

第一章:scrapy入门知识与安装
入门知识
什么是scrapy
Scrapy 是一个快速、高效、异步多进程的高级网页抓取框架,用于抓取网站并从其页面中提取结构化数据。它有非常广泛的用途,包括从数据挖掘到监控和自动化测试等等。
运行流程图以及解释
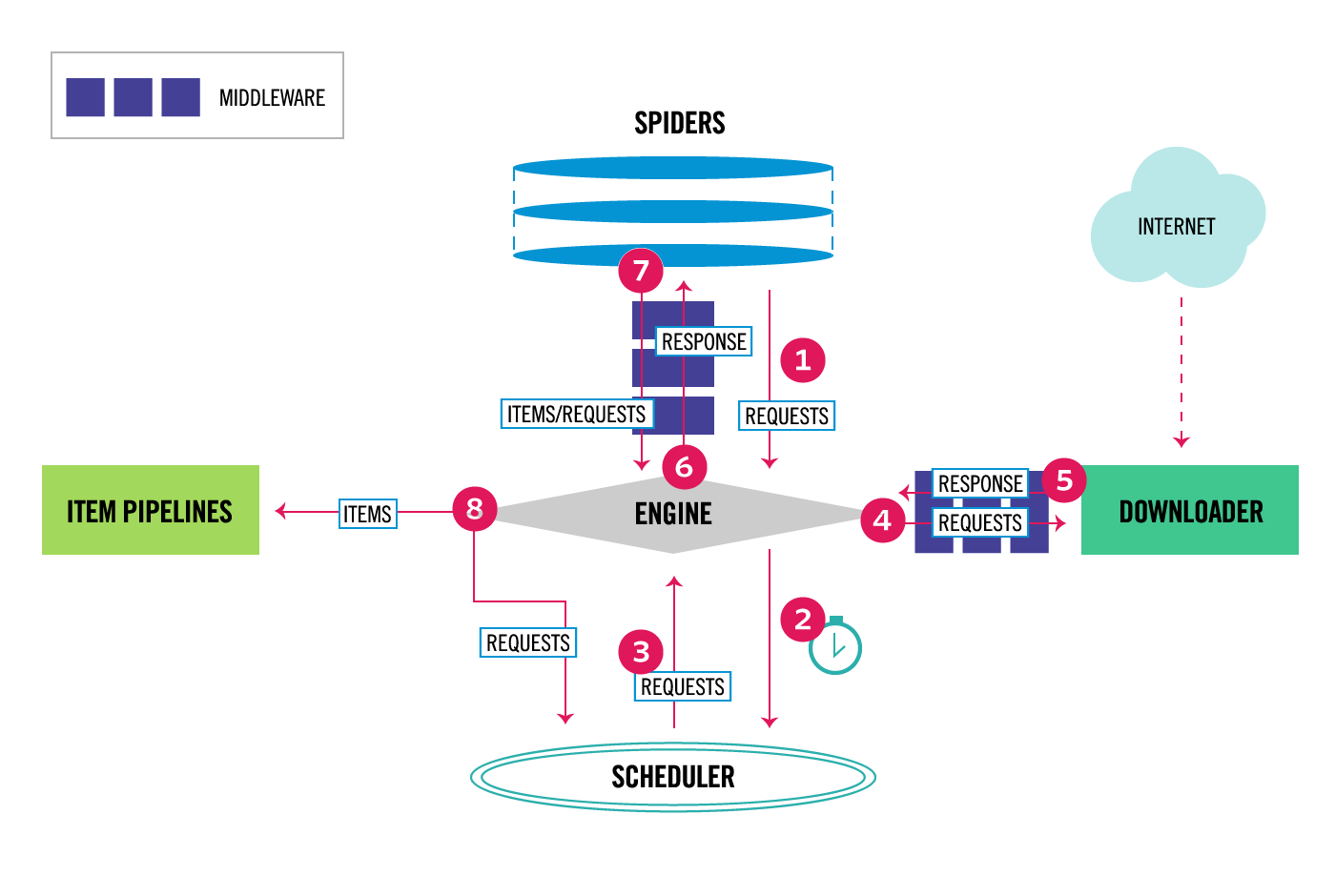

