

scrapy框架爬取知乎110w用户信息,并存入mysql数据库和mongoDB数
scrapy框架爬取知乎110w用户信息,并存入mysql数据库和mongoDB数据库
知乎作为中国高端知识社区,里面各种大牛,本着虚心学习的态度,最近也注册了知乎,听说在知乎如果不是年过百万,或者不是海归博士,那都不好意思说话。由于小哥我学历低,学校名气不大,,一直没敢说过话(233333)。冲着对知乎的好奇,就花点时间借了点知乎的数据进行了学习探讨。这是一个月前做的了,由于这一个月学业繁忙,各种课各种考。昨天才想起了那一堆数据,于是乎对数据清洗了一下,然后做了个前端的数据可视化图表。分享给大家!
先贴上源码地址:https://github.com/hiajianchan/zhihuSpider
前端数据可视化展示:http://blog.csdn.net/chj_orange/article/details/72524460
用到的工具:
python3.6
scrapy
mysql
MongoDB
有一点需要注意的就是scrapy的安装,建议大家使用Anaconda,而不是仅仅下载python,python仅仅是个编译器,Anaconda不仅仅嵌有payhon的编译器,而且还支持了常用的包,这些包通常是以后下载需要包的依赖包。只使用python,下载安装包有时候会出现各种各样的错误。Anaconda往往不会出现错误。
首先爬虫我用的是scrapy框架,当然如果使用Requests,BeautifulSoup等模块也是可以实现的,但是框架有着天然的优势,简洁好用,scrapy底层支持多线程,而且scrapy下的Scheduler(调度器),Dupe(队列),
