

文章目录
第十九章 crawlspider讲解
今天我们来讲一下crawlspider,我们原则上先掌握最基础的,然后是高级一点的。我们将上一次的古诗文案例用crawspider来处理一下。
1. 古诗文案例crawlspider
创建项目文件:
终端输入:scrapy startproject gs20210217 回车
创建crawlspider爬虫项目,语句:
cd 到gs20210217文件夹中,终端输入:
scrapy genspider -t crawl 爬虫的名字 域名
然后输入创建项目语句,创建项目:
scrapy genspider -t crawl cgs https://www.gushiwen.cn/
Use "scrapy" to see available commands
D:\work\爬虫\Day21\my_code>scrapy startproject gs20210217
New Scrapy project 'gs20210217', using template directory 'd:\python38\lib\site-packages\scrapy\template
s\project', created in:
D:\work\爬虫\Day21\my_code\gs20210217
You can start your first spider with:
cd gs20210217
scrapy genspider example example.com
D:\work\爬虫\Day21\my_code>cd gs20210217
D:\work\爬虫\Day21\my_code\gs20210217>scrapy genspider -t crawl cgs https://www.gushiwen.cn/
Created spider 'cgs' using template 'crawl' in module:
gs20210217.spiders.cgs
D:\work\爬虫\Day21\my_code\gs20210217>
项目创建成功。
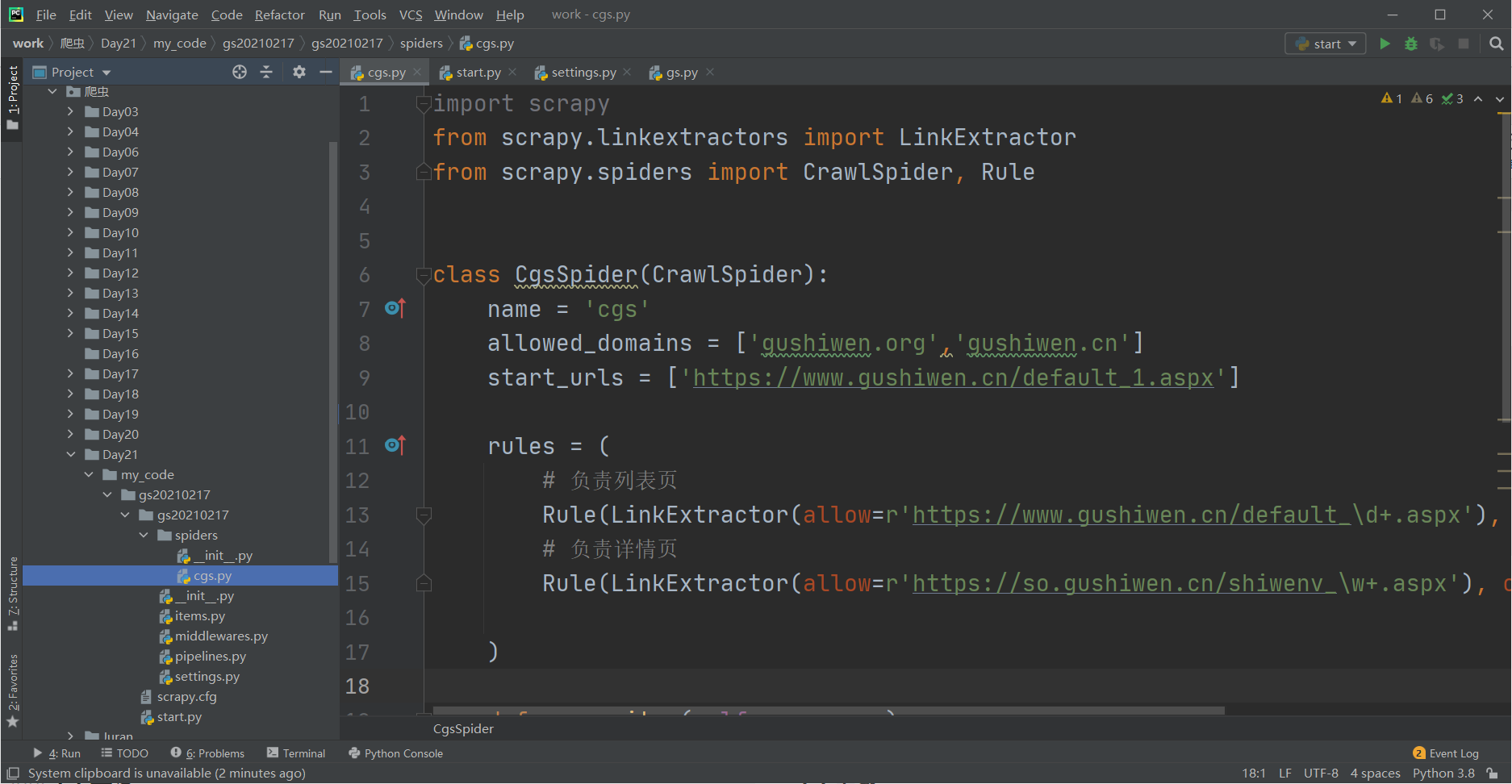

我们可以看到crawlspider比scrapyspider,继承的父类发生了变化,导入的模块多了一个。造类里面多了一个Rules:
class CgsSpider(CrawlSpider):
name = 'cgs'
allowed_domains = ['https://www.gushiwen.cn/']
start_urls = ['http://https://www.gushiwen.cn//']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
Rule定义提取url的规则,LinkExtractor是链接提取器。
- allow=r’Items/’这个用来存放url (用到正则表达式)
- callback=’parse_item’是回调函数,处理请求结果。
- follow=True继续跟进下一页
下面我们通过案例来学习。
1.1 需求
仍然是爬取古诗文的详情。我们需要处理的事情一个是翻页,第二个是爬取译文。
我们需要列表页的url地址
https://www.gushiwen.cn/ # 第一页
https://www.gushiwen.cn/default_1.aspx # 第一页
https://www.gushiwen.cn/default_2.aspx # 第二页
https://www.gushiwen.cn/default_3.aspx # 第三页
另一个是详情页的url地址
https://so.gushiwen.cn/shiwenv_7c14409ca751.aspx # 列表页第一页第一首诗的详情页
https://so.gushiwen.cn/shiwenv_0184c31a9e01.aspx # 列表页第一页第二首诗的详情页
我们的顺序是先爬第一页,第一页的第一首,第二首,完了,翻页。。。
1.2 处理
