

本文已收录到AndroidFamily ,技术和职场问题,请关注公众号 [彭旭锐] 提问。
前言
大家好,我是小彭。
在之前的文章里,我们聊到了 LRU 缓存淘汰算法,并且分析 Java 标准库中支持 LUR 算法的数据结构 LinkedHashMap。当时,我们使用 LinkedHashMap 实现了简单的 LRU Demo。今天,我们来分析一个 LRU 的应用案例 —— Android 标准库的 LruCache 内存缓存。
小彭的 Android 交流群 02 群已经建立啦,扫描文末二维码进入~
思维导图:
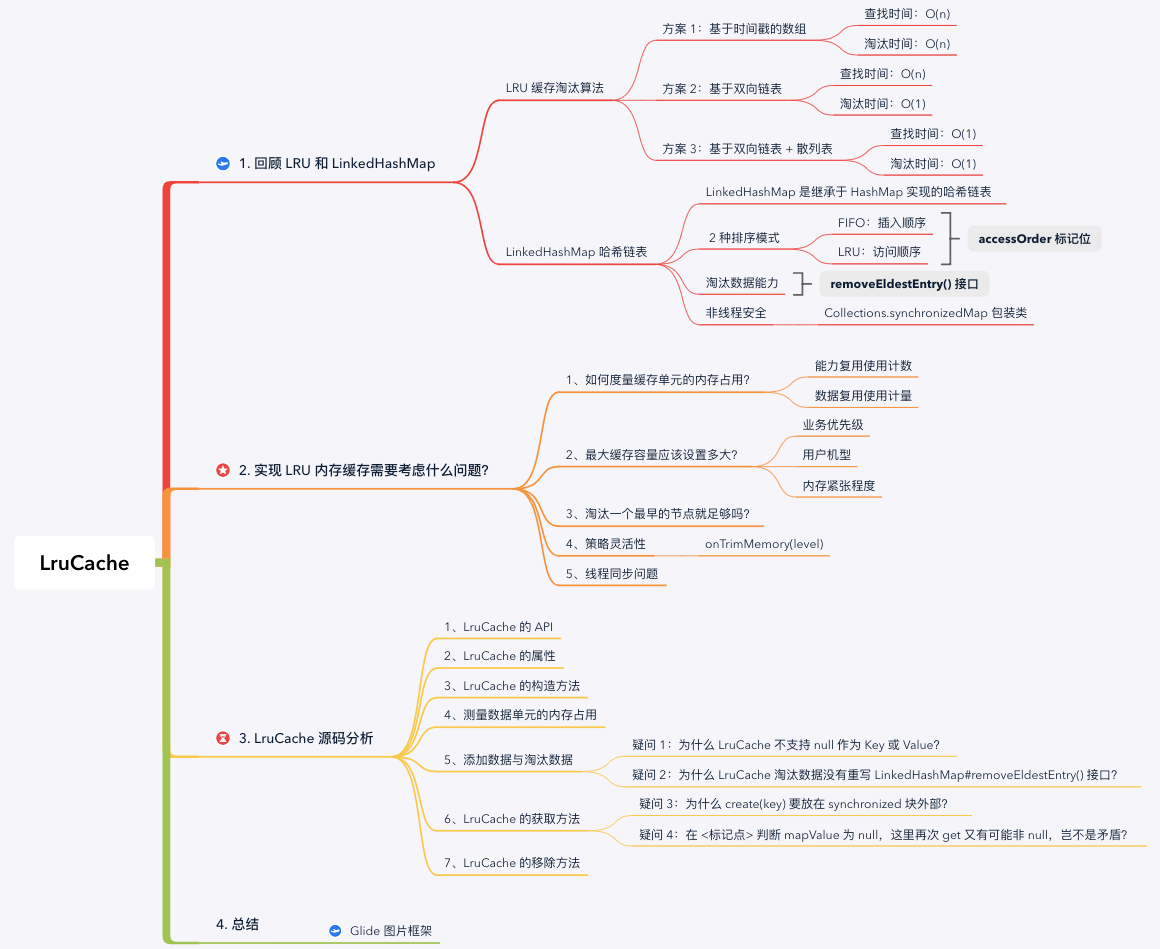

在具体分析 LruCache 的源码之前,我们先回顾上一篇文章中讨论的 LRU 缓存策略以及 LinkedHashMap 实现原理。
LRU (Least Recently Used)最近最少策略是最常用的缓存淘汰策略。LRU 策略会记录各个数据块的访问 “时间戳” ,最近最久未使用的数据最先被淘汰。与其他几种策略相比,LRU 策略利用了 “局部性原理”,平均缓存命中率更高。
FIFO 与 LRU 策略
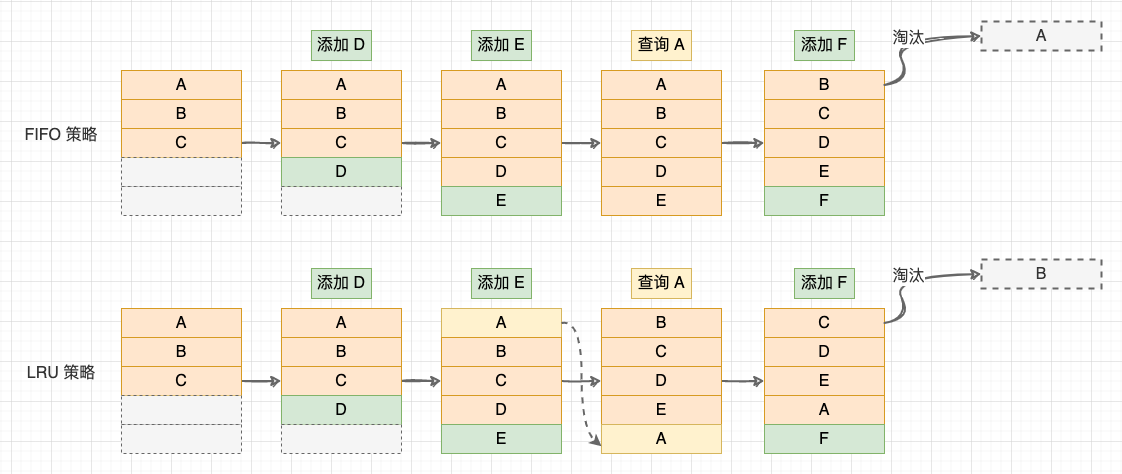
