

1 导引
在上一篇博客《图数据挖掘:网络中的级联行为》中介绍了用基于决策的模型来对级联行为进行建模,该模型是基于效用(Utility)的且是是确定性的,主要关注于单个节点如何根据其邻居的情况来做决策,需要大量和数据相关的先验信息。这篇博客就让我们来介绍基于概率的传播模型,这种模型基于对数据的观测来构建,不过不能对因果性进行建模。
2 基于随机树的流行病模型
接下来我们介绍一种基于随机树的传染病模型,它是分支过程(branching processes)的一种变种。在这种模型中,一个病人可能接触(d)个其他人,对他们中的每一个都有概率(q>0)将其传染,如下图所示:
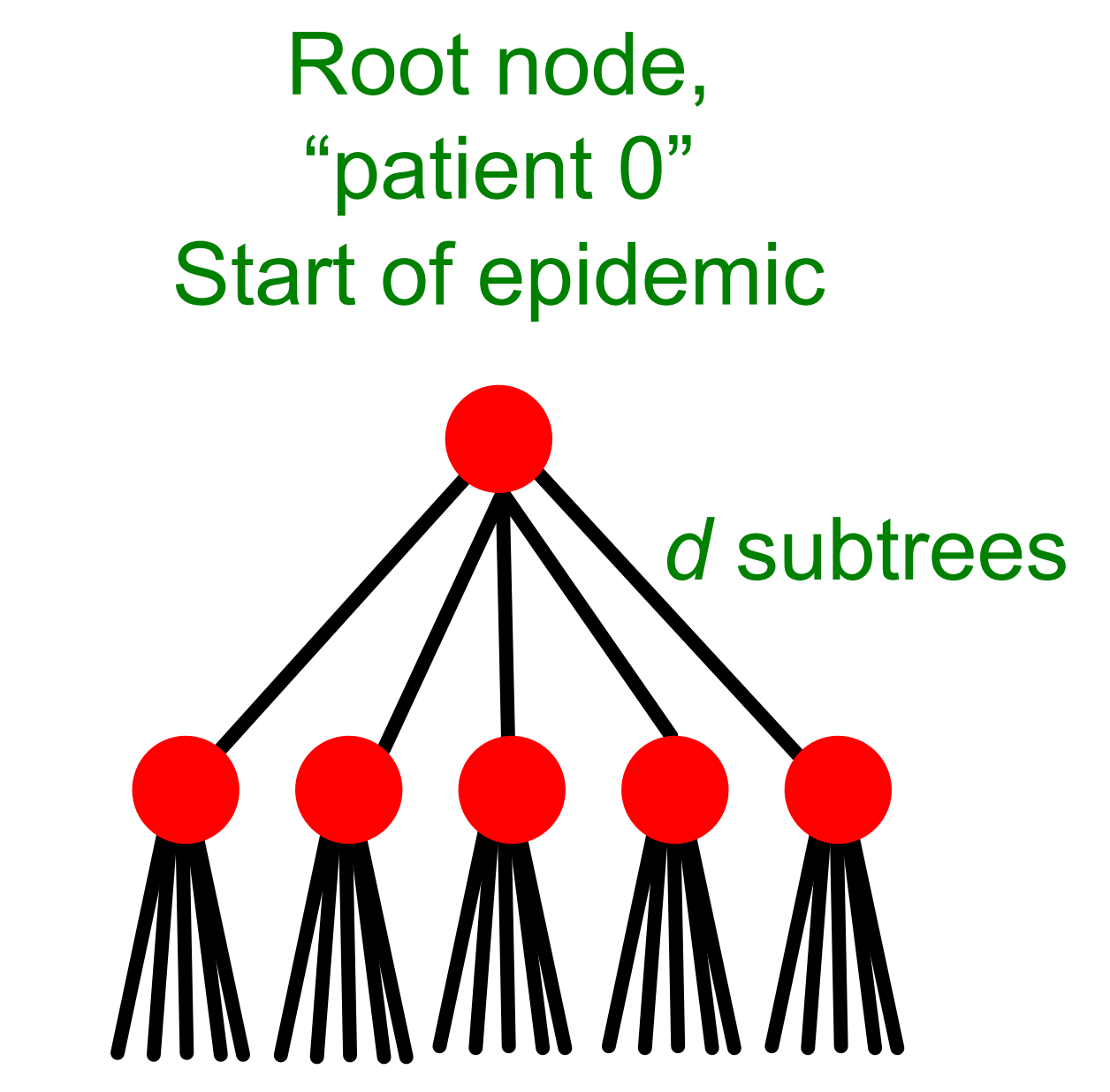

接下来我们来看当(d)和(q)取何值时,流行病最终会消失(die out),也即满足
[\lim _{h \rightarrow \infty} p_h=0 ]
这里(p_h)为在深度(h)处存在感染节点的概率(是关于(q)和(d)的函数)。如果流行病会永远流行下去,则上述极限应该(>0)。
(p_h)满足递归式:
[p_h=1-\left(1-q \cdot p_{h-1}\right)^d ]
这里(\left(1-q \cdot p_{h-1}\right)^d)表示在距离根节点(h)深度处没有感染节点的概率。
接下来我们通过对函数
[f(x)=1-(1-q \cdot x)^d ]
进行迭代来得到(\lim _{h \rightarrow \infty} p_h)。我们从根节点(x=1)(因为(p_1=1))开始,依次迭代得到(x_1=f(1), x_2=f(x_1),x_3=f(x_2))。事实上,该迭代最终会收敛到不动点(f(x)=x),如下图所示:
