

一 背景介绍
GPT2模型是OpenAI组织在2018年于GPT模型的基础上发布的新预训练模型,其论文原文为 language_models_are_unsupervised_multitask_learners
GPT2模型的预训练语料库为超过40G的近8000万的网页文本数据,GPT2的预训练语料库相较于GPT而言增大了将近10倍。
二 GPT2与GPT 模型的区别
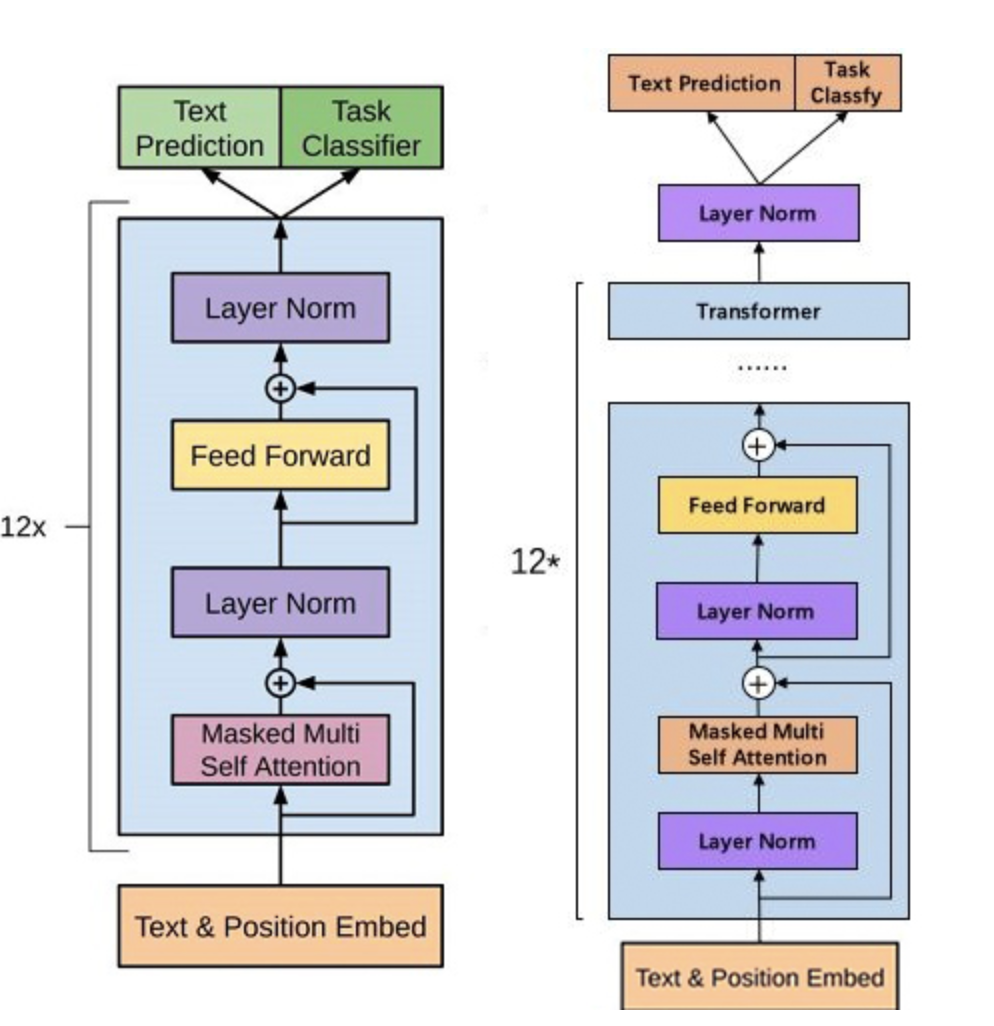

; 3 GPT2模型结构
GPT-2 模型由多层单向 Transformer 的解码器部分构成,本质上是自回归模型,自回归的意思是指,每次产生新单词后,将新单词加到原输入句后面,作为新的输入句。其中 Transformer 解码器结构如下图:
GPT-2 模型中只使用了多个 Masked Self-Attention 和 Feed Forward Neural Network 两个模块。
GPT-2 模型会将语句输入上图所示的结构中,预测下一个词,然后再将新单词加入,作为新的输入,继续预测。损失函数会计算预测值与实际值之间的偏差。
从上一节我们了解到 BERT 是基于双向 Transformer 结构构建,而 GPT-2 是基于单向 Transformer,这里的双向与单向,是指在进行注意力计算时,BERT会同时考虑被遮蔽词左右的词对其的影响,而 GPT-2 只会考虑在待预测词位置左侧的词对待预测词的影响。
通过上述数据预处理方法和模型结构,以及大量的数据训练出了 GPT-2 模型。OpenAI 团队由于安全考虑,没有开源全部训练参数,而是提供了小型的预训练模型,接下来我们将在 GPT-2 预训练模型的基础上进行。
4 使用GPT生成文本
预训练模型生成新闻
直接运行一个预训练好的 GPT-2 模型:给定一个预定好的起始单词,然后让它自行地随机生成后续的文本。
问题1:重复性问题。重复生成同一个单词。
解决方式1:从概率前 k 大的单词中随机选取一个单词,作为下一个单词。
问题2:逻辑问题
解决方式:未知。知识??