经过总结,我们可以定义一个缓存系统的基本操作:
- 操作 1 – 添加数据: 先查询数据是否存在,不存在则添加数据,存在则更新数据,并尝试淘汰数据;
- 操作 2 – 删除数据: 先查询数据是否存在,存在则删除数据;
- 操作 3 – 查询数据: 如果数据不存在则返回 null;
- 操作 4 – 淘汰数据: 添加数据时如果容量已满,则根据缓存淘汰策略一个数据。
我们发现,前 3 个操作都有 “查询” 操作,所以缓存系统的性能主要取决于查找数据和淘汰数据是否高效。为了实现高效的 LRU 缓存结构,我们会选择采用双向链表 + 散列表的数据结构,也叫 “哈希链表”,它能够将查询数据和淘汰数据的时间复杂度降低为 O(1)。
- 查询数据: 通过散列表定位数据,时间复杂度为 O(1);
- 淘汰数据: 直接淘汰链表尾节点,时间复杂度为 O(1)。
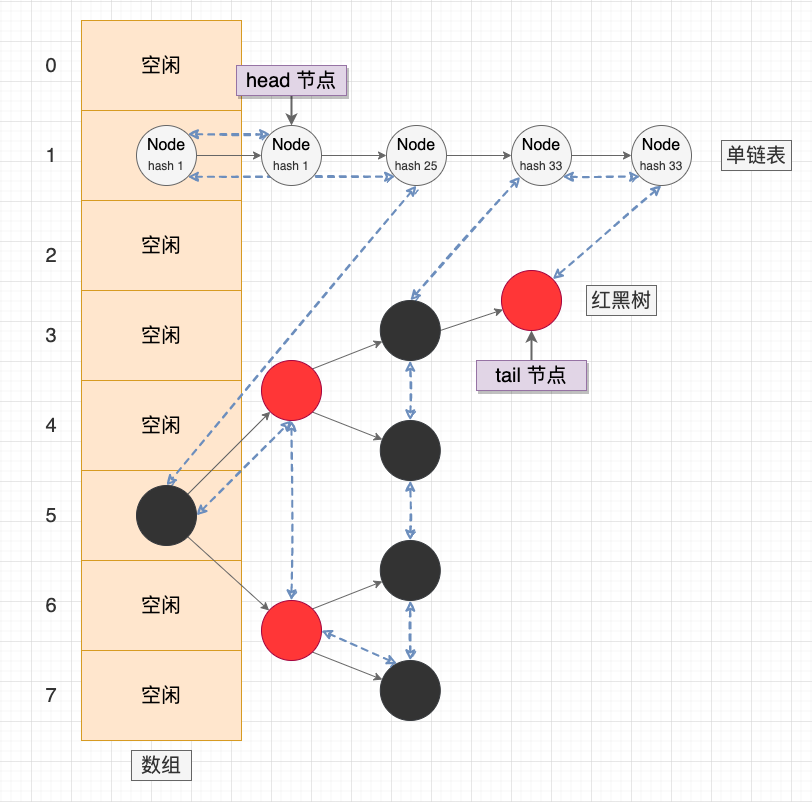
在 Java 标准库中,已经提供了一个通用的哈希链表 —— LinkedHashMap。使用 LinkedHashMap 时,主要关注 2 个 API:
