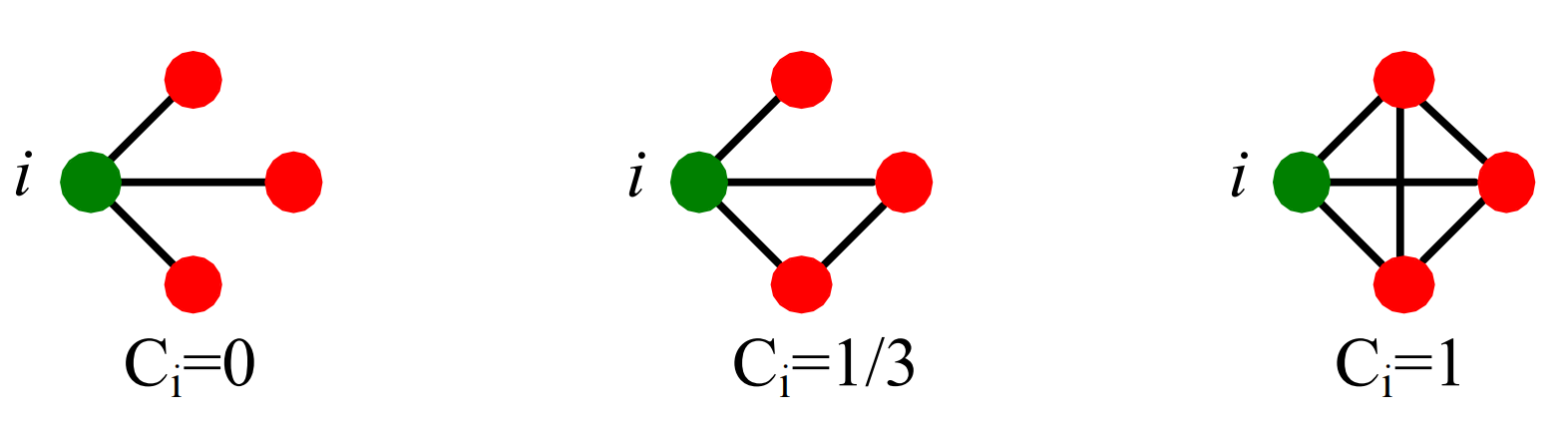
节点(i)的聚类系数(clustering coefficient)可以直观地理解为节点(i)的邻居有多大比例是互相连接的。设节点(i)的度为(k_i),则其聚类系数(C_i)定义为
[C_i=\frac{2 e_i}{k_i\left(k_i-1\right)} ]
这里(e_i)为节点(i)邻居之间的边数,我们有(C_i\in[0, 1])。下面展示了聚类系数的一些实例:
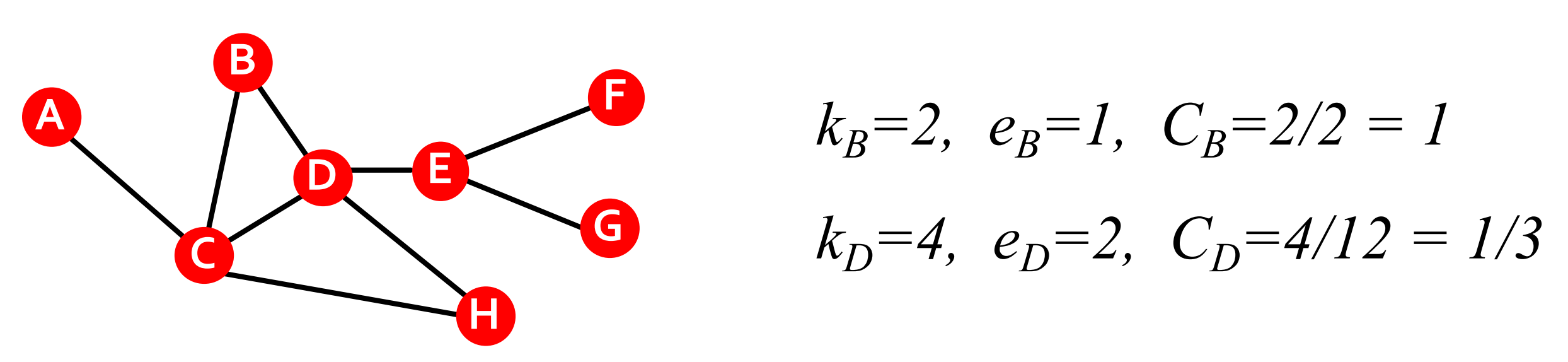
