

scrapy数据持久化存储(基于终端指令):
上节我们爬取到了内容,那么我们怎么做持久化存储呢?
直接在 parse方法中进行 with open() as f ?
如果是这样的话,那我们就没必要使用框架了。
scrapy框架中,我们封装好了持久化存储
import scrapy
class DuanziSpider(scrapy.Spider):
name = 'duanzi'
start_urls = ['https://duanzixing.com/段子/']
def parse(self, response):
article_list = response.xpath('/html/body/section/div/div/article')
for article in article_list:
title = article.xpath('./header/h2/a/@title').extract_first()
note = article.xpath('./p[2]/text()').extract_first()
这是我们上节课获取数据的爬虫文件源码,我们该怎样利用框架进行持久化存储 title和 note呢?
基于终端指令的持久化存储
- 这种方法的实现:该种方式只可以将parse方法的返回值存储到本地制定后缀的文本文件中。
- 执行指令:
scrapy crawl spiderName -o filePath
那么我们先创建个列表存储数据,并返回:
def parse(self, response):
all_data = []
article_list = response.xpath('/html/body/section/div/div/article')
for article in article_list:
title = article.xpath('./header/h2/a/@title').extract_first()
note = article.xpath('./p[2]/text()').extract_first()
dic = {
'title': title,
'note': note
}
all_data.append(dic)
return all_data
存储只需一条终端指令:
scrapy crawl duanzi -o duanzi.txt


我们发现报错了!~ 错误解释是 只能保存json、csv等格式文件
那么久来保存下csv格式的
scrapy crawl duanzi -o duanzi.csv
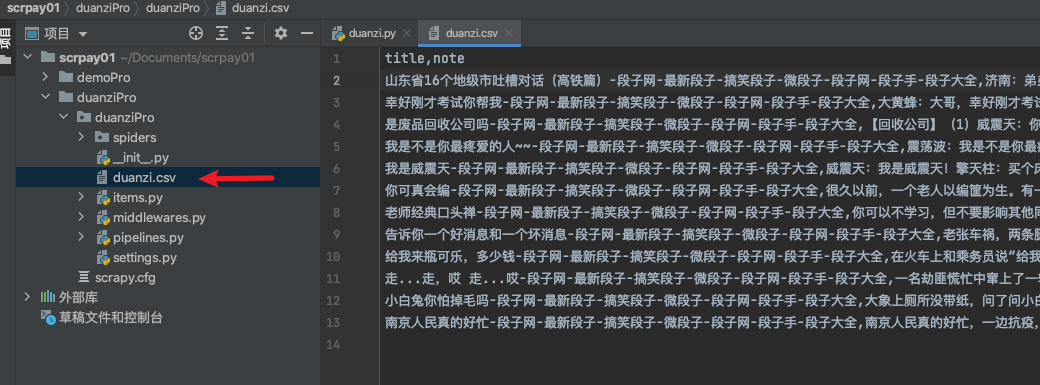
然后我们就看到保存成功了!.
关注 Python涛哥!学习更多Python知识!
Original: https://blog.csdn.net/tao5090694/article/details/120711959
Author: Python涛哥
Title: Python爬虫从入门到精通:(28)scrapy数据持久化存储(基于终端指令)_Python涛哥
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/791048/
转载文章受原作者版权保护。转载请注明原作者出处!