accessOrder标记位: LinkedHashMap 同时实现了 FIFO 和 LRU 两种淘汰策略,默认为 FIFO 排序,可以使用 accessOrder 标记位修改排序模式。removeEldestEntry()接口: 每次添加数据时,LinkedHashMap 会回调 removeEldestEntry() 接口。开发者可以重写 removeEldestEntry() 接口决定是否移除最早的节点(在 FIFO 策略中是最早添加的节点,在 LRU 策略中是最久未访问的节点)。
LinkedHashMap 示意图
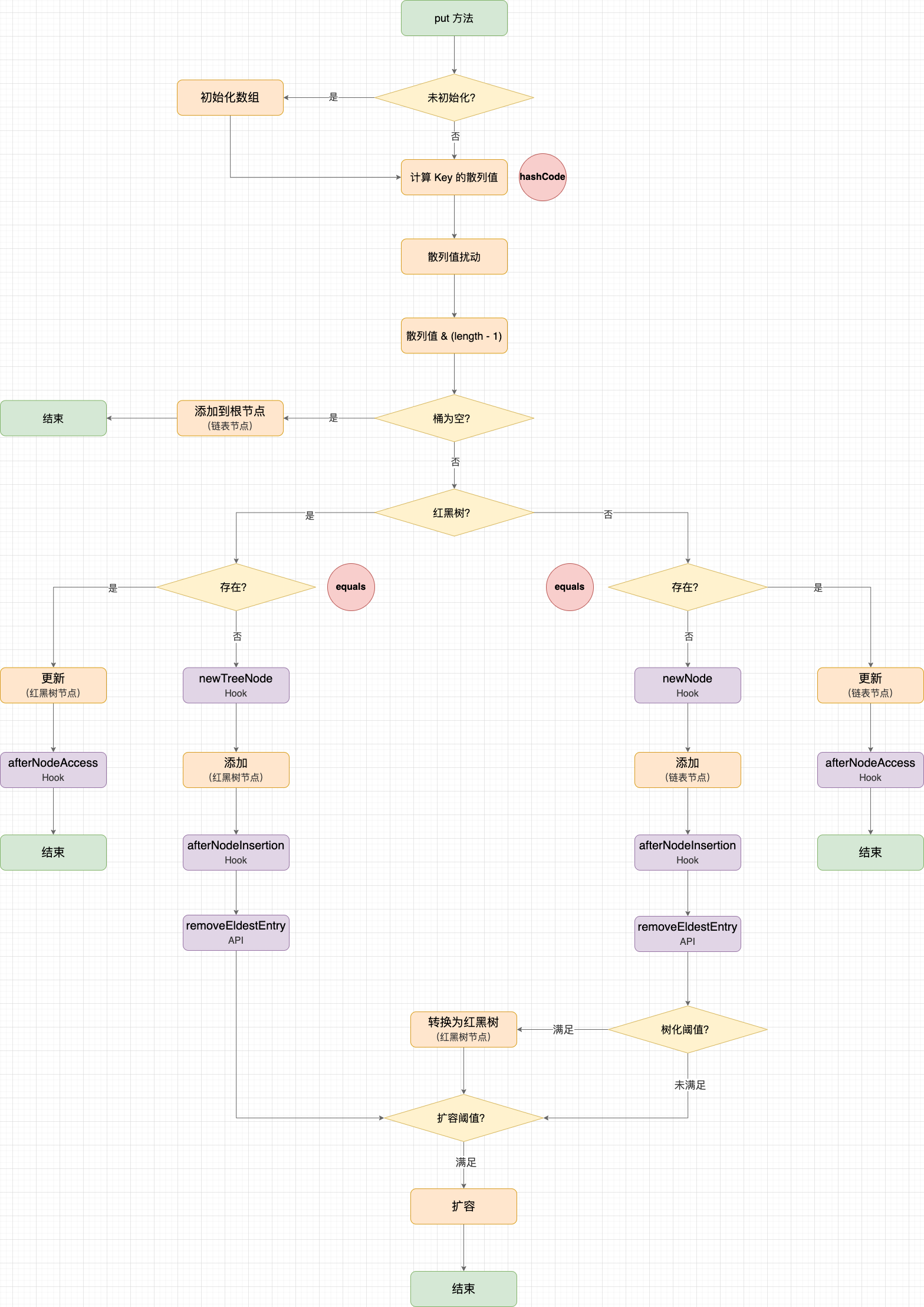
LinkedHashMap#put 示意图
2. 实现 LRU 内存缓存需要考虑什么问题?
在阅读 LruCache 源码之前,我们先尝试推导 LRU 内存缓存的实现思路,带着问题和结论去分析源码,也许收获会更多。
2.1 如何度量缓存单元的内存占用?
缓存系统应该实时记录当前的内存占用量,在添加数据时增加内存记录,在移除或替换数据时减少内存记录,这就涉及 “如何度量缓存单元的内存占用” 的问题。计数 or 计量,这是个问题。比如说:
- 举例 1: 实现图片内存缓存,如何度量一个图片资源的内存占用?
