

人工智能核心技术:机器学习总览


机器学习作为 人工智能的核心,与 计算机视觉、自然语言处理、语音处理和知识图谱密切关联

机器学习是实现人工智能的核心方法,专门研究计算机如何模拟/实现生物体的学习行为,获取新的知识技能,利用经验来改善特定算法的性能。深度学习是机器学习算法的一种,深度学习算法具有多层神经网络结构,其在图像识别、语音处理等领域取得划时代的成果。
根据学习范式的不同,机器学习可划分为有监督学习、无监督学习、强化学习。
机器学习分类—有监督学习
有监督学习:从有标注训练数据中推导出预测函数
有监督学习(Supervised Learning):属于机器学习任务的一种类型,其主要是从给定的训练数据集中学习出一个函数(模型参数),当新的数据到来时,可以根据该函数预测结果。


1.1有监督学习—逻辑回归
逻辑回归:对事件发生或不发生进行二元分类
逻辑回归(Logistic Regression,LR):是指学习某事件发生概率的算法,可对某个事件发生/不发生进行二元分类。逻辑回归使用Sigmoid函数,输出结果范围在[0,1]之间,逻辑回归的目标是发现特征与特定结果可能性之间的联系。
如下示例:根据学习时长预测学生是否通过考试,响应变量为”通过和未通过考试”。

1.2有监督学习—支持向量机
支持向量机:以间隔最大化为基准学习远离数据的决策边界
支持向量机(Support Vector Machine,SVM):主要是以间隔最大化为基准,学习得到尽可能远离数据的决策边界算法,支持向量是确定决策边界的重要数据。

1.3有监督学习—决策树
决策树:以 树结构形式表达的 预测分析模型
决策树(Decision Tree): 是一种树状结构,通过做出一系列决策(选择)来对数据进行划分,这类似于针对一系列问题进行选择。一棵决策树一般包含一个根结点、若干个内部结点和若干个叶结点,其中每个内部结点表示一个属性上的测试,每个分支代表一个测试输出,每个叶结点代表一种类别。 决策树生成是一个递归过程。
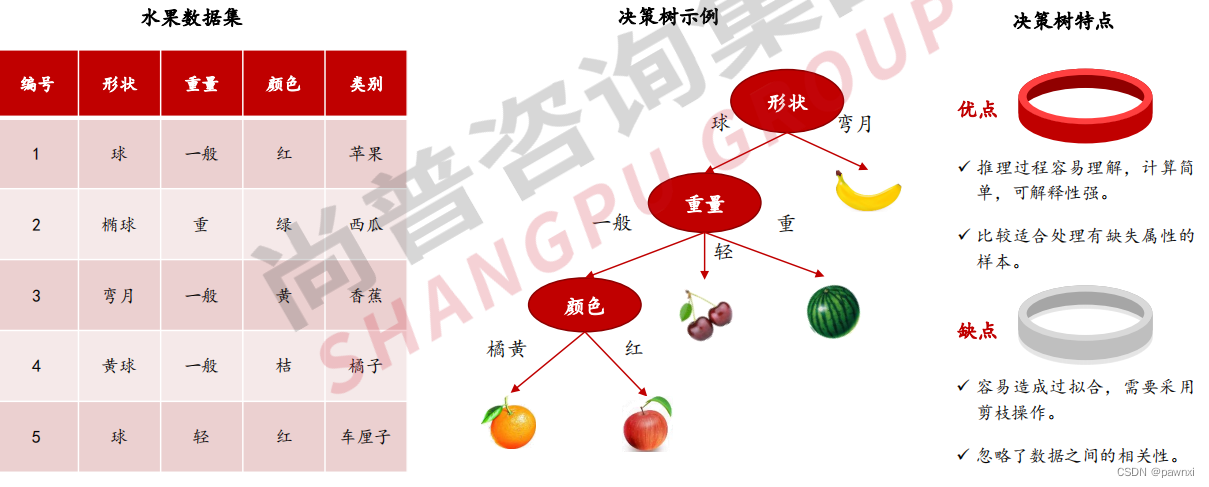
1.4有监督学习—随机森林
随机森林:利用多决策树模型,提高模型预测精度
随机森林(Random Forest):是指利用多棵决策树对样本进行训练并预测的一种分类器。随机森林算法:从每个决策树收集输出,通过多数表决得到最终的分类结果。

1.5有监督学习—朴素贝叶斯
朴素贝叶斯是常用于 自然语言分类问题的算法
具体来说,就是计算数据为某个标签的概率,并将其分类为概率值最大的标签。朴素贝叶斯主要用于文本分类和垃圾邮件判定等自然语言处理中的分类问题。

以上为朴素贝叶斯算法过程:另外,朴素贝叶斯也常用于自然语言分类问题的算法

机器学习分类—无监督学习
无监督学习:对无标签样本进行学习揭示数据内在规律
无监督学习(Unsupervised Learning):主要是指训练数据在不含标记的情况下生成模型(通常在缺乏足够先验知识难以人工标注类别,或进行人工类别标注的成本高等情况下),无监督学习的目标是通过对无标签样本的学习来揭示数据的内在特性及规律。
无监督学习主要涉及聚类和降维问题,其中聚类问题涉及K-means聚类、概念聚类、模糊聚类等算法,聚类的目标是为数据点分组,使得不同聚类中的数据点不相似,同一聚类中的数据点则是相似的;降维问题主要是主成分分析、线性判别分析、多维尺度分析等算法,其中主成分分析将数据中存在的空间重映射成一个更加紧凑的空间,此种变换后的维度比原来维度更小。
常见的无监督学习适用场景涵盖发现异常数据、用户类别划分、推荐系统等场景。

机器学习分类—强化学习
强化学习:不依赖标注数据,有效解决序列行动优化问题
强化学习(Reinforcement Learning,RL):又称再励学习或评价学习,是系统从环境到行为映射的学习,以使激励信号(强化信号)函数值最大化。强化学习的关键要素有代理(Agent)、环境(Environment)、状态(State)、环境回报(Reward)。
强化学习特点包括:①学习过程中没有监督者,只有激励信号;②反馈信号是延迟而非即时的;③学习过程具有时间序列性质;④系统的动作会影响到后续的数据。

强化学习可分为 策略迭代算法和 价值迭代算法两类,典型算法包括 【策略梯度】、【Sarsa】、【Q-Learning】、【Actor-Critic】等。 强化学习在游戏、自动驾驶、推荐系统等领域有着广阔应用前景。
Original: https://blog.csdn.net/pawnxi/article/details/127258094
Author: pawnxi
Title: 机器学习划分,为有监督学习、无监督学习、强化学习。
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/794350/
转载文章受原作者版权保护。转载请注明原作者出处!