图的平均聚类系数(average clustering coefficient)定义为:
[C=\frac{1}{N} \sum_i^N C_i ]
5 真实世界网络的属性
接下来我们来看一MSN收发信息网络(有向)的实例。
该网络中245 million用户注册,180 million用户参与了聊天,拥有超过30 billion个回话。超过 255 billion条交互信息。
连通性

度分布
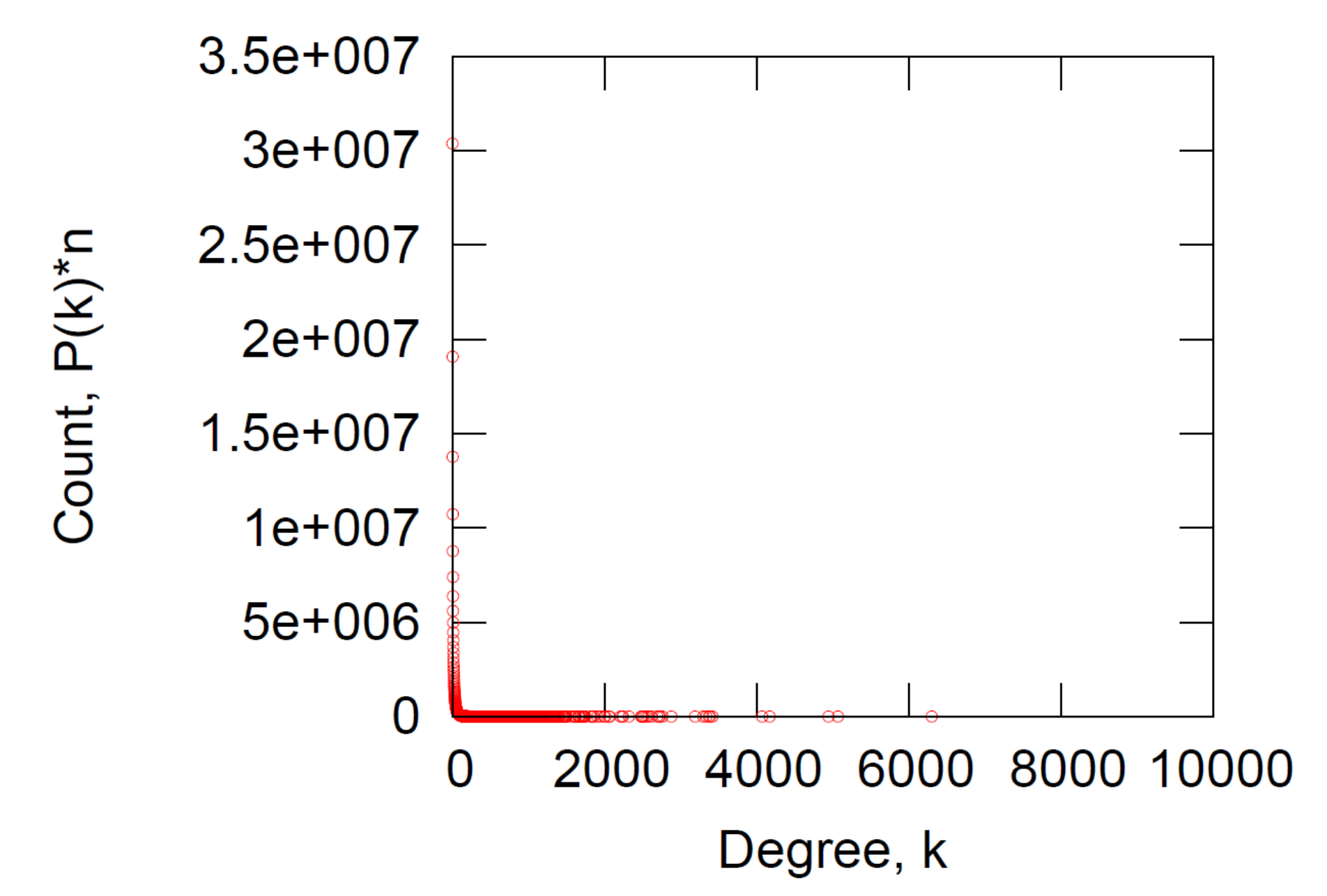
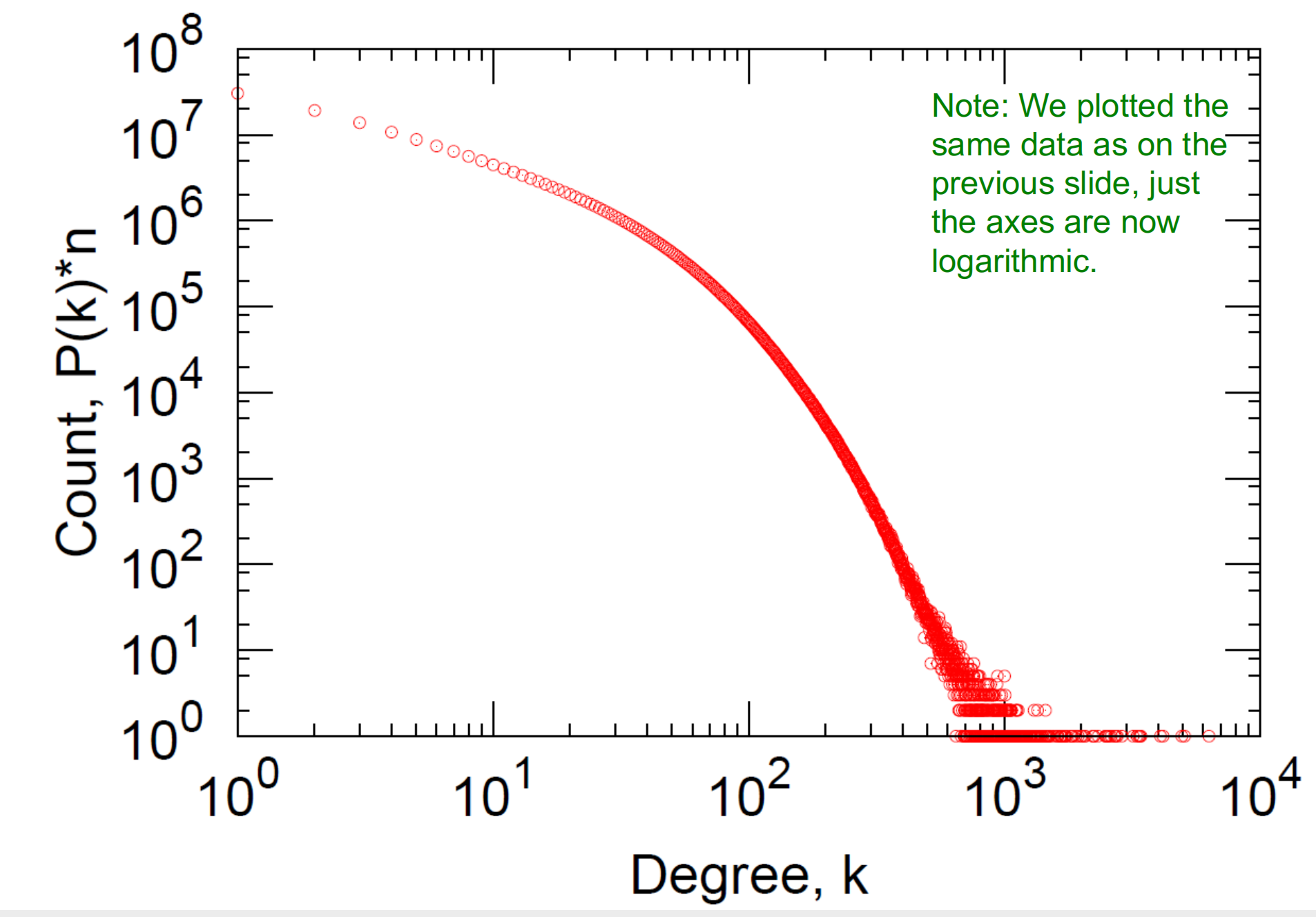
