

论文地址:2022-CVPR-YOLO-FaceV2: A Scale and Occlusion Aware Face Detector
论文代码:https://github.com/Krasjet-Yu/YOLO-FaceV2
Abstract
- 现有目标(人脸)检测算法已取得很大的进展,如BlazeFace、RetinaFace、RCNN系列、YOLO系列等;
- 这些算法可以被分为两大类: 两阶段的(RCNN系列)和 单阶段的(YOLO系列);
- 本文基于单阶段的yolov5提出了一个实时的face detector:YOLO-FaceV2;
- 主要改进的部分有以下几方面:
(1)设计了一个被称为 RFE(receptive field enhancement module) 的感受野增强模块来增强小脸的感受野;
(2)利用 NWD loss来弥补IoU对微小物体位置偏差的敏感性;
(3)针对人脸遮挡问题,提出了一种名为 SEAM的注意模块,并引入 排斥损失(Repulsion Loss)来解决;
(4)还利用权重函数 Slide来解决易样本和难样本之间的不平衡,并利用有效接受野的信息来设计锚。
5.最后通过实验证明yolofacev2性能好。
1 Introduction
通过仔细分析现有人脸检测算法遇到的困难和yolov5检测算法的缺陷,本文从 以下几方面进行改进:
- 多尺度融合:RFE;
- 注意力机制:SEAM;
- 难样例:Slide 权重函数;
- 锚点设计:设计多个锚框的比例;
- *回归损失:NWD(Normalized Wasserstein Distance)与IoU以不同的权重进行结合;
本文的主要贡献如下:
- 为了检测多尺度的人脸,感受野和分辨率是关键因素。因此,在本文中设计了 RFE模块(receptive field enhancement module)以学习特征图的不同接受域,并进行增强特征金字塔表示;
- 本文中将人脸遮挡(face occlusions)分为两大类:不同人脸之间的遮挡与其他物体对人脸的遮挡。前者使用排斥损失 Repulsion Loss惩罚预测框转移到其他真实对象,要求每个预测框远离其他具有不同指定目标的预测框,以降低检测结果对NMS的敏感性。后者使用 SEAM注意力机制以增强面部特征学习能力。
- 为了解决难易样例间的不平衡问题,根据IoU以对不同的样例进行加权,主要使用的方式是 Slide权重函数;
3 YOLO-FaceV2
3.1 Network Architecture
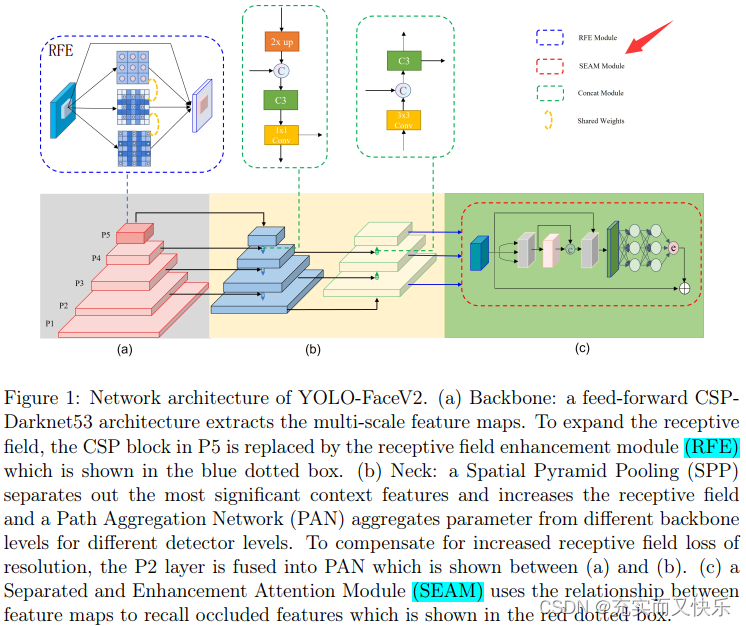