Pipeline(管道)这些方法大大提高了爬取效率,Dupe待爬队列可以存储待爬url,然后Scheduler调度器根据待爬url的优先级进行调度,爬取的数据Pipeline管道进行存储。可以使效率得到很大的提高。
先来分析知乎的页面。
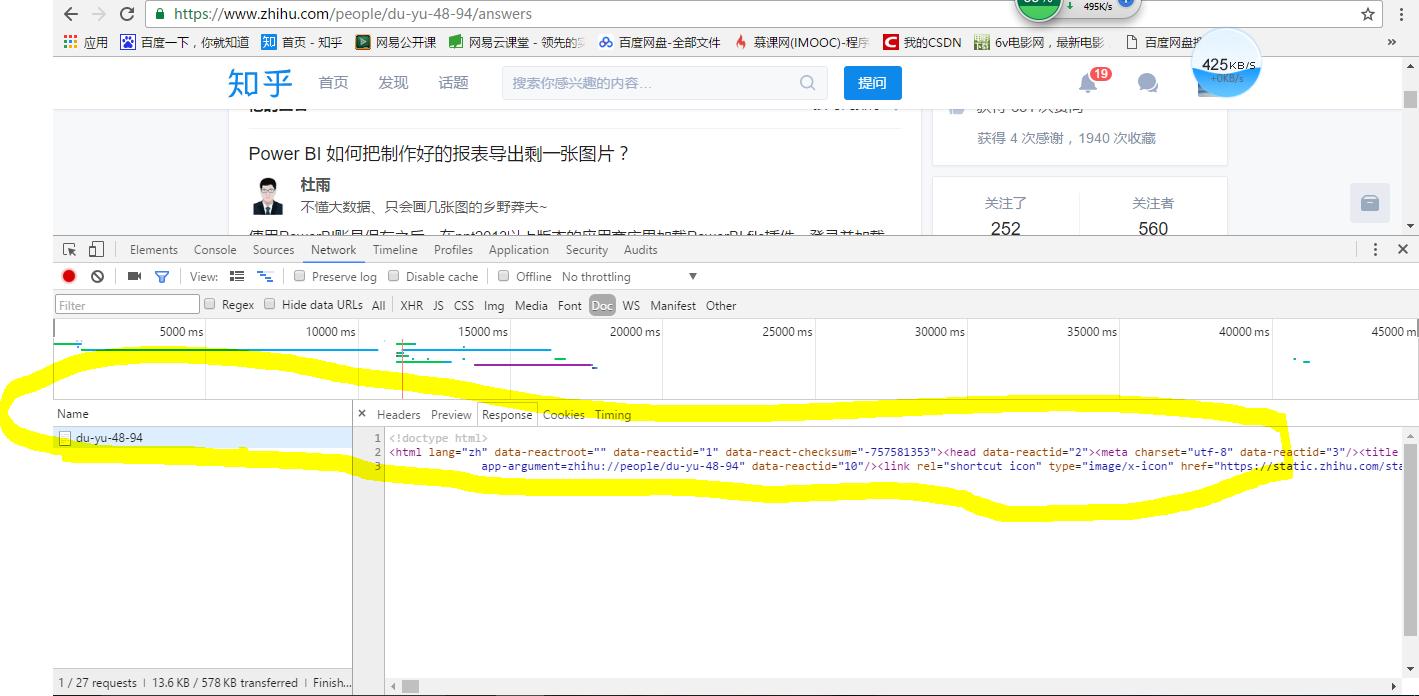

这是杜雨先生的首页,我们可以看到知乎的页面数据加载方式是采用的异步加载方式。所以我们如果爬取这个页面的话是爬取不到我们想要的数据的。我们接着往下看….
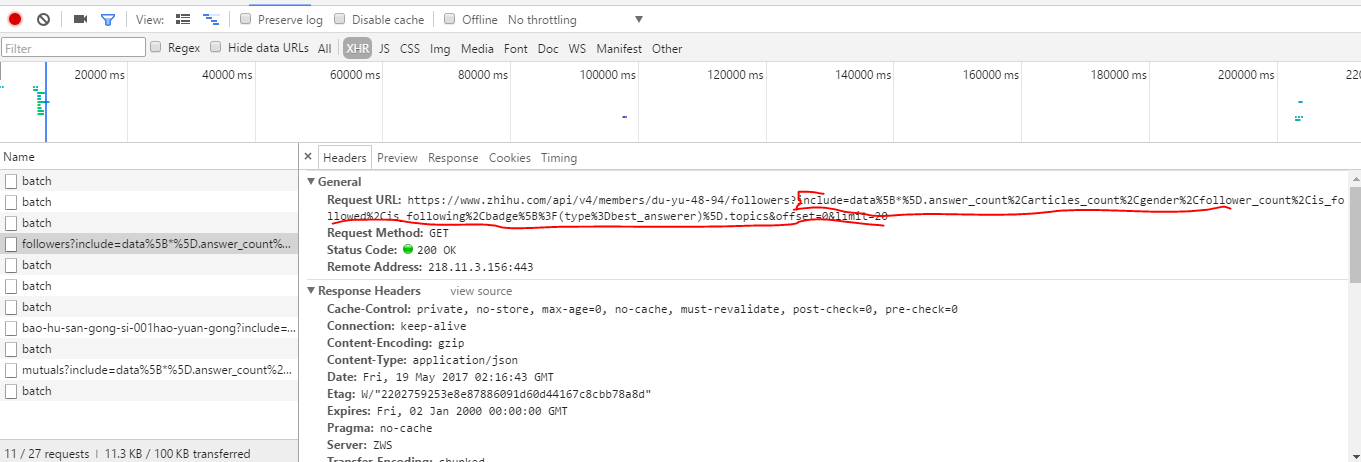
点击开发者工具里的XHR,然后刷新,我们看到Name下有个follower开头的url。上图我们可以看到url红色部分很长的一串,当你分析其他页面你就会发现,这一串是不变的。接着往下。。。。