; 流程解析
Scrapy 中的数据流由引擎控制,运行流程如下所示:
- 引擎从
Spider中获取要抓取的初始请求。 - 引擎向调度器发送一个调度请求,并要求调度器返回一个请求对象(
url)。 - 调度器将准备好的请求对象返回给引擎。
- 引擎将请求发送到下载器,通过下载器中间件( process_request())下载该请求的内容。
- 一旦页面下载完成,下载器生成一个响应(带有页面内容)并将其发送到引擎,通过下载器中间件(参见 process_response())。
- 引擎从下载器接收响应并将其发送给Spider进行处理(处理的过程是用户自定义),通过Spider中间件(参见 process_spider_input())。
- Spider 处理响应,并将抓取的项目(结果)或新的请求(要跟踪的url)返回给引擎,通过 Spider 中间件(参见 process_spider_output())。
- 引擎将处理后的项目(结果)发送到项目管道进行结果的存储或使用。同时将处理后的请求发送到调度器,并询问是否有下一个请求需要继续爬取,如果有则重复1-8的动作。
注:该过程会一直重复(从第 1 步开始),直到再也没有来自调度器的请求而结束。
名词解释
1、引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。位于上图的最中心位置,也是scrapy框架的核心部件。
2、调度器(SCHEDULER)
调度器接收来自引擎的请求,并在引擎请求时将它们排入队列以便稍后(也给引擎)提供它们,可以认为是一个URL的队列, 队列的插入和取出由引擎操作, 同时调度器还会去除重复的网址。
3、下载器(DOWLOADER)
下载器负责获取网页并将获取的内容提供给引擎,然后引擎再将它们提供给spiders,下载器是建立在twisted这个高效的异步模型上的。
4、爬虫(SPIDERS)
Spiders 是由用户编写的自定义类,用于解析响应(responses)并从中提取项目或要遵循的其他请求。有关更多信息,请参阅spiders。
5、项目管道(ITEM PIPLINES)
一旦项目被Spider提取(或抓取),项目管道负责处理项目。典型的任务包括清理、验证和持久化(如将项目存储在数据库中)。有关更多信息,请参阅项目管道。
6、下载器中间件(Downloader Middlewares)
下载器中间件是位于引擎和下载器之间的特定挂钩,并在请求从引擎传递到下载器时处理请求,以及从下载器传递到引擎的响应。
如果您需要执行以下操作之一,请使用下载器中间件:
- 在请求发送到下载器之前处理请求(即在 Scrapy 将请求发送到网站之前);
- 在将其传递给 Spiders 之前更改收到的响应;
- 发送一个新的请求而不是将接收到的响应传递给 Spiders;
- 在不获取网页的情况下将响应传递给 Spiders;
- 静默的放弃一些请求。
有关更多信息,请参阅下载器中间件。
7、爬虫中间件(Spider Middlewares)
Spider 中间件是位于 Engine 和 Spider 之间的特定挂钩,能够处理 Spider 输入(响应)和输出(项目和请求)。
如果您需要执行以下操作之一,请使用 Spider 中间件:
- spider回调的后期处理输出 – 更改/添加/删除请求或项目;
- start_requests的后期处理;
- spider的异常处理;
- 根据响应内容为某些请求调用 errback 而不是回调。
有关更多信息,请参阅爬虫中间件。
驱动方式
Scrapy 是用 Twisted 编写的,这是一个流行的 Python 事件驱动网络框架。因此,它使用非阻塞(异步)代码实现并发。
scrapy的安装
Anaconda或Miniconda
如果你的开发环境已经安装了 Anaconda软件,那么安装过程将非常方便,我也推荐你尽量使用 Anaconda进行 python环境的搭建,因为它的确是非常方便的。
界面安装
如下图直接在所有包中搜索 scrapy,选中后进行安装即可

; 命令行安装
通过conda
conda install -c conda-forge scrapy
通过pip
pip install Scrapy
其他系统或非Anaconda安装方式
其他安装方式,来自scrapy官网:https://docs.scrapy.org/en/latest/intro/install.html
结束语
当scrapy包安装好了之后,下一步我们就将初始化一个项目,并介绍项目中各个文件的功能,同时我们将通过一个小例子来初步熟悉scrapy,感受scrapy的独特魅力。
Original: https://blog.csdn.net/silence_pinot/article/details/119915553
Author: 一眼青苔
Title: scrapy中文指南 第一章:scrapy入门知识与安装
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/790788/
转载文章受原作者版权保护。转载请注明原作者出处!