

一、scrapy安装
- 普通:cmd→pip install scrapy
- anaconda:打开cmd窗口→输入命令conda install scrapy
二、框架解析


Engine (不需要用户修改)
- 控制所有模块间的数据流
- 根据条件触发事件
Scheduler(不需要用户修改)
- 对所有请求进行调度管理
Downloader(不需要用户修改)
- 根据请求下载网页
Downloader Milddleware中间键
- 目的:实施Engine、Scheduler、Downloader之间进行用户可配置的控制
- 功能:修改、丢弃、新增请求或响应
Spider(需要用户编写配置代码)
- 直接产生爬取请求
- 解析Downloader返回的响应,产生爬取项和额外的爬取请求
Spider Middleware
- 目的:对请求和爬取项的再处理
- 功能:修改、丢弃、新增请求或爬取项
Item Pipelines(需要用户编写配置代码)
- 以流水线方式处理Spider产生的爬取项
(由一组操作顺序组成,类似流水线,每个操作是一个Item Pipelines类型) - 可能操作包括:清理、检验、查重爬取项中的HTML数据,将数据存储到数据库中
; 三、Scrapy常用命令
- 命令格式:>Scrapy
- 一个工程:同一个Scrapy框架,可包含多个爬虫
命令说明格式startproject创建新工程scrapy startproject < name> [dir]genspider创建爬虫scrapy genspider [options] < name> < domain>settings获取爬虫配置信息scrapy settings [options]crawl运行爬虫scrapy crawl < spider>list列出工程中所有爬虫scrapy listshell启动url调试命令行scrapy shell [url]
四、requests库 VS Scrapy框架
相同点
- 都可以进行页面请求和爬取
- 可用性都好,文档丰富
- 都没处理js、提交表单、应对验证码等功能(可扩展)
不同点
requests库Scrapy框架页面爬虫:个别网页网站爬虫:批量网页功能库:由函数构成框架:部分函数不需用户定义和使用并发性不足,性能慢并发性好,性能高重点在页面下载重点在爬虫结构定制灵活一般定制灵活,深度定制困难
技术选择
- requests库:小需求
- Scrapy框架:大需求
(持续/周期性爬取网站信息,并积累信息形成自己的爬取库) - requests库 优于 Scrapy框架:定制程度的需求很高,想搭建自己的爬取框架
五、示例
1、创建工程
- cmd窗口→scrapy startproject 存储路径\工程名
- 生成的工程目录如下:
–1、文件名/:外层目录,即整个工程所在位置
–2、文件名/scrapy.cfg:部署scrapy爬虫的配置文件(将爬虫放在特定的服务器上,并且在服务器上配置好相应的操作接口)
–3、文件名/文件名/:scrapy框架下所有文件的目录
–4、文件名/文件名/_init_.py:初始化脚本(不需编写)
5、文件名/文件名/items.py:Items代码模块(不需编写)
6、文件名/文件名/middlewares.py:Middlewares代码模板(若扩展Middlewares功能,将工能写入此文件)
7、文件名/文件名/piplines.py:Piplines代码模板
–8、文件名/文件名/settings.py:Scrapy爬虫的配置文件(若优化爬虫功能,修改此文件中对应的配置项)
–9、文件名/文件名/spiders/:Spiders代码模块目录(存放此工程中建立的爬虫)
–文件名/文件名/spiders/_init_.py:初始文件,无需修改
文件名/文件名/spiders/_pycache_/:缓存目录,无需修改
目录如下图:

eg:建立工程:
scrapy startproject 桌面路径\python123demo

2、在工程中产生一个爬虫
- cmd窗口→scrapy genspider 爬虫名 网页域名
- 这步只是建立爬虫文件,修改后的爬虫代码如图:
eg:建立爬虫文件demo.py:

此时spiders目录下会出现demo.py文件

3、配置产生的爬虫
- 修改爬虫文件,进行相应爬取
- 编辑器→修改代码内容,如下图:
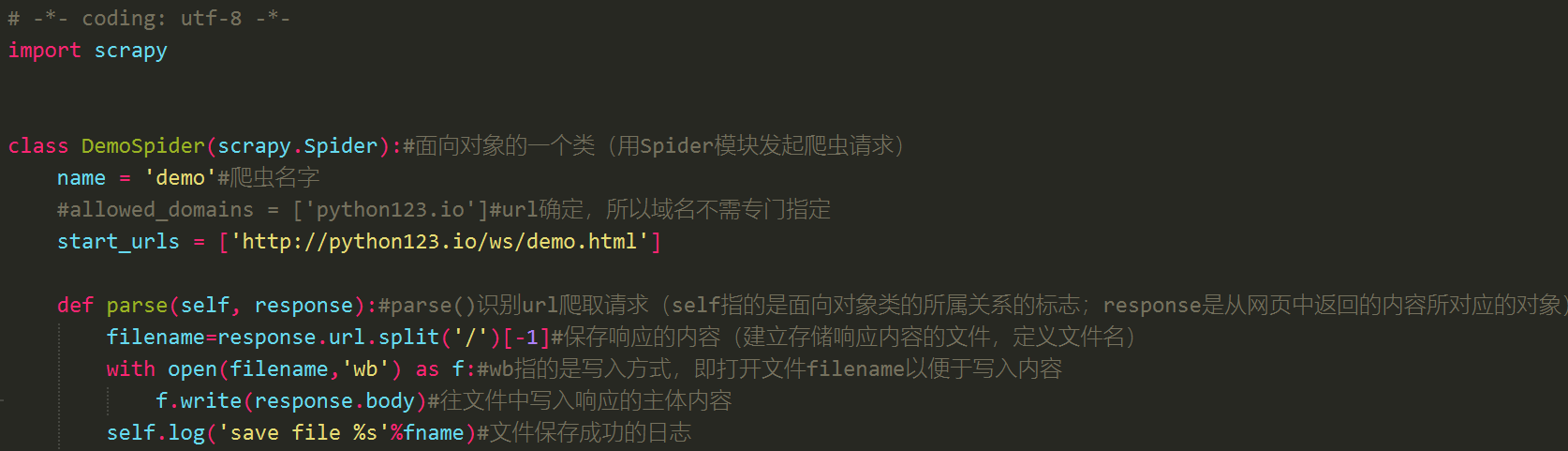
4、运行爬虫,获取网页
- cmd窗口→scrap crawl 爬虫文件名
- 此时工程里面就会出现爬虫的html文件
eg:scrapy crawl demo.py

Original: https://blog.csdn.net/weixin_45052608/article/details/105067462
Author: Ayanha
Title: Scrapy爬虫框架
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/792768/
转载文章受原作者版权保护。转载请注明原作者出处!