YOLOFaceV2主要由3部分构成:backbone [ CSPDarknet53 ]、neck [ SPP、PAN ]、heads。(与yolov5、yolov5face基本一致。)
【
SPP:单独的P3、P4、P5模块;
PAN:P3、P4、P5等进行整合的操作;细节参考:(https://www.cnblogs.com/AIBigTruth/p/15100810.html)
】
; 3.2 Scale-Aware RFE Model
不同的接收域大小意味着捕获远程依赖的能力不同。
在RFE中主要使用的是dilated conv。并使用不同比列的膨胀卷积进行不同卷积操作,即:
使用4种不同比例的扩展卷积分支来捕获多尺度信息和不同的依赖范围,且这些分支间权值共享,唯一的不同就是接受域不同。
且此方式的好处是:
- 减少了模型参数,同时减少潜在的overfitting风险;
- 可以充分利用每个样例。(主要是因为可以进行不同尺寸的操作~)。
RFE模块主要由两部分构成:基于膨胀(扩张)卷积的多分支和 gathering&weighting layer。具体如下图:
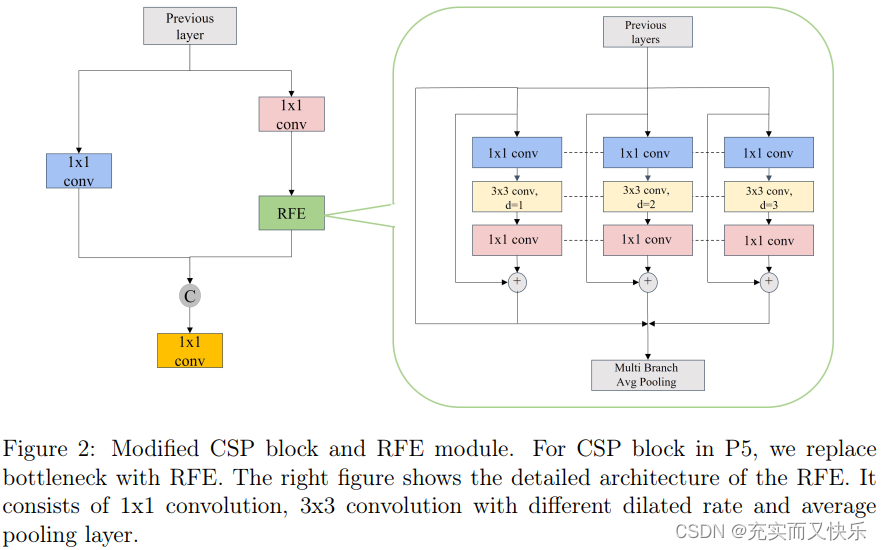
其中多分支主要是通过设置不同比列的膨胀卷积来实现的;收集和加权层(gathering and weighting layer)用于从不同的分支收集信息,并对特征的每个分支进行加权。
4 Experiments
在本章,主要对所提出的方法进行了全面的消融,包括 注意模块、 多尺度融合金字塔结构和 损失函数设计的有效性。最后与其他SOTA人脸检测器的性能进行了比较。
4.1 Dataset
WiderFace:由超过400K张人脸的33203张图像构成。其包含训练(40%)、测试(50%)与验证(10%)三部分;根据困难程度,WidefFace又可被分为三部分:easy、medium和hard。
4.2 Training
- 与yolov5face一样同样使用yolov5作为baseline;
- optimizer使用的是:SGD;初始学习率:1e-2;最终学习率1e-3;权重缩减:5e-3;前3轮进行warming-up,且仅在该情况下的动量参数为0.8,其他情况下动量参数为0.937;
- IoU阈值为0.5;
- 硬件资源:1080ti,4核;
- 以batch size为16的情况下迭代100次进行微调。
4.3 Ablation Study
4.3.1 SEMA Block
SEAM块是注意网络。通过使用该块,以通过增强未遮挡人脸的响应来弥补被遮挡人脸的响应损失。[实验性能对应下表:Table2中第2行~]
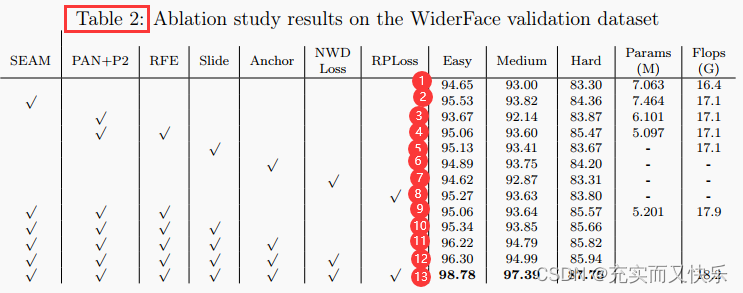
(上表中序号为对应的行数)
; 4.3.2 Multi-scale feature fusion
