

本文以 quotes.toscrape.com 为例进行简单的数据爬取,Quotes to Scrape 是 Scrapy 官方文档中使用的示例网站,数据项较为简单,适合入门
网站分析
http://quotes.toscrape.com/ 是一个名句摘抄的网站,每段摘抄都标注了出处、标签
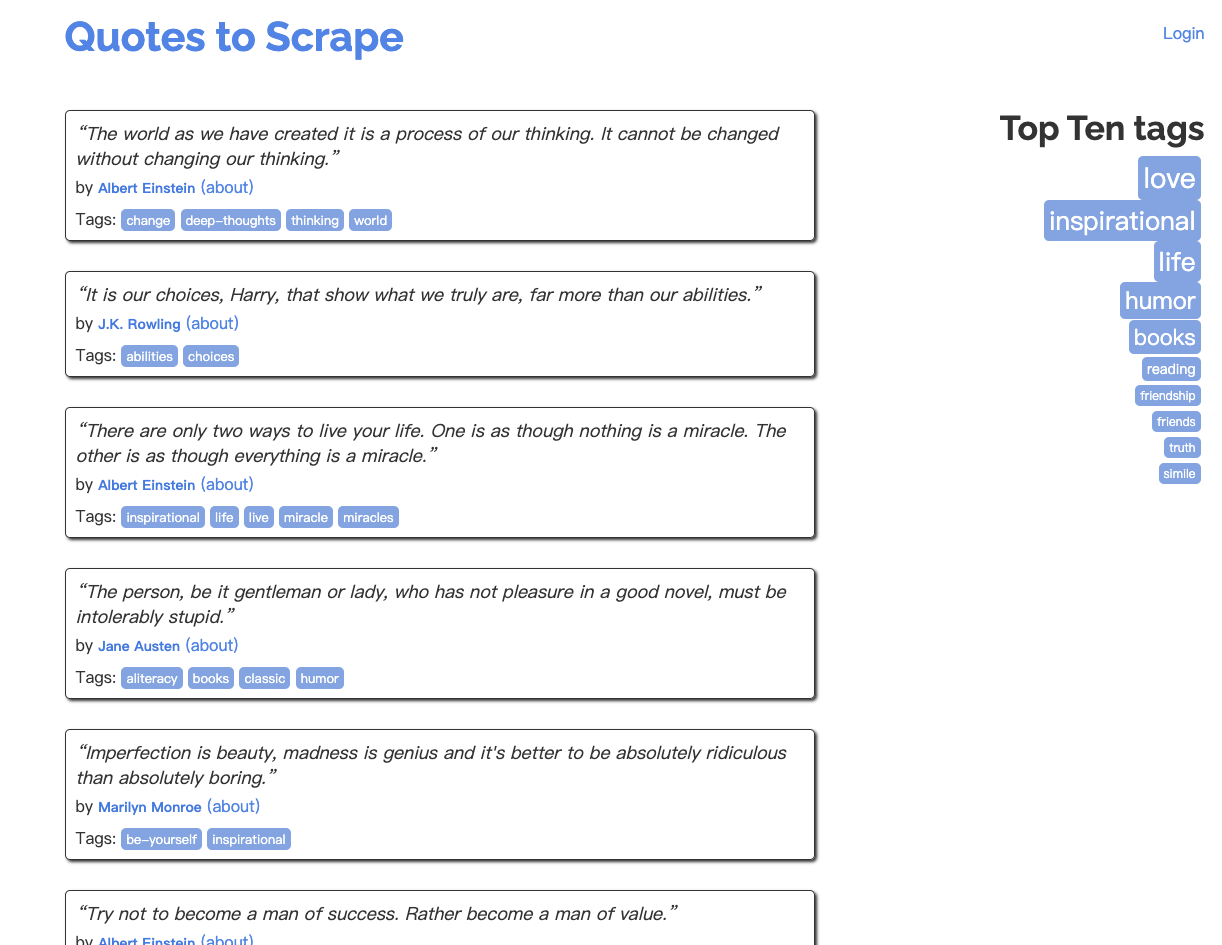

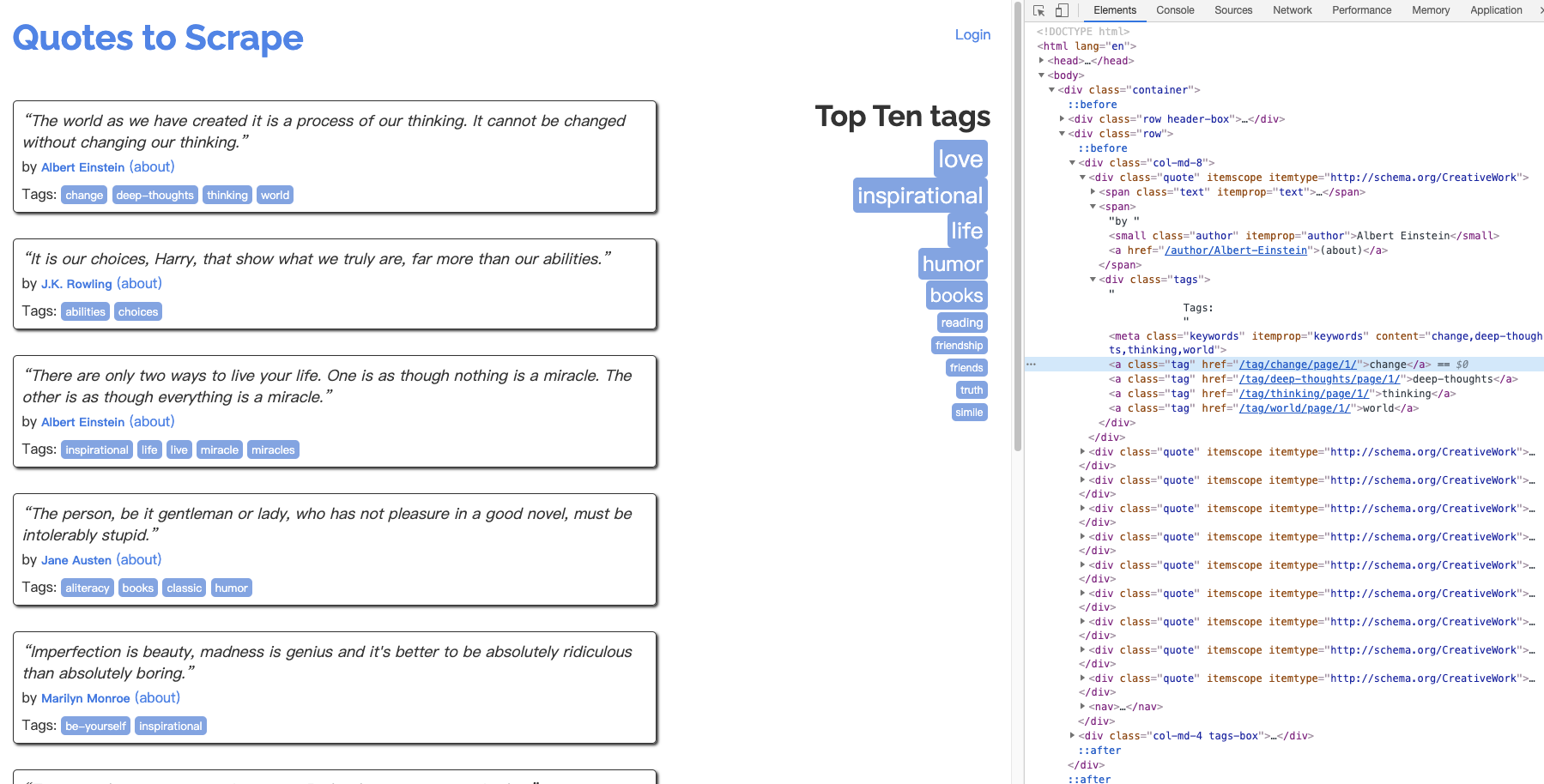
Command + Option + I,查看页面元素,接下来我们会根据元素进行数据
; 创建项目
在终端输入
scrapy startproject quotes
quotes 是项目名称
目录结构:
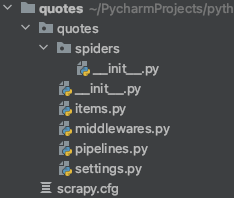
Spiders
Spiders 就是用户编写的,用来解析页面、获取数据的类
切换到项目目录
cd quotes
创建 Spider
scrapy genspider QuotesSpider quotes.toscrape.com
会在 spiders 目录下创建一个 QuotesSpider.py 文件
