

scrapy 框架初识
安装
如果没记错,python 3.6 及以上版本可以直接用 pip install scrapy.但具体是从哪个版本开始可以这样我也不是很清楚,因为我使用的 python 3.95,所以我是直接用 pip安装的。也正因为如此,对于下载whl格式的包安装我是不太清楚的,所以不提。
认识
scrapy 安装成功后,我们来创建项目框架。
打开终端。cmd 或者从 pycharm 中打开终端。我以 pycharm 为例。
首先,进入到相应的目录


创建项目框架文件夹
scrapy startproject projectName

在进入刚创建的文件夹,创建新的执行文件
scrapy genspider fileName www.xxxx.com

然后我们打开我们创建的项目框架
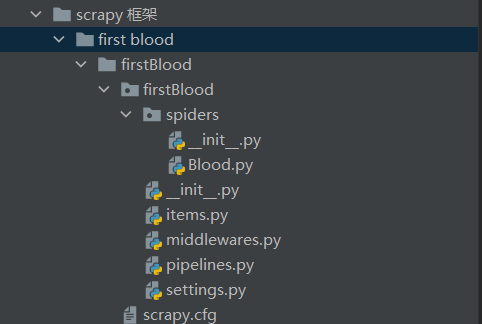
其中
Blood.py是主代码文件, items.py 是跟保存有关的文件, middlewares.py是中间件, pipelines.py是管道文件, settings.py是配置文件。这些以后会讲到的,暂且不提。
如果要执行代码,终端的命令是 scrapy crawl fileName
在这个案例里,就是 scrapy crawl Blood
简单的代码实现
先打开 Blood.py文件
其中代码如下:

我圈起来的部分是允许爬虫爬取的网站的域名,而下面的列表是待爬取的网址。这就是说,如果待爬取的网址不属于我圈起来的域名,这些网址就不会被爬取。所以一般来说,我们直接是将这一行代码注释掉。
然后我们试着爬取百度首页。
首先代码如下:
import scrapy
class BloodSpider(scrapy.Spider):
name = 'Blood'
start_urls = ['http://www.baidu.com/']
def parse(self, response):
print(response.url)
pass
执行代码 scrapy crawl Blood
运行结果:

好家伙,这一坨是什么东西?
先来看我圈起来的部分,先是说连接到百度首页,再说被 robots 协议禁止了。好家伙,原来这是日志啊,但是 robots 协议怎么办?
没事,是时候打开我们的配置文件了

这里我们看到,我们的 scrapy 框架遵守 robots 协议,所以我们将 True 改成 False。再运行一次,🆗,这次没有报错了。

但是这一坨日志可真是叫人恶心。那有什么方法吗?
简单,再次打开而配置文件。
添加一行代码
LOG_LEVEL = "ERROR"

然后再次运行
看结果:

那么使用 scrapy 框架之后怎么保存爬取的内容呢?
嘿嘿,且听下回分解。
Original: https://blog.csdn.net/ShiJieDeYinYu/article/details/118397951
Author: 世界的隐喻
Title: 行百里者半九十——scrapy 框架(1)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/792872/
转载文章受原作者版权保护。转载请注明原作者出处!