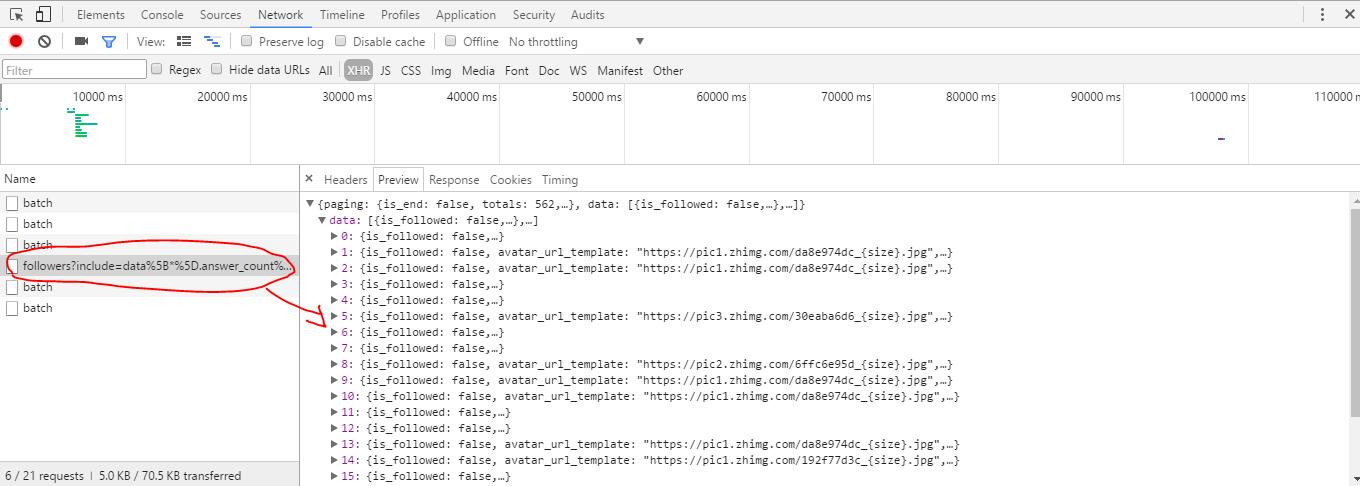
我们看这个url的response,可以看到一串的json数据,当我们打开后会发现这些json数据就是粉丝的简单信息,这只是一页的列表,每页有20个,那该如何找到所有的页的json数据呢?往下走。。。
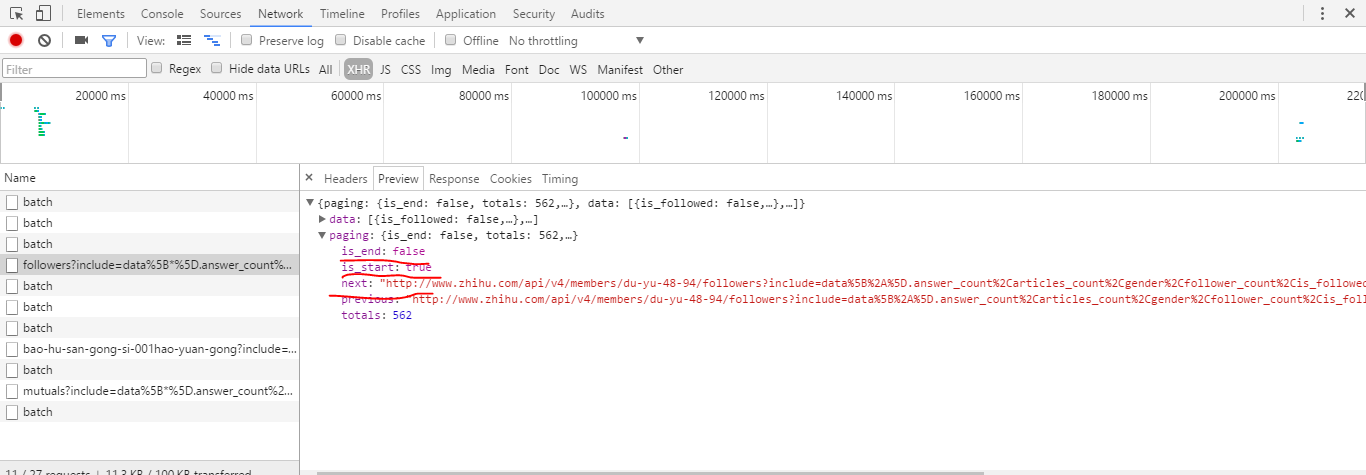
我们看到有个paging的键,其对用的值就是页面数据 ,is_end标示是否为最后一页,此处不是即为false,is_start标示是否为第一页此处为true,标示为第一页。next即为下一页的url,随后的代码我们可以使用递归代用的方法开获取所有的数据。。。