(1)在PAN的基础上融合P2层特征,以使得融合得到的特征图中包含更多小目标信息;[实验性能参考上表:Table2中第3行~]
(2)为了弥补颈部层(neck layer)输出特征图接受域有限,导致大中型目标检测精度下降的不足,使用了RFE模块;[实验性能如上表:Table2中第4行]
4.3.3 Slide Loss
使用Slide Loss的主要目标是:使得模型更加关注hard样例;[对应实现性能如上表:Table2中第5行]
4.3.4 Anchor Design
锚的比例和大小与有效感受野密切相关。[…第6行]
4.3.5 NWD Loss
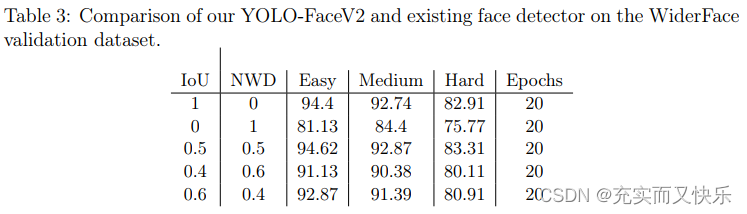
首先使用NWD Loss替换IoU作为回归损失,但是性能并未提高。
因此选择保留IoU Loss,通过调整IoU Loss和MWD Loss之间的比例关系来提高模型对小目标检测的鲁棒性。因为实验结果表明,对于大中型目标,测量的效果IoU优于NWD, NWD可以有效提高小目标的检测精度。具体实验结果如下表(Table3):
; 4.3.6 Balance of RepGT and RepBpx
受行人遮挡问题的解决方案启发,作者在人脸检测中加入了排斥损失函数(Repulsion Loss),并分析了不同的人脸遮挡阈值,使该损失函数适用于人脸检测。[实验结果参考Table2中第8行。]
4.4 Comparisons with Existing Face Dectors
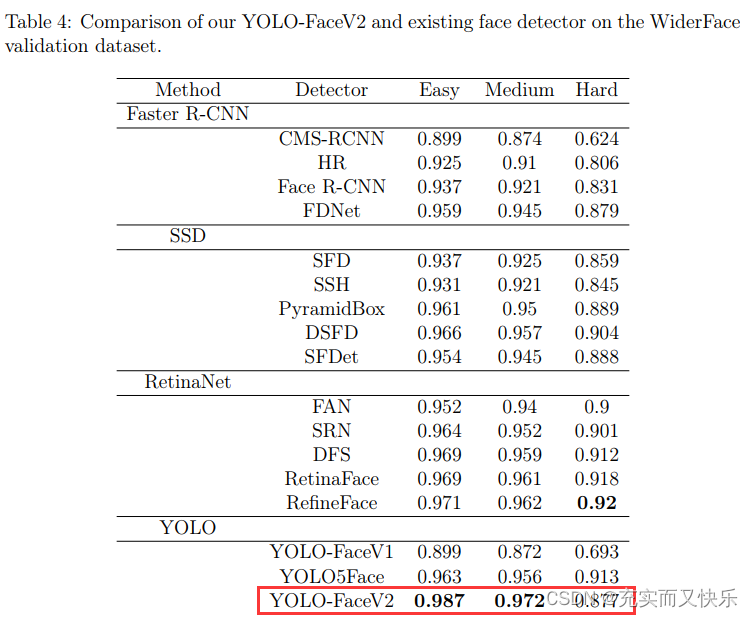
; 5 Conclusion
- 本文基于yolov5提出了yolofacev2,旨在解决人脸尺度变化(多尺度问题)、难易样本不平衡、面部遮挡等问题;
- 将P2层融合到特征金字塔中以提高小目标的分辨率,设计RFE模块以增强接受域,并使用NWD Loss来提高模型对小目标检测的鲁棒性;(多尺度问题)
- 引入Slide权值函数来缓解简单样例和难检测样例的不平衡;(数据不平衡)
- 使用SEMA模块和Repulsion Loss解决面部遮挡问题;(面部遮挡)
- 最终yolofacev2在widerface数据集上实现了接近或超过SOTA的性能。
模型训练

Original: https://blog.csdn.net/weixin_41807182/article/details/127519652
Author: 充实而又快乐
Title: YOLOFaceV2笔记
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/795032/
转载文章受原作者版权保护。转载请注明原作者出处!