其度分布高度倾斜,平均度为(14.4)。
log-log度分布
聚类系数
这里为了方便出图,我们定义横坐标为度(k),对应的纵坐标(C_k)为度为(k)的节点的聚类系数(C_i)的平均值,即(C_k=\frac{1}{N_k} \sum_{i: k_i=k} C_i)。
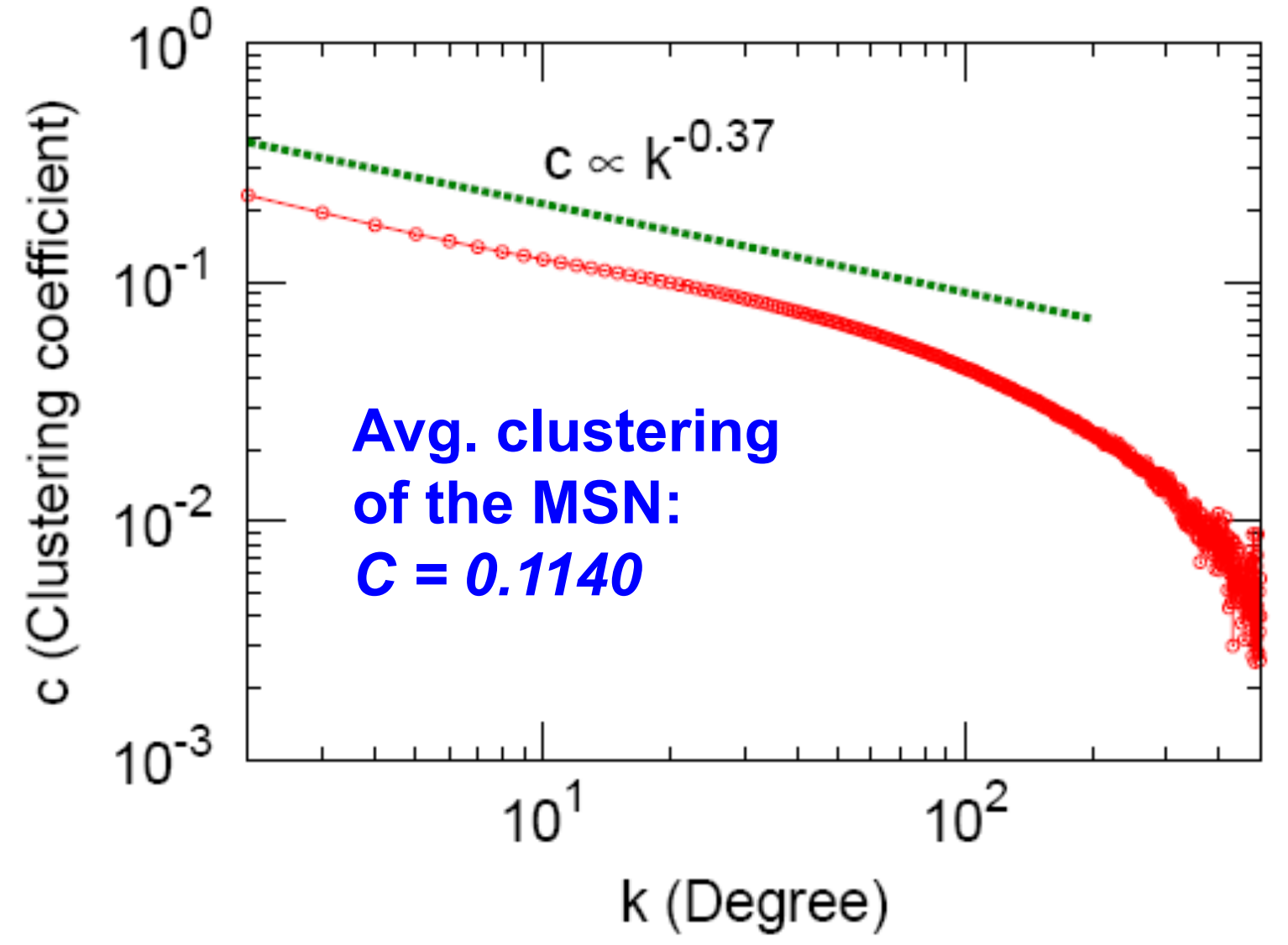
整个网络的平均聚类系数为(0.11)。
距离分布
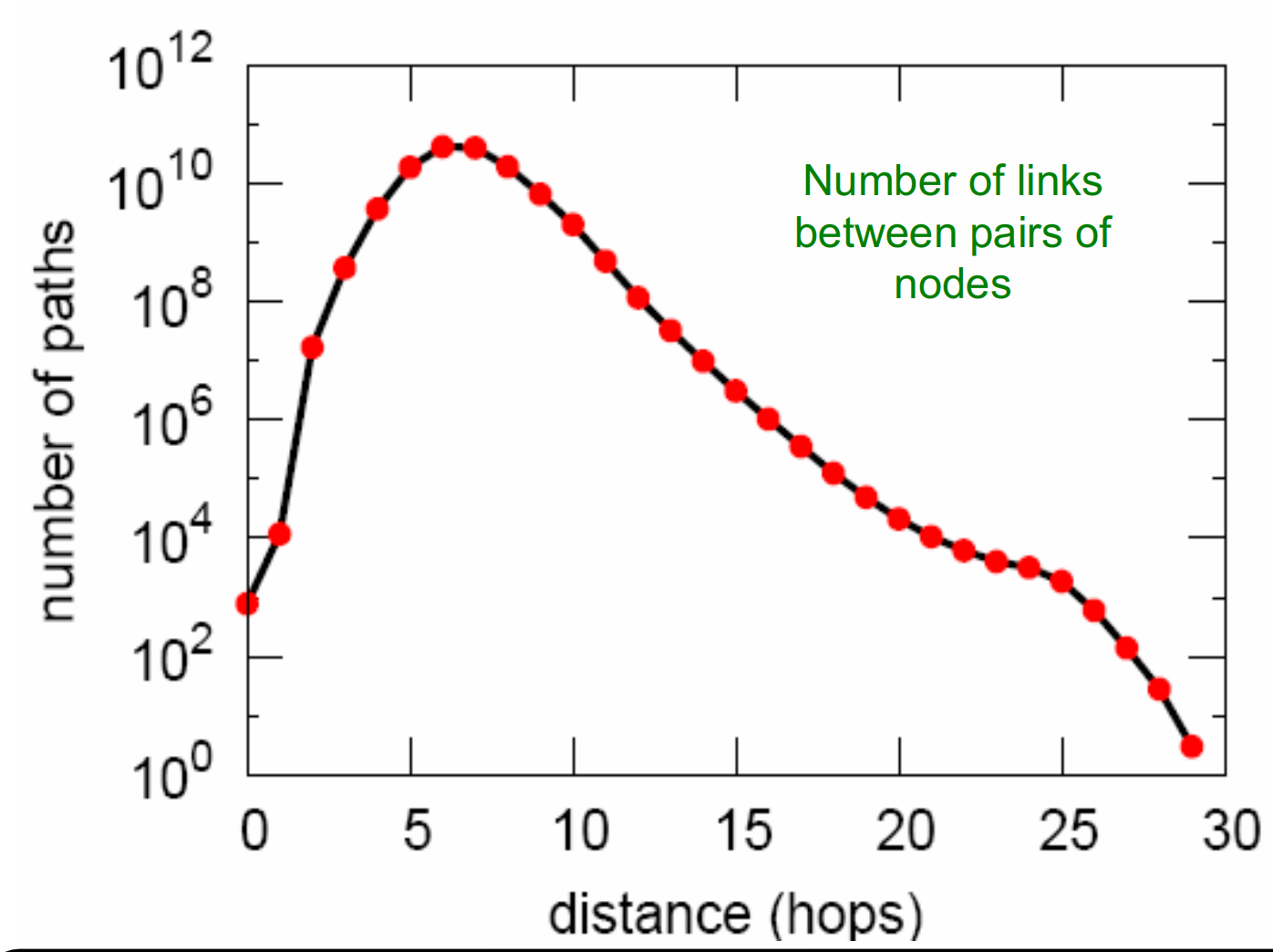
其中平均路径长度为(6.6),(90\%)的节点可以在(8)跳之内到达。
参考
[1] http://web.stanford.edu/class/cs224w/
[2] Easley D, Kleinberg J. Networks, crowds, and markets: Reasoning about a highly connected world[M]. Cambridge university press, 2010.
[3] Barabási A L. Network science[J]. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 2013, 371(1987): 20120375.
[4] 《图论概念梳理》
Original: https://www.cnblogs.com/orion-orion/p/16850617.html
Author: orion-orion
Title: 图数据挖掘(二):网络的常见度量属性
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/804668/
转载文章受原作者版权保护。转载请注明原作者出处!