我们往下看,粉丝数据包含哪些信息。。。走着——>
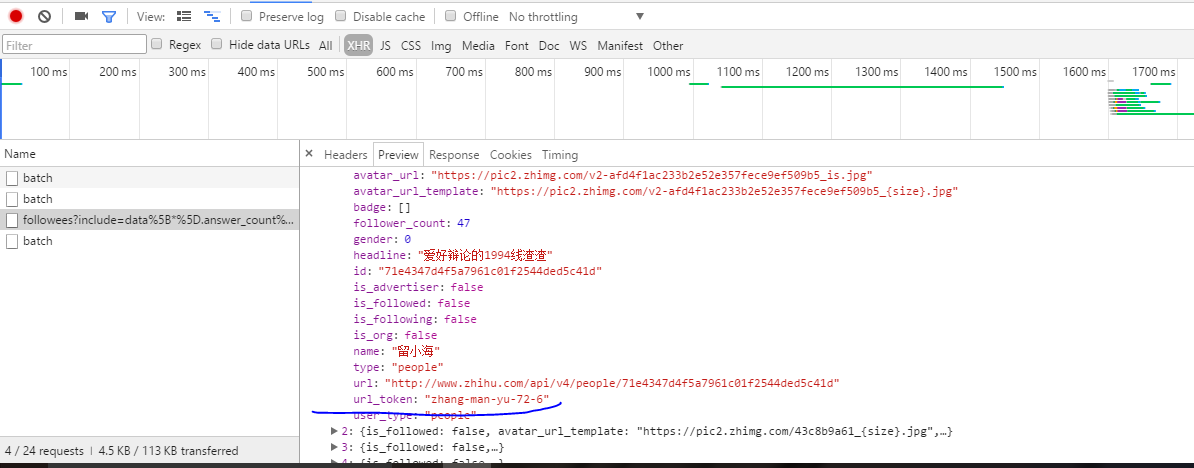
我们所需要的就是蓝线标注的url_token,这是每个知乎用户的 唯一标识,就是用户的编码ID。接着往下走。。。当我们将鼠标放在列表中的某各粉丝的时候——>
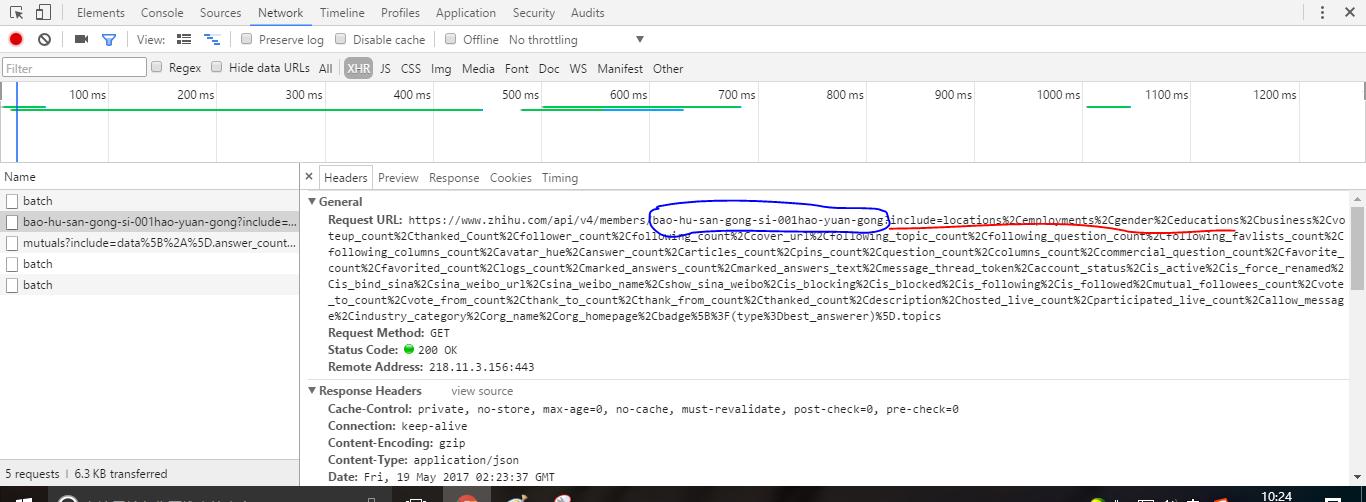
如上图,即是粉丝的url,蓝色圈住的就是其唯一标识ID。我们再来看其response——>
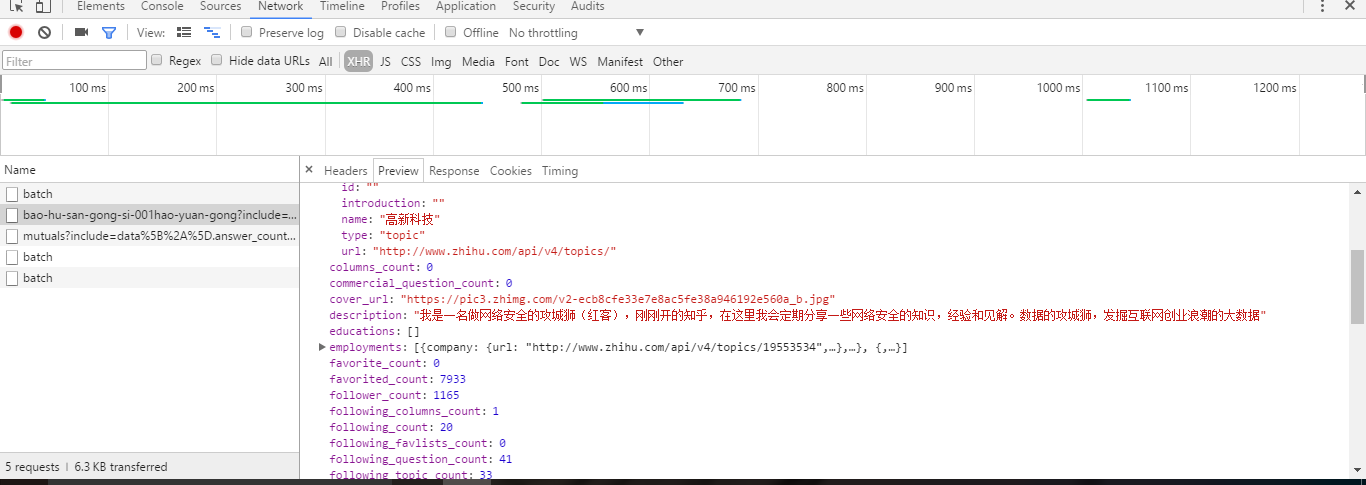
出来啦!!!,这就是用户的数据信息,json格式的数据,,包括了姓名,性别,居住地,工作,关注数,粉丝数,点赞数。。等等。。。这就是我们要的!过程很清晰有木有!!
