

Windows环境下
安装wheel:pip install wheel
安装scrapy: pip install scrapy
安装成功测试
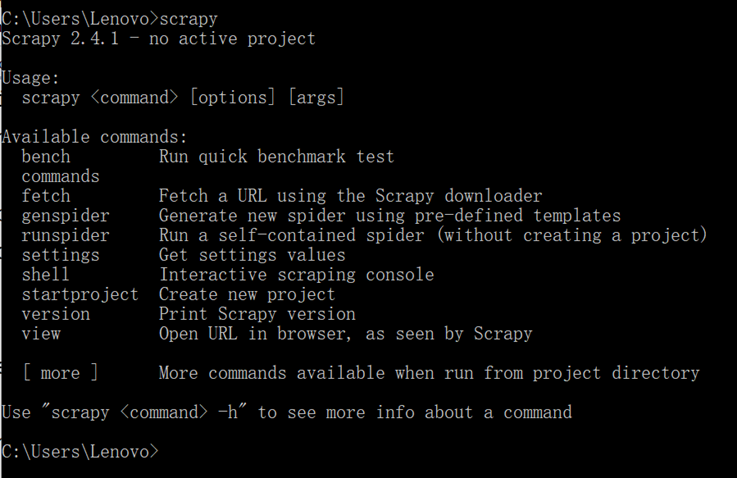

做个Demo
首先建立 项目包

cd SZPT 切换到此目录
创建srcapy工程:命令行输入命令
scrapy startproject szpt
在当前目录下创建如图所示的工程文件。
2.
切换到当前工程目录,
cd szpt

3.
打开spiders目录下的szptcrawler.py文件,修改加入如下代码:
def parse(self, response):
fname = 'szpt.html'
with open(fname, 'wb') as f:
f.write(response.body)
self.log('saved file %s' % fname);
4
命令行窗口输入命令:scrapy crawl szptcrawler。
可以看到当前工作目录下由scrapy下载的学校首页网页文件。
我的目录
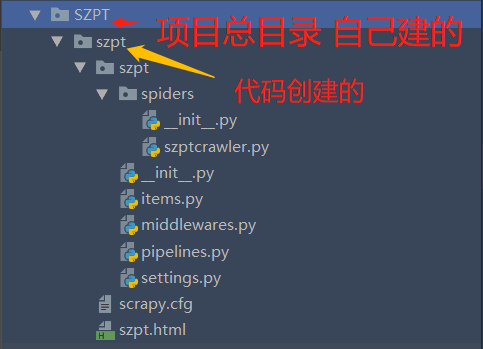
最后可以看到 szpt.html 已经生成了!!!
注意事项
第二点如果没有切换到正确的目录 szptcrawler会生成在根目录下面
Original: https://blog.csdn.net/csnz123123/article/details/116244268
Author: CSNZのBlog
Title: 下载及使用Scrapy进行爬虫
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/792382/
转载文章受原作者版权保护。转载请注明原作者出处!