

前言
使用scrapy进行大型爬取任务的时候(爬取耗时以天为单位),无论主机网速多好,爬完之后总会发现scrapy日志中”item_scraped_count”不等于预先的种子数量,总有一部分种子爬取失败,失败的类型可能有如下图两种(下图为scrapy爬取结束完成时的日志):
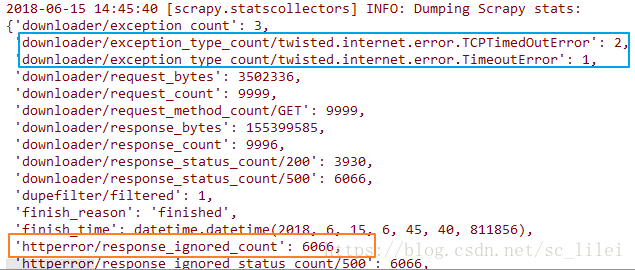

scrapy中常见的异常包括但不限于:download error(蓝色区域), http code 403/500(橙色区域)。
不管是哪种异常,我们都可以参考scrapy自带的retry中间件写法来编写自己的中间件。
正文
使用IDE,现在scrapy项目中任意一个文件敲上以下代码:
from scrapy.downloadermiddlewares.retry import RetryMiddleware
按住ctrl键,鼠标左键点击RetryMiddleware进入该中间件所在的项目文件的位置,也可以通过查看文件的形式找到该中间件的位置,路径是:site-packages/scrapy/downloadermiddlewares/retry.RetryMiddleware
该中间件的源代码如下:
class RetryMiddleware(object):
IOError is raised by the HttpCompression middleware when trying to
decompress an empty response
EXCEPTIONS_TO_RETRY = (defer.TimeoutError, TimeoutError, DNSLookupError,
ConnectionRefusedError, ConnectionDone, ConnectError,
ConnectionLost, TCPTimedOutError, ResponseFailed,
IOError, TunnelError)
def init(self, settings):
if not settings.getbool(‘RETRY_ENABLED’):
raise NotConfigured
self.max_retry_times = settings.getint(‘RETRY_TIMES’)
self.retry_http_codes = set(int(x) for x in settings.getlist(‘RETRY_HTTP_CODES’))
self.priority_adjust = settings.getint(‘RETRY_PRIORITY_ADJUST’)
@classmethod
def from_crawler(cls, crawler):
return cls(crawler.settings)
def process_response(self, request, response, spider):
if request.meta.get(‘dont_retry’, False):
return response
if response.status in self.retry_http_codes:
reason = response_status_message(response.status)
return self._retry(request, reason, spider) or response
return response
def process_exception(self, request, exception, spider):
if isinstance(exception, self.EXCEPTIONS_TO_RETRY) \
and not request.meta.get(‘dont_retry’, False):
return self._retry(request, exception, spider)
def _retry(self, request, reason, spider):
retries = request.meta.get(‘retry_times’, 0) + 1
retry_times = self.max_retry_times
if ‘max_retry_times’ in request.meta:
retry_times = request.meta[‘max_retry_times’]
stats = spider.crawler.stats
if retries
Original: https://blog.csdn.net/weixin_39782752/article/details/113513307
Author: weixin_39782752
Title: python捕获所有异常状态_如何在scrapy中捕获并处理各种异常
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/790621/
转载文章受原作者版权保护。转载请注明原作者出处!