接下来就是撸代码啦!走着——>
首先我们找个大V作为爬取起始点,这里用雷军雷总的吧,Are you OK? 标识为”mileijun”,开始构建url——>
start_user = ‘mileijun’
他关注的人
follows_url = ‘https://www.zhihu.com/api/v4/members/{user}/followees?include={include}&offset={offset}&limit={limit}’
follows_query = ‘data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics’
关注他的人
followers_url = ‘https://www.zhihu.com/api/v4/members/{user}/followers?include={include}&offset={offset}&limit={limit}’
followers_query = ‘data[*].answer_count,articles_count,gender,follower_count,is_followed,is_following,badge[?(type=best_answerer)].topics’
user_url = ‘https://www.zhihu.com/api/v4/members/{user}?include={include}’
user_query = ‘locations,employments,gender,educations,business,voteup_count,thanked_Count,follower_count,following_count,cover_url,following_topic_count,following_question_count,following_favlists_count,following_columns_count,answer_count,articles_count,pins_count,question_count,commercial_question_count,favorite_count,favorited_count,logs_count,marked_answers_count,marked_answers_text,message_thread_token,account_status,is_active,is_force_renamed,is_bind_sina,sina_weibo_url,sina_weibo_name,show_sina_weibo,is_blocking,is_blocked,is_following,is_followed,mutual_followees_count,vote_to_count,vote_from_count,thank_to_count,thank_from_count,thanked_count,description,hosted_live_count,participated_live_count,allow_message,industry_category,org_name,org_homepage,badge[?(type=best_answerer)].topics’*_query 就是url中相同的部分。
爬取过程代码如下:
def start_requests(self):
yield Request(self.user_url.format(user=self.start_user, include=self.user_query), callback=self.parse_user)
url = self.follows_url.format(user=self.start_user, include=self.follows_query, offset=0, limit=20)
yield Request(url, callback=self.parse_follows)
关注他的人
foll_url = self.followers_url.format(user=self.start_user, include=self.followers_query, offset=0, limit=20)
yield Request(foll_url, callback=self.parse_followers)
def parse_user(self, response):
返回的信息是json格式,所以要解析
results = json.loads(response.text)
item = UserItem()
for field in item.fields:
if field in results.keys():
item[field] = results.get(field)
yield item
yield Request(self.follows_url.format(user=results.get(‘url_token’), include=self.follows_query, offset=0, limit=20), self.parse_follows)
yield Request(self.followers_url.format(user=results.get(‘url_token’), include=self.followers_query, offset=0, limit=20), self.parse_followers)