%E4%B8%8D%E5%8A%A8%E7%82%B9.png)
这里(x)是在深度(h-1)处存在感染节点的概率,(f(x))是在深度为(h)处存在感染节点的概率,(q)为感染概率,(d)为节点的度。
如果我们想要传染病最终消失,那么迭代(f(x))的结果必须要趋向于(0),也即不动点需要为0。而这也就意味着(f(x))必须要在(y=x)下方,如下所示:
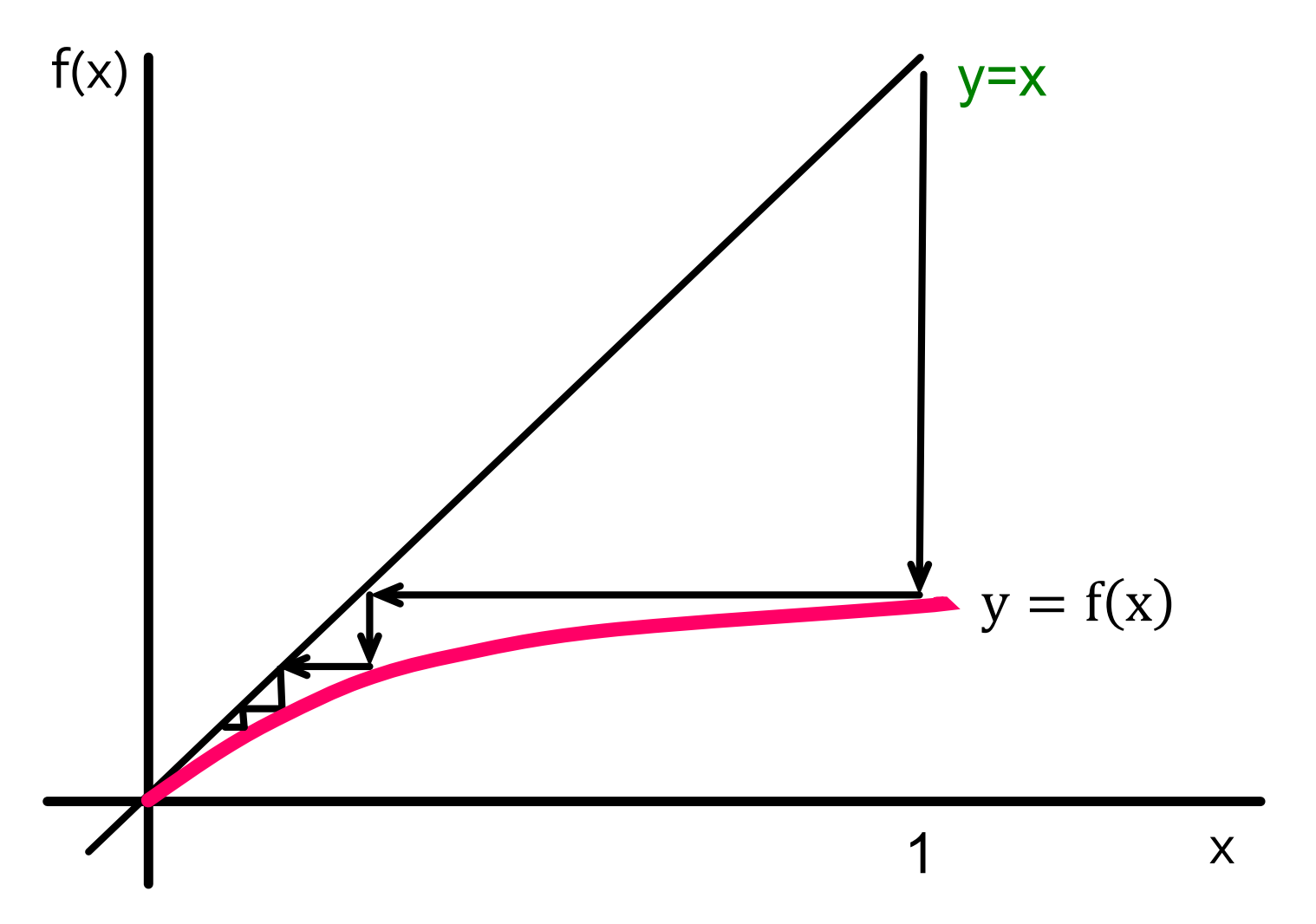
如何控制(f(x))必须要在(y=x)下方呢?我们先来分析下(f(x))的图像形状,我们有以下结论:
(f(x)) 是单调的:对(0 \leq x, q \leq 1, d>1),(f'(x)=q \cdot d(1-q x)^{d-1}>0),故(f(x))是单调的。
(f'(x)) 是非增的:(f'(x)=q \cdot d(1-q x)^{d-1})会着(x)减小而减小。
而(f(x))低于(y=x),则需要满足
[f'(0)=q\cdot d
Original: https://www.cnblogs.com/orion-orion/p/16859325.html
Author: orion-orion
Title: 图数据挖掘:基于概率的流行病模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/799339/
转载文章受原作者版权保护。转载请注明原作者出处!