import random
import logging
logging.basicConfig(level=logging.INFO)
import torch
from pytorch_transformers import GPT2Tokenizer
from pytorch_transformers import GPT2LMHeadModel
def select_top_k(predictions, k=10):
predicted_index = random.choice(
predictions[0, -1, :].sort(descending=True)[1][:10]).item()
return predicted_index
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
text = "Yesterday, a man named Jack said he saw an alien,"
indexed_tokens = tokenizer.encode(text)
tokens_tensor = torch.tensor([indexed_tokens])
tokens_tensor.shape
model = GPT2LMHeadModel.from_pretrained("./")
model.eval()
total_predicted_text = text
n = 100
for _ in range(n):
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
predicted_index = select_top_k(predictions, k=10)
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
total_predicted_text += tokenizer.decode(predicted_index)
if '' in total_predicted_text:
break
indexed_tokens += [predicted_index]
tokens_tensor = torch.tensor([indexed_tokens])
print(total_predicted_text)
微调生成风格文本
接下来,我们将使用一些戏剧剧本对 GPT-2 进行微调。由于 OpenAI 团队开源的 GPT-2 模型预训练参数为使用英文数据集预训练后得到的,虽然可以在微调时使用中文数据集,但需要大量数据和时间才会有好的效果,所以这里我们使用了英文数据集进行微调,从而更好地展现 GPT-2 模型的能力。首先,下载训练数据集,这里使用了莎士比亚的戏剧作品《罗密欧与朱丽叶》作为训练样本。
数据集已经提前下载好并放在云盘中,
链接:https://pan.baidu.com/s/1LiTgiake1KC8qptjRncJ5w 提取码:km06
with open('./romeo_and_juliet.txt', 'r') as f:
dataset = f.read()
indexed_text = tokenizer.encode(dataset)
del(dataset)
dataset_cut = []
for i in range(len(indexed_text)//512):
dataset_cut.append(indexed_text[i*512:i*512+512])
del(indexed_text)
dataset_tensor = torch.tensor(dataset_cut)
dataset_tensor.shape
from torch.utils.data import DataLoader, TensorDataset
train_set = TensorDataset(dataset_tensor,
dataset_tensor)
train_loader = DataLoader(dataset=train_set,
batch_size=2,
shuffle=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
from torch import nn
from torch.autograd import Variable
import time
pre = time.time()
epoch = 30
model.to(device)
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
for i in range(epoch):
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(
target).to(device)
optimizer.zero_grad()
loss, logits, _ = model(data, labels=target)
total_loss += loss
loss.backward()
optimizer.step()
if batch_idx == len(train_loader)-1:
print('average loss:', total_loss/len(train_loader))
print('训练时间:', time.time()-pre)
text = "From fairest creatures we desire"
indexed_tokens = tokenizer.encode(text)
tokens_tensor = torch.tensor([indexed_tokens])
model.eval()
total_predicted_text = text
for _ in range(500):
tokens_tensor = tokens_tensor.to('cuda')
with torch.no_grad():
outputs = model(tokens_tensor)
predictions = outputs[0]
predicted_index = select_top_k(predictions, k=10)
predicted_text = tokenizer.decode(indexed_tokens + [predicted_index])
total_predicted_text += tokenizer.decode(predicted_index)
if '' in total_predicted_text:
break
indexed_tokens += [predicted_index]
if len(indexed_tokens) > 1023:
indexed_tokens = indexed_tokens[-1023:]
tokens_tensor = torch.tensor([indexed_tokens])
print(total_predicted_text)
5 GPT-2从finetune 到部署
用到的训练数据是我从网上爬下来的老友记十季的剧本:
https://pan.baidu.com/share/init?surl=blbeVCro1nErh34KUGrPIA
提取码: 40bn如何用nshepperd 的 gpt-2 库来 finetune 模型
步骤一: 下载项目:git clone https://github.com/nshepperd/gpt-2
步骤二: 安装所需环境:pip install -r requirements.txt
步骤三: 准备模型:python download_model.py 345M
步骤四: 准备数据。放到/data目录下
步骤五: finetune【根据机器训练速度会不同,但基本上两三千步就能看到些还算不错的结果了】如想要 finetune 时更快些的话,可以预编码数据成训练格式。
PYTHONPATH=src ./encode.py data/friends.txt data/friends.txt.npz
PYTHONPATH=src ./train.py –dataset data/friends.txt.npz –model_name 345M
其他值得关注参数:
learning_rate: 学习率,默认2e-5,可根据数据集大小适当调整,数据集大的话可以调大些,小的话可以调小些。
sample_every: 每多少步生成一个样本看看效果,默认 100。
run_name: 当前训练命名,分别在samples和checkpoint文件夹下创建当前命名的子文件夹,之后生成的样本和保存的模型分别保存在这两个子文件夹。训练中断想继续训练就可以用同样的run_name,如想跑不同任务请指定不同run_name.