- 举例 2: 实现数据模型对象内存缓存,如何度量一个数据模型对象的内存占用?
- 举例 3: 实现资源内存预读,如何度量一个资源的内存占用?
我将这个问题总结为 2 种情况:
- 1、能力复用使用计数: 这类内存缓存场景主要是为了复用对象能力,对象本身持有的数据并不多,但是对象的结构却有可能非常复杂。而且,再加上引用复用的因素,很难统计对象实际的内存占用。因此,这类内存缓存场景应该使用计数,只统计缓存单元的个数,例如复用数据模型对象,资源预读等;
- 2、数据复用使用计量: 这类内存缓存场景主要是为了复用对象持有的数据,数据对内存的影响远远大于对象内存结构对内存的影响,是否度量除了数据外的部分内存对缓存几乎没有影响。因此, 这里内存缓存场景应该使用计量,不计算缓存单元的个数,而是计算缓存单元中主数据字段的内存占用量,例如图片的内存缓存就只记录 Bitmap 的像素数据内存占用。
还有一个问题,对象内存结构中的对象头和对齐空间需要计算在内吗?一般不考虑,因为在大部分业务开发场景中,相比于对象的实例数据,对象头和对齐空间的内存占用几乎可以忽略不计。
度量策略 举例 计数 1、Message 消息对象池:最多缓存 50 个对象
2、OkHttp 连接池:默认最多缓存 5 个空闲连接
3、数据库连接池 计量 1、图片内存缓存
2、位图池内存缓存
2.2 最大缓存容量应该设置多大?
网上很多资料都说使用最大可用堆内存的八分之一,这样笼统地设置方式显然并不合理。到底应该设置多大的空间没有绝对标准的做法,而是需要开发者根据具体的业务优先级、用户机型和系统实时的内存紧张程度做决定:
- 业务优先级: 如果是高优先级且使用频率很高的业务场景,那么最大缓存空间适当放大一些也是可以接受的,反之就要考虑适当缩小;
- 用户机型: 在最大可用堆内存较小的低端机型上,最大缓存空间应该适当缩小;
- 内存紧张程度: 在系统内存充足的时候,可以放大一些缓存空间获得更好的性能,当系统内存不足时再及时释放。
2.3 淘汰一个最早的节点就足够吗?
标准的 LRU 策略中,每次添加数据时最多只会淘汰一个数据,但在 LRU 内存缓存中,只淘汰一个数据单元往往并不够。例如在使用 “计量” 的内存图片缓存中,在加入一个大图片后,只淘汰一个图片数据有可能依然达不到最大缓存容量限制。
因此,在复用 LinkedHashMap 实现 LRU 内存缓存时,前文提到的 LinkedHashMap#removeEldestEntry() 淘汰判断接口可能就不够看了,因为它每次最多只能淘汰一个数据单元。这个问题,我们后文再看看 Android LruCache 是如何解决的。
2.4 策略灵活性
LruCache 的淘汰策略是在缓存容量满时淘汰,当缓存容量没有超过最大限制时就不会淘汰。除了这个策略之外,我们还可以增加一些辅助策略,例如在 Java 堆内存达到某个阈值后,对 LruCache 使用更加激进的清理策略。
在 Android Glide 图片框架中就有策略灵活性的体现:Glide 除了采用 LRU 策略淘汰最早的数据外,还会根据系统的内存紧张等级 onTrimMemory(level) 及时减少甚至清空 LruCache。
Glide · LruResourceCache.java
@Override
public void trimMemory(int level) {
if (level >= android.content.ComponentCallbacks2.TRIM_MEMORY_BACKGROUND) {
// Entering list of cached background apps
// Evict our entire bitmap cache
clearMemory();
} else if (level >= android.content.ComponentCallbacks2.TRIM_MEMORY_UI_HIDDEN || level == android.content.ComponentCallbacks2.TRIM_MEMORY_RUNNING_CRITICAL) {
