

scrapy中文官方文档:点击打开连接html
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途普遍,能够用于数据挖掘、监测和自动化测试,
Scrapy吸引人的地方在于它是一个框架,任何人均可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
1.建立项目
在开始爬取以前,您必须建立一个新的Scrapy项目。 进入您打算存储代码的目录中,运行下列命令:python
scrapy startproject day1

2.定义item
Item 是保存爬取到的数据的容器;其使用方法和python字典相似, 而且提供了额外保护机制来避免拼写错误致使的未定义字段错误web
import scrapy
class Day1Item(scrapy.Item):
city = scrapy.Field()
temperature = scrapy.Field()
date = scrapy.Field()
pass
3.编写爬虫
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。其包含了一个用于下载的初始URL,如何跟进网页中的连接以及如何分析页面中的内容, 提取生成 item 的方法。json

在spiders中建立一个名为sinaweather.py文件框架
import scrapy
from day1.items import Day1Item # day1是文件夹的名,Day1Item是items.py中的类class名
class weatherSpider(scrapy.spiders.Spider): #weatherSpider是自定义的名
name = “sina” #sina是自定义的名
allowed_domains = [‘sina.com.cn’] #sina.com.cn是限定在这个网站的范围以内爬虫
start_urls = [‘http://weather.sina.com.cn/xian’] #开始爬虫的网址
def parse(self, response):
item= Day1Item()
item[‘city’] = response.xpath(‘//*[@class=”slider_ct_name”]/text()’).extract()
item[‘temperature’]=response.xpath(‘//*[@class=”wt_fc_c0_i_temp”]/text()’).extract()
item[‘date’]=response.xpath(‘//*[@class=”wt_fc_c0_i_date”]/text()’).extract()
return item
4.修改配置文件(settings)
BOT_NAME = ‘day1’
SPIDER_MODULES = [‘day1.spiders’]
NEWSPIDER_MODULE = ‘day1.spiders’
FEED_EXPORT_ENCODING = ‘utf-8’
5.执行爬虫命令
在命令行输入以下命令:dom
scrapy crawl sina -o test.json
咱们看到命令行出现以下内容,说明爬虫成功了scrapy
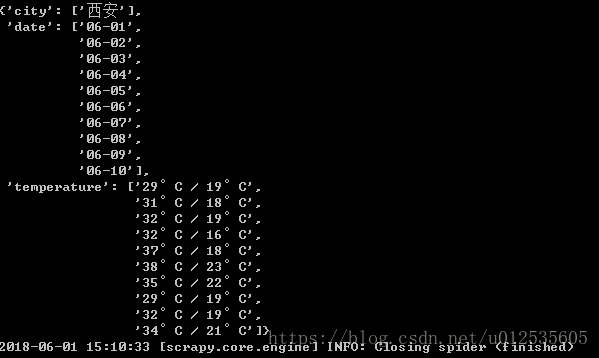
而后咱们回到根目录下,看咱们刚保存的test.json文件,咱们看到以下json内容,说明须要爬到的数据被保存到test.json文件中ide

至此第一个scrapy爬虫示例基本实现,后续会更深刻的学习如何利用scrapy抓取数据学习
Original: https://blog.csdn.net/weixin_29720641/article/details/113672626
Author: 优普道建筑网校
Title: python爬虫天气实例scrapy_python爬虫之利用scrapy框架抓取新浪天气数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/791200/
转载文章受原作者版权保护。转载请注明原作者出处!