def parse_follows(self, response):
results = json.loads(response.text)
获取到用户的url,然后进行请求
if ‘data’ in results.keys():
for result in results.get(‘data’):
url_token = result.get(‘url_token’)
if url_token != None:
yield Request(self.user_url.format(user=url_token, include=self.user_query), self.parse_user)
判断如果不是最后一页,将获取到下一页的url
if ‘paging’ in results.keys() and results.get(‘paging’).get(‘is_end’) == False:
next_page = results.get(‘paging’).get(‘next’)
yield Request(next_page, self.parse_follows)
parse_followers
def parse_followers(self, response):
results = json.loads(response.text)
获取到用户的url,然后进行请求
if ‘data’ in results.keys():
for result in results.get(‘data’):
url_token = result.get(‘url_token’)
if url_token != None:
yield Request(self.user_url.format(user=url_token, include=self.user_query), self.parse_user)
判断如果不是最后一页,将获取到下一页的url
if ‘paging’ in results.keys() and results.get(‘paging’).get(‘is_end’) == False:
next_page = results.get(‘paging’).get(‘next’)
yield Request(next_page, self.parse_followers)我们构建的item如下,此处就是获取的信息
from scrapy import Item, Field
class UserItem(Item):
define the fields for your item here like:
_id = Field()
name = Field()
gender = Field()
locations = Field()
business = Field()
educations = Field()
description = Field()
employments = Field()
following_count = Field()
follower_count = Field()
voteup_count = Field()
thanked_count = Field()
favorited_count = Field()
following_columns_count = Field()
following_favlists_count = Field()
following_question_count = Field()
following_topic_count = Field()
answer_count = Field()
question_count = Field()
articles_count = Field()
favorite_count = Field()
logs_count = Field()
url_token = Field()在pipelines函数下进行数据的写入数据库操作,在这里推荐MongoDB数据库,因为MongoDB存储的数据为Bson数据(也就是Json)
而我们获取的数据正好是Json数据,当然mysql数据也可以,关系型的一张表看起来比较直观。
class ZhihuuserPipeline(object):
conn = MongoClient(‘mongodb://localhost:27001/’)
db = conn.test
db.authenticate(“你的用户名”, “你的密码”)
def process_item(self, item, spider):
self.db.zhihu.insert(item)
此处展示的是插入MongoDB。
好啦!我科目为看一下我们的成果吧。
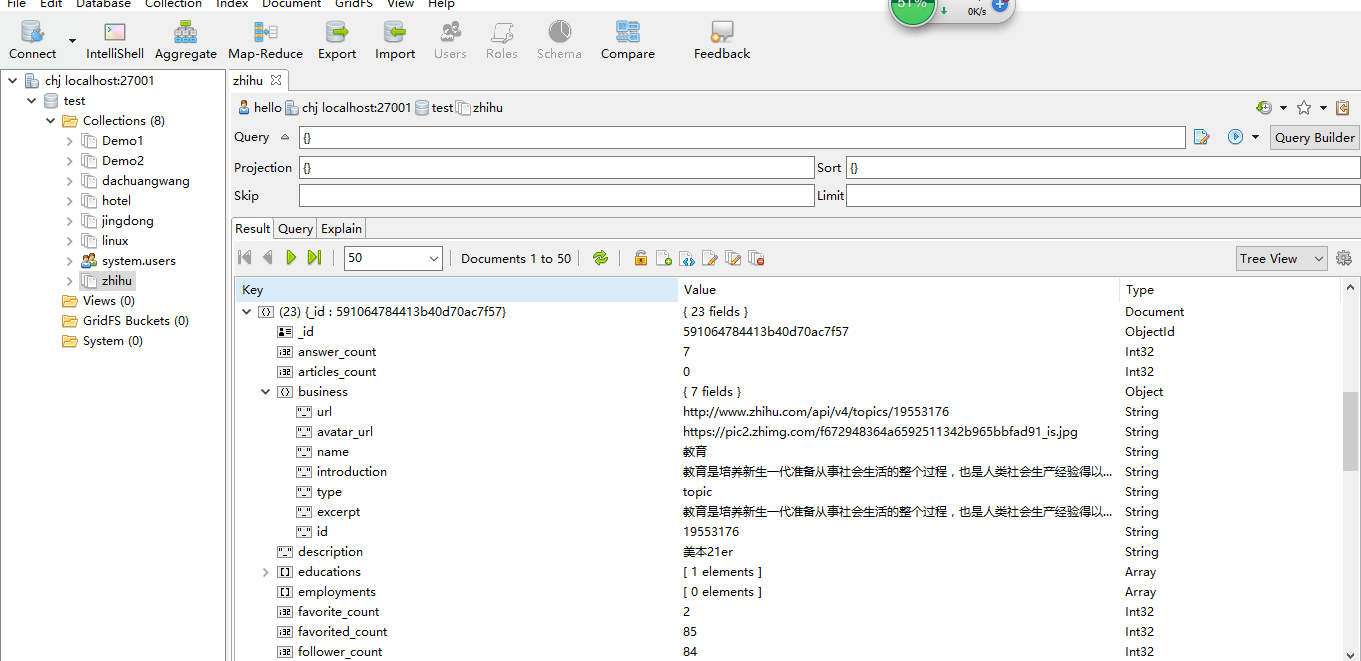
在看一下存在sql server中的数据(直观)112W条数据
接下来就是对数据进行分析啦!!
可视化请看:本博客java分类下的可视化分析
注意:数据仅供学习参考,勿使用其他用途!
scrapy框架爬取知乎110w用户信息,并存入mysql数据库和mongoDB数相关教程
Original: https://blog.csdn.net/weixin_42282699/article/details/114848922
Author: 小荧
Title: mysql建立用户知乎_scrapy框架爬取知乎110w用户信息,并存入mysql数据库和mongoDB数…
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/792294/
转载文章受原作者版权保护。转载请注明原作者出处!