// The app's UI is no longer visible, or app is in the foreground but system is running
// critically low on memory
// Evict oldest half of our bitmap cache
trimToSize(getMaxSize() / 2);
}
}
2.5 线程同步问题
一个缓存系统往往会在多线程环境中使用,而 LinkedHashMap 与 HashMap 都不考虑线程同步,也会存在线程安全问题。这个问题,我们后文再看看 Android LruCache 是如何解决的。
3. LruCache 源码分析
这一节,我们来分析 LruCache 中主要流程的源码。
3.1 LruCache 的 API
LruCache 是 Android 标准库提供的 LRU 内存缓存框架,基于 Java LinkedHashMap 实现,当缓存容量超过最大缓存容量限制时,会根据 LRU 策略淘汰最久未访问的缓存数据。
用一个表格整理 LruCache 的 API:
public API 描述 V get(K) 获取缓存数据 V put(K,V) 添加 / 更新缓存数据 V remove(K) 移除缓存数据 void evictAll() 淘汰所有缓存数据 void resize(int) 重新设置最大内存容量限制,并调用 trimToSize() void trimToSize(int) 淘汰最早数据直到满足最大容量限制 Map
3.2 LruCache 的属性
LruCache 的属性比较简单,除了多个用于数据统计的属性外,核心属性只有 3 个:
- 1、size: 当前缓存占用;
- 2、maxSize: 最大缓存容量;
- 3、map: 复用 LinkedHashMap 的 LRU 控制能力。
LruCache.java
public class LruCache {
// LRU 控制
private final LinkedHashMap map;
// 当前缓存占用
private int size;
// 最大缓存容量
private int maxSize;
// 以下属性用于数据统计
// 设置数据次数
private int putCount;
// 创建数据次数
private int createCount;
// 淘汰数据次数
private int evictionCount;
// 缓存命中次数
private int hitCount;
// 缓存未命中数
private int missCount;
}
3.3 LruCache 的构造方法
LruCache 只有 1 个构造方法。
由于缓存空间不可能设置无限大,所以开发者需要在构造方法中设置缓存的最大内存容量 maxSize。
LinkedHashMap 对象也会在 LruCache 的构造方法中创建,并且会设置 accessOrder 标记位为 true,表示使用 LRU 排序模式。
LruCache.java
// maxSize:缓存的最大内存容量
public LruCache(int maxSize) {
if (maxSize (0, 0.75f, true /*LRU 模式*/);
}
使用示例
private static final int CACHE_SIZE = 4 * 1024 * 1024; // 4Mib
LruCache bitmapCache = new LruCache(CACHE_SIZE);
3.4 测量数据单元的内存占用
开发者需要重写 LruCache#sizeOf() 测量缓存单元的内存占用量,否则缓存单元的大小默认视为 1,相当于 maxSize 表示的是最大缓存数量。
LruCache.java
// LruCache 内部使用
private int safeSizeOf(K key, V value) {
