

本次爬取的网站https://image.so.com/打开此页面切换到美女的页面,打开浏览器的开发者工具,切换到XHR选项,然后往下拉页面,我么会看到出现许多的ajax请求,如图:
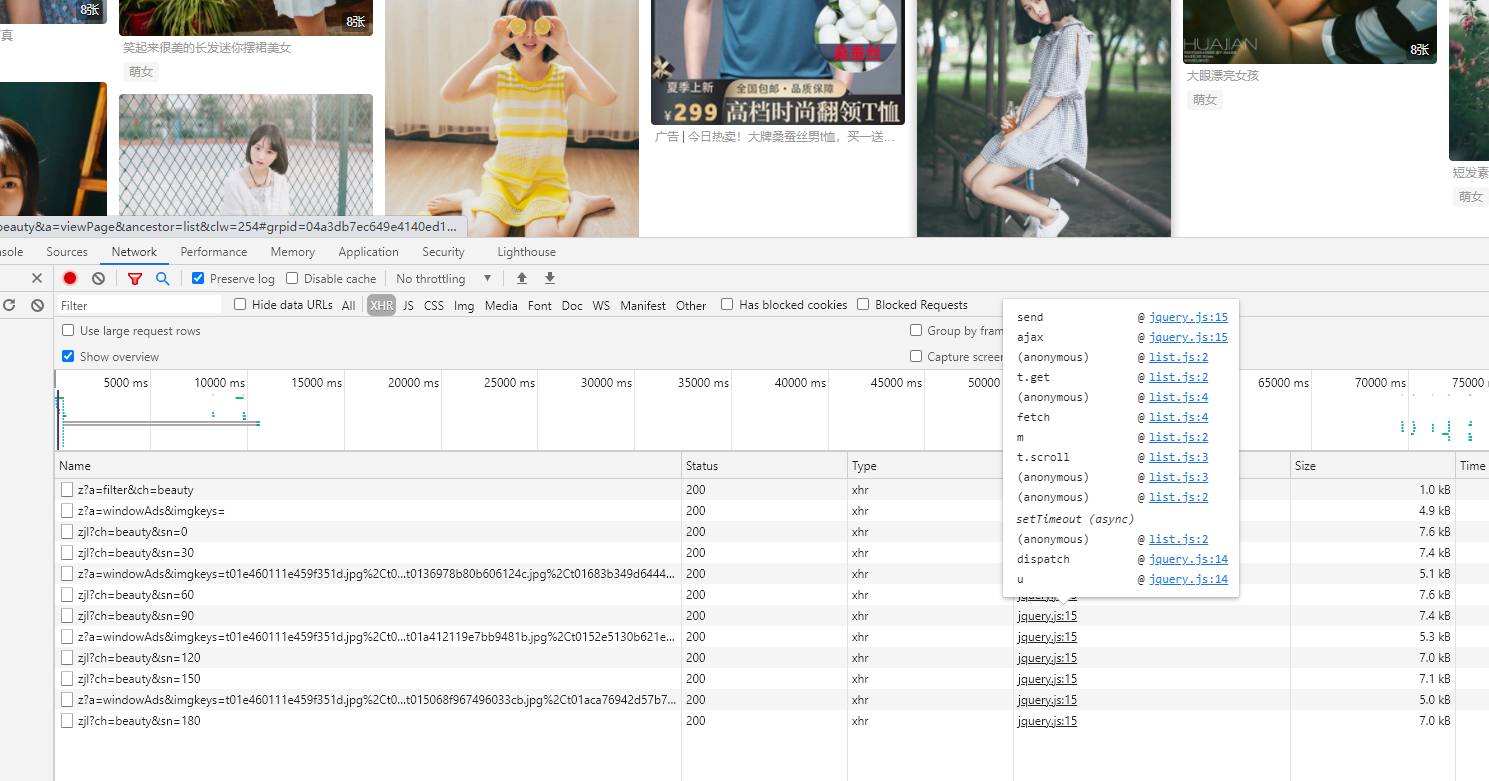

对上面的许多请求进行分析会发现我们要爬取图片的数据就在很多类似这样的 zjl?ch=beauty&sn=30 sn=0时代表0-30张图片,sn=30代表31-60张图片依次排列 点进去,如图
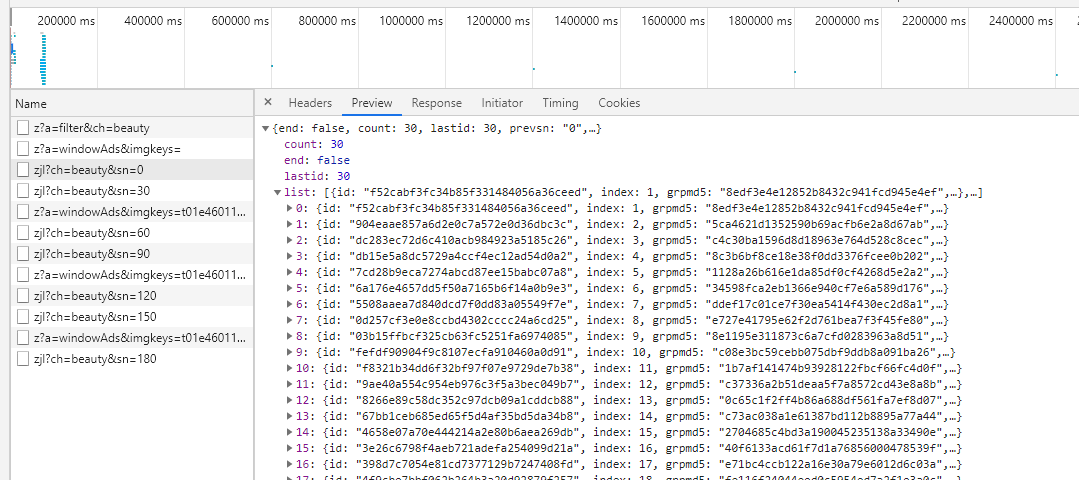
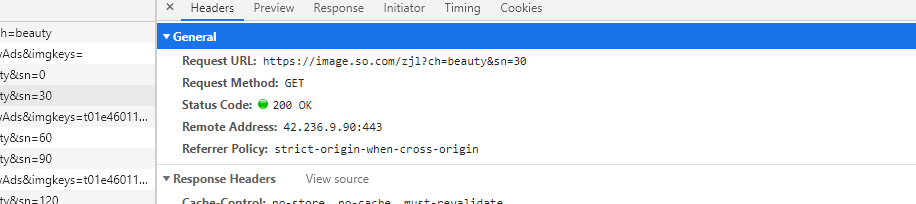
切换到Headers 找到我们要请求的url (Request URL) 经过分析我们要请求的url很有规律经过简单的拼接一下就可以得到
实现代码
Spiders.py代码
import scrapy
from Pro360.items import Pro360Item
import json
class ImaSpider(scrapy.Spider):
name = 'Ima'
start_urls = ['https://image.so.com/zjl?ch=beauty&sn=0']
MAx_page = 50
for i in range(1,MAx_page+1):
url = 'https://image.so.com/zjl?ch=beauty&sn={}'.format(i*30)
start_urls.append(url)
def parse(self, response):
result = json.loads(response.text)
for image in result['list']:
Original: https://blog.csdn.net/weixin_44996454/article/details/116664332
Author: B .O .
Title: scrapy框架分析ajax请求爬取图片并同时存到mongodb和mysql数据库中把照片存到本地
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/791186/
转载文章受原作者版权保护。转载请注明原作者出处!