步骤六: 存储模型:将生成的模型,更改名字,放入models文件夹里,替换掉原来的模型(一定要记得将之前的模型备份!)。
步骤七: 生成样本:
自由生成 python src/generate_unconditional_samples.py –top_k 40 –temperature 0.9 –model_name 345M
然后是 命题作文,有条件互动生成环节。
python src/interactive_conditional_samples.py –top_k 40 –temperature 0.9 –model_name 345M
运行后会出现一个互动框,输入你想让模型续写的话,给定输入:Rachel loves Andy
在 Rachel loves Andy 两秒后,完美跑题,伤心,不过感觉后半段还是很有意思。
关于参数 –topk 还有 –temperature,会影响生成的效果,可自己尝试调节一下,上面例子使用的是两个推荐设定。
到此 finetune 一个基本 GPT-2 的过程就完了,是不是比想象中要简单很多。
import gpt_2_simple as gpt2
gpt2.download_gpt2(model_name="345M")
sess = gpt2.start_tf_sess()
gpt2.finetune(sess,
dataset="friends.txt",
model_name='345M',
steps=1000,
restore_from='fresh',
print_every=10,
sample_every=200,
save_every=500
)
sess = gpt2.start_tf_sess()
gpt2.load_gpt2(sess)
gpt2.generate(sess)
flask 部署
步骤一:提供模型到models/ 下(Huggingface 的 pytorch 格式)。
命名为gpt2-pytorch_model.bin
也可以先用它提供的实例模型来做个实验:
mkdir models
curl –output models/gpt2-pytorch_model.bin https://s3.amazonaws.com/models.huggingface.co/bert/gpt2-pytorch_model.bin
步骤二:得到访问端口:python deployment/run_server.py.
步骤三:直接用浏览器访问就行了,如果是远程访问把 0.0.0.0 改成服务器IP就好了。
如何部署自己的模型
步骤一:将 tensorflow 的模型转换成 Pytorch 的模型。
这里可以用 Huggingface 的pytorch-pretrained-BERT 库里面的转换脚本,先根据指示安装库,之后运行以下脚本。export GPT2_DIR=模型所在文件夹
pytorch_pretrained_bert convert_gpt2_checkpoint $GPT2_DIR/model_name output_dir/ path_to_config/config.json
上面命令 convert_gpt2_checkpoint 后三个参数分别是,输入的 tensorflow 模型路径,转换输出的 pytorch 模型路径,模型的配置参数文件。需要注意的是,因为这几个库之间的不统一,所以下载下来 345M 模型的设置文件在转换时会出错,需要添加一些参数。前面有下载 345M 模型的话,会发现模型文件夹下有一个设置文件 hparams.json。
cp hparams.json hparams_convert.json #复制一份来修改
之后在 hparams_convert.json里添加几个参数,改成下面这样:
{
“n_vocab”: 50257,
“n_ctx”: 1024,
“n_embd”: 1024,
“n_head”: 16,
“n_layer”: 24,
“vocab_size”:50257,
“n_positions”:1024,
“layer_norm_epsilon”:1e-5,
“initializer_range”: 0.02
}
将这个设置文件指定到转换命令convert_gpt2_checkpoint后面相应参数去。
获得转换模型后,把它放入models/ 中去,并且重命名,之后把 deployment/GPT2/config.py 里面的参数设定改成再改成 345M 大模型的参数就好了。class GPT2Config(object):
def init(
self,
vocab_size_or_config_json_file=50257,
n_positions=1024,
n_ctx=1024,
n_embd=1024,
n_layer=24,
n_head=16,
layer_norm_epsilon=1e-5,
initializer_range=0.02,
):
最后运行 run_server.py,成功载入模型,部署完成!之后测试一下,发现确实是已经 finetune 好的老友记模型。
参考:
GPT2 代码解释: GPT2LMHeadModel类、GPT2Model类、Block类、MLP类与Attention类
GPT-2 进行文本生成
AI界最危险武器 GPT-2 使用指南:从Finetune到部署
Original: https://blog.csdn.net/weixin_36378508/article/details/121809595
Author: zhurui_xiaozhuzaizai
Title: GPT2模型详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/795425/
转载文章受原作者版权保护。转载请注明原作者出处!