// 如果开发者重写的 sizeOf 返回负数,则抛出异常
int result = sizeOf(key, value);
if (result < 0) {
throw new IllegalStateException("Negative size: " + key + "=" + value);
}
return result;
}
// 测量缓存单元的内存占用
protected int sizeOf(K key, V value) {
// 默认为 1
return 1;
}
使用示例
private static final int CACHE_SIZE = 4 * 1024 * 1024; // 4Mib
LruCache bitmapCache = new LruCache(CACHE_SIZE){
// 重写 sizeOf 方法,用于测量 Bitmap 的内存占用
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getByteCount();
}
};
3.5 添加数据与淘汰数据
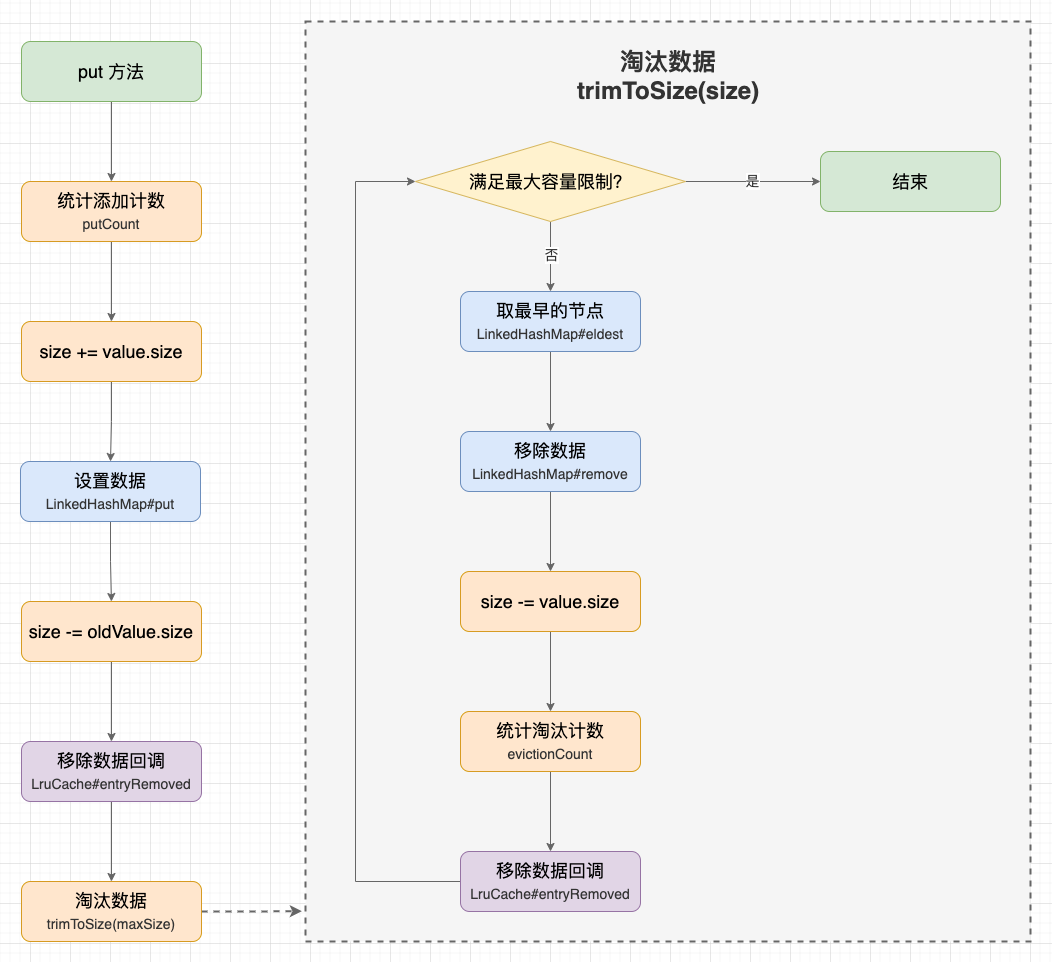
LruCache 添加数据的过程基本是复用 LinkedHashMap 的添加过程,我将过程概括为 6 步:
- 1、统计添加计数(putCount);
- 2、size 增加新 Value 内存占用;
- 3、设置数据(LinkedHashMap#put);
- 4、size 减去旧 Value 内存占用;
- 5、数据移除回调(LruCache#entryRemoved);
- 6、自动淘汰数据:在每次添加数据后,如果当前缓存空间超过了最大缓存容量限制,则会自动触发
trimToSize()淘汰一部分数据,直到满足限制。
淘汰数据的过程则是完全自定义,我将过程概括为 5 步:
- 1、取最找的数据(LinkedHashMap#eldest);
- 2、移除数据(LinkedHashMap#remove);
- 3、size 减去旧 Value 内存占用;
- 4、统计淘汰计数(evictionCount);
- 5、数据移除回调(LruCache#entryRemoved);
- 重复以上 5 步,满足要求或者缓存为空,才会退出。
逻辑很好理解,不过还是拦不住一些小朋友出来举手提问了 🙋🏻♀️:
- *🙋🏻♀️疑问 1:为什么 LruCache 不支持 null 作为 Key 或 Value?
其实并没有一定不能为 null 的理由,我的理解是 Google 希望降低 LruCache 的理解成本。如果允许 Value 为 null,那么当 LruCache 需要计算 Value 的 size 时,Value 为 null 默认应该当作 0 还是当作 1呢?
再者,如果业务开发确实有 Key 或 Value 的需求,也可以选择重写 LruCache 的相关方法,或者直接自实现一个 LruCache,这都是可以接受的方案。例如,在 Android Glide 图片框架中的 LruCache 就是自实现的。
- *🙋🏻♀️疑问 2:为什么 LruCache 淘汰数据没有重写
LinkedHashMap#removeEldestEntry()接口?
这个问题其实跟上一节的 “淘汰一个最早的节点就足够吗?” 问题相同。由于只淘汰一个数据后,有可能还不满足最大容量限制的要求,所以 LruCache 直接放弃了 LinkedHashMap#removeEldestEntry() 接口,而是自己实现了 trimToSize() 淘汰方法。
LinkedHashMap#eldest() 是 Android SDK 添加的方法,在 OpenJDK 中没有这个方法,这个方法会返回 LinkedHashMap 双向链表的头节点。由于我们使用的是 LRU 排序模式,所以头节点自然是 LRU 策略要淘汰的最久未访问的节点。
