

-
Scrapy常用命令
-
startproject:创建新的爬虫项目,参数project_name和project_dir分别表示项目的名称和项目存储的目录。
scrapy startproject
- genspider:在当前文件夹或者当前项目,创建一个新的爬虫文件,参数name表示创建的爬虫文件名,domain表示要爬取的网址,-t表示是否使用模板,可以使用”scrapy genspider -l”的方式查看所有的命令类型,或者使用”scrapy genspider -d”查看模板名称。
scrapy genspider [-t template]
- runspider:运行爬虫文件,参数spider_file.py表示要运行的爬虫文件。
scrapy runspider
- 获取指定的URL,并且能够显示出获取的过程。
scrapy fetch
- 在浏览器中打开指定的URL。
scrapy view
- 运行爬虫项目。
scrapy crawl
- 列出当前项目下的所有爬虫文件。
scrapy list
- 创建项目框架
运行scrapy startproject命令创建新的爬虫项目框架,项目名称为quotes
scrapy startproject quotes
为方便项目开发,可以借助Python的集成开发工具PyCharm进行开发,打开PyCharm,如图1-15。选择”Open”选择项目目录,如图1-16所示。

点击”OK”按钮确认选择爬虫项目的目录,这样爬虫框架的代码就加载到PyCharm中,Scrapy生成的框架代码结构如图所示。
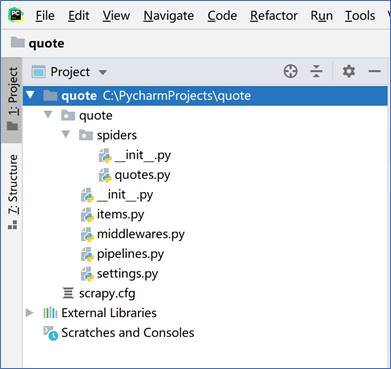
Scrapy框架代码
框架生成的源代码包括::items.py、pipelines.py、settings.py。
- items.py:定义结构化数据字段,用来保存爬取到的数据,也就是准备爬取的网页元素的特征。例如,爬取新闻网站上的新闻,items.py可以定义新闻标题、新闻内容、作者及发布时间等字段。
- pipelines.py:定义如何对抓取到的内容进行再处理,常见的处理方式有将网络爬虫爬取的数据保存为一个文件,或者写入关系型数据库或者NoSQL类型数据库,如MongoDB。
- settings.py:是Scrapy的设置文件,通过修改配置文件可以对网络爬虫程序进行灵活的配置,以使用不同的应用场景。
- spiders目录: 实现网络爬虫的核心处理逻辑。
Original: https://blog.csdn.net/weixin_44610125/article/details/121065295
Author: bingo fighting
Title: scrapy入门
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/792364/
转载文章受原作者版权保护。转载请注明原作者出处!