下面注意看代码中的注释:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CgsSpider(CrawlSpider):
name = 'cgs'
allowed_domains = ['https://www.gushiwen.cn/']
start_urls = ['http://https://www.gushiwen.cn//']
rules = (
# 负责列表页
Rule(LinkExtractor(allow=r'https://www.gushiwen.cn/default_1.aspx'), follow=True),
# 负责详情页
Rule(LinkExtractor(allow=r'https://so.gushiwen.cn/shiwenv_7c14409ca751.aspx'), callback='parse_item', )
) # 详情页不需要翻页,所以去掉follow=True
# 列表页不需要数据,只需要翻页,所以不需要回调函数,去掉callback='parse_item'
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
下面我们需要把url里面的跟随翻页变化的字符用正则表达式来匹配一下:
# 负责列表页 正则匹配1-10=>\d+
Rule(LinkExtractor(allow=r'https://www.gushiwen.cn/default_\d+.aspx'), follow=True),
# 负责详情页 正则匹配7c14409ca751 =>\w+
Rule(LinkExtractor(allow=r'https://so.gushiwen.cn/shiwenv_\w+.aspx'), callback='parse_item', )
\d可以匹配0-9的数字,+表示至少匹配一次。\W可以匹配大小写字母和数字,+也是至少匹配一次。关于正则表达式的只是请参考我的博客[爬虫(05)正则表达式]。(https://blog.csdn.net/m0_46738467/article/details/111587355)
这样我们就将列表页和详情页的url用正则表达式匹配完成。crawlspider只适合简单一些的url,如果url构成比较复杂,就用一般的爬虫方式就可以了。
1.3 解析
我们只需要详情页的译文,我们把第19次博客案例解析译文的代码复制过来就可以了。
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
shang = response.xpath('//div[@class="contyishang"]/p/text()').extract()
content_shang = ''.join(shang).strip() # 处理空格及换行符
item['detail_content'] = content_shang # 加入items
print(item)
return item
去settings里面设置一下:
LOG_LEVEL = 'WARNING'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
然后我们创建一个start文件:
from scrapy import cmdline
cmdline.execute('scrapy crawl cgs'.split())
我们运行一下:
{'detail_content': '译文富家的子弟不会饿死,清寒的读书人大多贻误自身。韦大人你可以静静地细听,我把自己的往事向你直陈。我在少年时候,早就充当参观王都的来宾。先后读熟万卷书籍&
Original: https://blog.csdn.net/m0_46738467/article/details/113831531
Author: 辉子2020
Title: 爬虫(21)crawlspider讲解古诗文案例补充+小程序社区案例+汽车之家案例+scrapy内置的下载文件的方法
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/791230/
转载文章受原作者版权保护。转载请注明原作者出处!