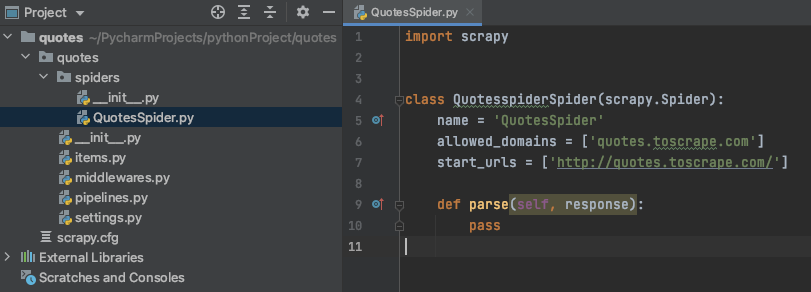
name 是 Spider 名
allowed_domains 是 可爬取的域名列表,如果启用了 OffsiteMiddleware (默认启用),就不跟踪不在此列表中的URL
start_urls 从这个列表中的URL开始爬取,可以有多个URL
parse(self, response) 是默认回调
下面开始编写我们自己的Spider
爬取名言摘抄
编写回调,根据页面元素解析数据项
def parse(self, response):
all_texts = response.css('.text')
all_authors = response
Original: https://blog.csdn.net/sinat_38625964/article/details/115872318
Author: Liu还在努力中
Title: 【Scrapy + Elasticsearch 搜索引擎实战】(二)Scrapy爬虫框架
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/791074/
转载文章受原作者版权保护。转载请注明原作者出处!