

目录
一、实验内容
- 理解损失函数的基本概念;
- 理解并掌握均方差损失函数的原理,算法实现及代码测试分析;
- 理解并掌握交叉熵损失函数的基本原理,代码实现并测试分析;
- 理解均方差与交叉熵损失函数的区别。
二、实验过程
1、算法思想
简单的理解就是每一个样本经过模型后会得到一个预测值,然后得到的预测值和真实值的差值就成为损失。损失值越小证明模型越是成功。
2、算法原理
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。 不同的模型用的损失函数一般也不一样。
损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数指经验风险损失函数加上正则项。
均方差损失函数


交叉熵损失
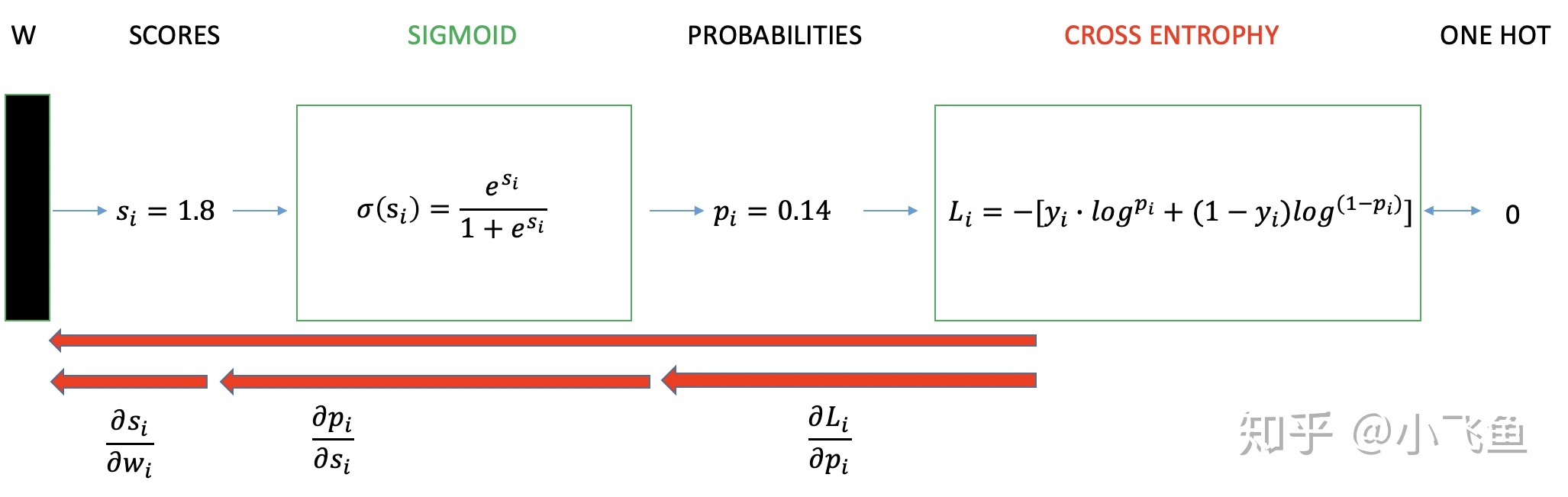
3、算法分析
损失函数使用步骤
- 用随机值初始化前向计算公式的参数。
- 代入样本,计算输出的预测值。
- 用损失函数计算预测值和标签值(真实值)的误差。
- 根据损失函数的导数,沿梯度最小方向将误差回传,修正前向计算公式中的各个权重值。
- 重复步骤2,直到损失函数到达一个满意的值就停止迭代。
三、源程序代码
均方差损失函数:
def MSE (y, y_predicted):
sq_error = (y_predicted - y) ** 2
sum_sq_error = np.sum(sq_error)
mse = sum_sq_error/y.size
return mse
交叉熵损失函数:
import math
def softmax(x):
m, n = len(x), len(x[0])
for i in range(m):
cur_m = max(x[i])
for j in range(n):
x[i][j] = math.exp(x[i][j] - cur_m)
cur_s = sum(x[i])
for j in range(n):
x[i][j] = x[i][j] / cur_s
return x
def crossentropy(y_hat, y):
# y_hat: [N, C]
# y: [N]
loss = 0
batch_size = len(y)
y_softmax = softmax(y_hat)
for i in range(batch_size):
loss -= math.log(y_softmax[i][y[i]])
return loss
x = [[0.1, 0.2, 0.7], [0.5, 0.2, 0.3]]
y = [2, 0]
print(crossentropy(x, y))
四、运行结果分析
交叉熵损失函数计算得出损失值

五、实验总结
均方差函数常用于线性回归计算预测值和真实值之间的欧式距离。 预测值和真实值越接近,两者的均方差就越小。
交叉熵误差是一个-log函数,也就意味着,交叉熵误差值越小,神经网络在对应正确解标签的输出越接近 1 ,即神经网络的判断和正确解标签越接近。
Original: https://blog.csdn.net/qq_50942093/article/details/128007052
Author: 谭盐.
Title: 损失函数——机器学习
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/794760/
转载文章受原作者版权保护。转载请注明原作者出处!