在 trimToSize() 方法中,会循环调用 LinkedHashMap#eldest() 取最早的节点,移除节点后再减去节点占用的内存大小。所以 trimToSize() 将淘汰数据的逻辑放在 while(true) 循环中,直到满足要求或者缓存为空,才会退出。
添加数据示意图
LruCache.java
public final V put(K key, V value) {
// 疑问 1:不支持 null 作为 Key 或 Value
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
// 被替换的数据
V previous;
synchronized (this) {
// 1、统计添加计数
putCount++;
// 2、增加新 Value 内存占用
size += safeSizeOf(key, value);
// 3、设置数据
previous = map.put(key, value);
// 4、减去旧 Value 内存占用
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
// 5、数据移除回调(previous -> value)
if (previous != null) {
entryRemoved(false /*非淘汰*/, key, previous, value);
}
// 6、自动淘汰数据
trimToSize(maxSize);
return previous;
}
// -> 6、自动淘汰数据
public void trimToSize(int maxSize) {
// 淘汰数据直到不超过最大容量限制
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
// 不超过最大容量限制,跳出
if (size toEvict = map.eldest();
// toEvict 为 null 说明没有更多数据
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
// 6.2 移除数据
map.remove(key);
// 6.3 减去旧 Value 内存占用
size -= safeSizeOf(key, value);
// 6.4 统计淘汰计数
evictionCount++;
}
// 6.5 数据移除回调(value -> null)
entryRemoved(true /*淘汰*/, key, value, null);
}
}
Android LinkedHashMap.java
// 提示:OpenJDK 中没有这个方法,是 Android SDK 添加的
public Map.Entry eldest() {
return head;
}
3.6 LruCache 的获取方法
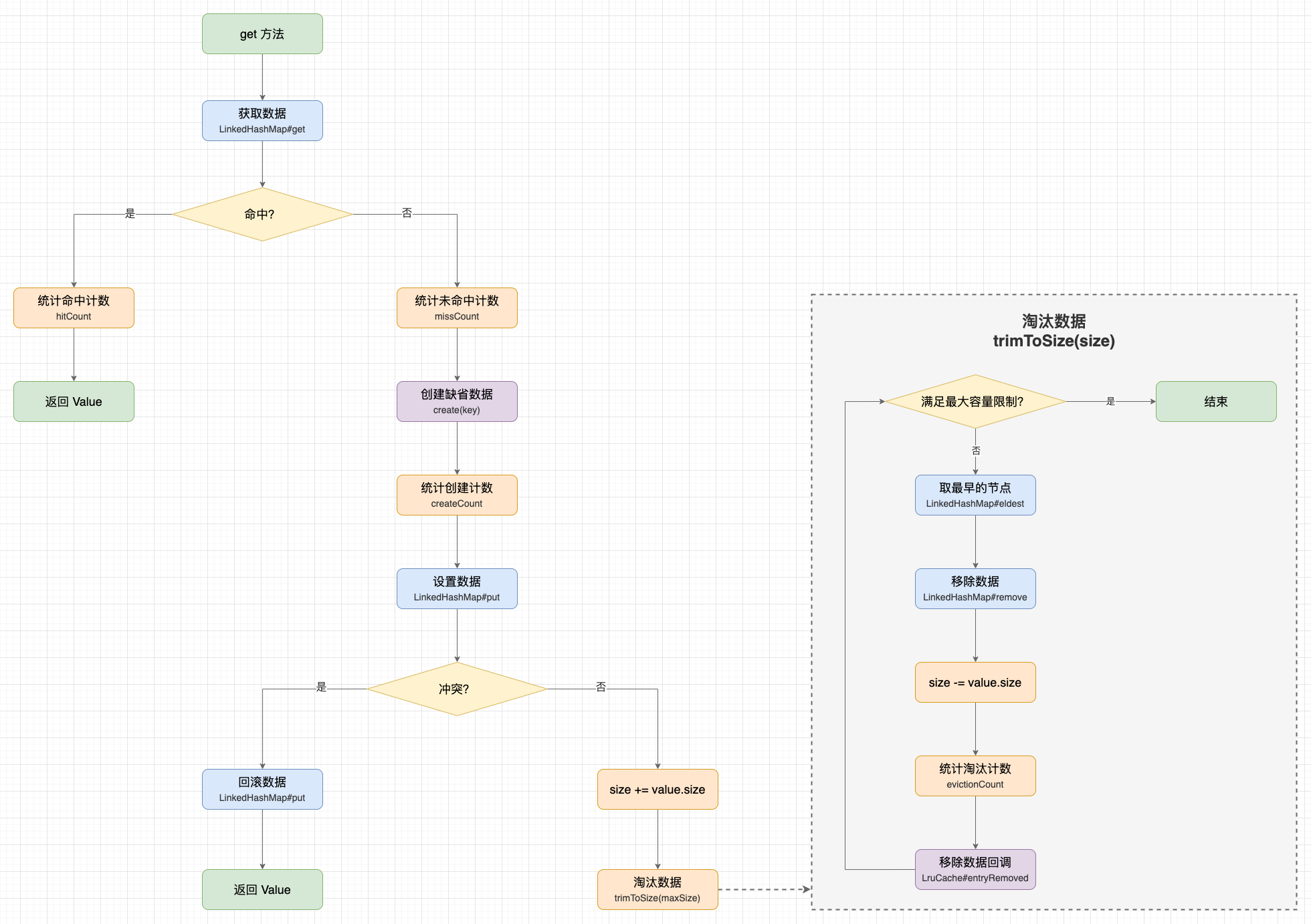
在获取数据时,LruCache 增加了自动创建数据的功能,区分 2 种 情况:
- 1、缓存命中: 直接返回缓存的数据;
- 2、缓存未命中: 调用
LruCache#create尝试创建数据,并将数据设置到缓存池中。这意味着 LruCache 不仅支持缓存数据,还支持创建数据。
public final V get(K key) {
// 不支持 null 作为 Key 或 Value
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
// 1. 尝试获取缓存的数据
// mapValue:旧数据
mapValue = map.get(key);
if (mapValue != null) { //
// 1.1 缓存命中计数
hitCount++;
// 1.2 缓存命中,返回缓存数据
return mapValue;
}
missCount++;
}
// 疑问 3:为什么 create(key) 要放在 synchronized 块外部?
// 2. 尝试自动创建缓存数据(类似对象池)
V createdValue = create(key);
if (createdValue == null) {
return null;
}
synchronized (this) {
// 3.1 创建数据计数
createCount++;
// 3.2 设置创建的缓存数据
// mapValue:旧数据
mapValue = map.put(key, createdValue);
// 疑问 4:在 判断 mapValue 为 null,这里再次 get 又有可能非 null,岂不是矛盾?
if (mapValue != null) {
// 3.3 如果 mapValue 旧数据不为 null,说明在调用 create() 的过程中,有其他线程创建并添加了数据
// 那么放弃创建的数据,将 mapValue 重新设置回去。由于另一个线程在设置时已经累加 size 内存占用,所以这里不用重复累加
map.put(key, mapValue);
} else {
// 3.4 如果 mapValue 旧数据为 null,那么累加 createdValue 的内存占用
size += safeSizeOf(key, createdValue);
}
}
// 4. 后处理
if (mapValue != null) {
// 4.1 数据移除回调(createdValue -> mapValue)
entryRemoved(false /*非淘汰*/, key, createdValue, mapValue);
return mapValue;
} else {
// 4.2 增加了 createdValue 后,需要缩容
trimToSize(maxSize);
return createdValue;
}
}
protected V create(K key) {
return null;
}
不出意外的话又有小朋友出来举手提问了 🙋🏻♀️:
- *🙋🏻♀️疑问 3:为什么 create(key) 要放在 synchronized 块外部?
这是为了降低锁的颗粒度。
由于 create(key) 创建数据的过程可能是耗时的,如果将 create(key) 放到 synchronized 同步块内部,那么在创建数据的过程中就会阻塞其他线程访问缓存的需求,会降低缓存系统的吞吐量。
- *🙋🏻♀️疑问 4:在
这个问题与上一个问题有关。
由于 create(key) 放在 synchronized 块外部,那么在执行 create(key) 的过程中,有可能其他线程已经创建并添加了目标数据,所以在 put(createdValue) 的时候就会出现 mapValue 不为 null 的情况。
此时,会存在两个 Value 的情况,应该选择哪一个 Value 呢?LruCache 认为其他线程添加的数据的优先级优于默认创建的缺省数据,所以在 3.3 分支放弃了缺省数据,重新将 mapValue 设置回去。
获取数据示意图
3.7 LruCache 的移除方法
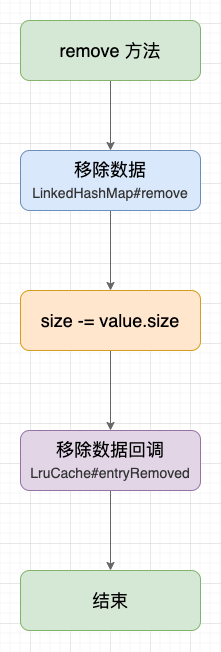
LruCache 的移除方法是添加方法的逆运算,过程我概括为 3 步:
- 1、移除节点(LinkedHashMap#remove);
- 2、size 减去 Value 的内存占用;
- 3、数据移除回调(LruCache#entryRemoved);
public final V remove(K key) {
// 不支持 null 作为 Key 或 Value
if (key == null) {
throw new NullPointerException("key == null");
}
V previous;
synchronized (this) {
// 1. 移除数据
previous = map.remove(key);
// 2. 减去移除 Value 内存占用
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
// 3. 数据移除回调(previous -> null)
if (previous != null) {
entryRemoved(false, key, previous, null);
}
return previous;
}
移除数据示意图
至此,LruCache 源码分析结束。
4. 总结
- 1、LruCache 是 Android 标准库提供的 LRU 内存缓存框架,基于 Java LinkedHashMap 实现,当缓存容量超过最大缓存容量限制时,会根据 LRU 策略淘汰最久未访问的缓存数据;
- 2、LruCache 需要重写
sizeOf()测量缓存单元的内存占用量,否则缓存单元的大小默认视为 1,相当于maxSize表示的是最大缓存数量; - 3、LruCache 放弃了
LinkedHashMap#removeEldestEntry()接口,而是自己实现了 trimToSize() 淘汰方法;
今天,我们讨论了 LRU 缓存淘汰策略和一些内存缓存的设计问题,并且分析了 Android LruCache 源码。在我们熟悉的 Glide 图片框架中,也深入使用了 LRU 内存缓存策略,你能说出它的设计原理吗。这个问题我们在下一篇文章讨论,请关注。
参考资料
- Android 开源框架源码鉴赏:LruCache 与 DiskLruCache —— 郭孝星 著
- LruCache 在美团 DSP 系统中的应用演进 —— 王粲 崔涛 霜霜(美团技术团队)著
- LruCache —— Android 官方文档
小彭的 Android 交流群 02 群

Original: https://www.cnblogs.com/pengxurui/p/16948336.html
Author: 彭旭锐
Title: Android 内存缓存框架 LruCache 的实现原理,手写试试?
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/797348/
转载文章受原作者版权保护。转载请注明原作者出处!