

Scrapy教程经典实战【新概念英语】
前言
本教程旨在教会每一个想学习爬虫的人,学习的同时也能锻炼你阅读文档的习惯。
在本教程中,我们假设您的系统上已经安装了 Scrapy。如果不是这种情况,请参阅本小节下面环境配置。
我们将抓取http://www.yytingli.com/category/xgnyy/nce-1,这是一个新概念英语自学的网站。
本教程将引导您完成以下任务:
- 创建一个新的 Scrapy 项目
- 编写爬虫爬取网站并提取数据
- 使用命令行导出抓取的数据
- 将蜘蛛更改为递归跟踪链接
- 使用蜘蛛参数
请严格按照要求进行开发,以避免开发中的错误。
开发平台:windows
IDE:PyCharm 2021.3.2 (Professional Edition)
语言版本:Python==3.9
框架版本:Scrapy==2.6.1
一、网络爬虫介绍
📌随着互联网的快速发展,越来越多的信息被发布到互联网上。这些信息都被嵌入到各
式各样的网站结构及样式当中,虽然搜索引擎可以辅助人们寻找到这些信息,但也拥有其
局限性。通用的搜索引擎的目标是尽可能覆盖全网络,其无法针对特定的目的和需求进行
索引。面对如今结构越来越复杂,且信息含量越来越密集的数据,通用的搜索引擎无法对
其进行有效的发现和获取。在这样的环境和需求的影响下,网络爬虫应运而生,它为互联
网数据的应用提供了新的方法。
二、Scrapy框架介绍
Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pages. It can be used for a wide range of purposes, from data mining to monitoring and automated testing.
根据官网的介绍:
Scrapy是一个快速的高级网络抓取和网络爬虫框架,用于抓取网站并从其页面中提取结构化数据。它可以用于广泛的目的,从数据挖掘到监测和自动测试。
Scrapy框架是基础Python开发,所以不会Python的同学看这里:
https://www.runoob.com/python3/python3-tutorial.html
https://www.liaoxuefeng.com/wiki/1016959663602400
三、准备开发环境
四、创建Scrapy项目
首先打开命令行窗口,输出命令:
scrapy startproject newconcept
在当前目录会有创建好的文件,文件夹的树状结构如下:
newconcept
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │
│ │ __init__.py
│ │
│ └─__pycache__
│ myspider.cpython-39.pyc
│ __init__.cpython-39.pyc
│
└─__pycache__
items.cpython-39.pyc
settings.cpython-39.pyc
__init__.cpython-39.pyc
注意, __pycache__文件是pycharm自动生成的,不用管。
五、创建第一个蜘蛛
scrapy genspider myspider www.yytingli.com
运行过后,发现在项目文件夹中的 spider文件夹中会生成一个 myspider.py文件。
大概是这样的:
import scrapy
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['www.yytingli.com']
start_urls = ['http://www.yytingli.com']
def parse(self, response):
pass
我们要做的就是将pass去掉然后编写我们的逻辑代码即可, parse函数接收一个 response参数,这个参数就是网络请求的相应,我们只需要关心如何处理响应数据。
六、网页分析
网页分析分为两部分:
1.分析列表页,拿到详情页url。
2.分析详情页,爬取各部分数据。
我们使用Chrome浏览器打开新概念自学网站, F12打开开发者工具,并按 ctrl+shift+c 检查网页元素,点击标题。
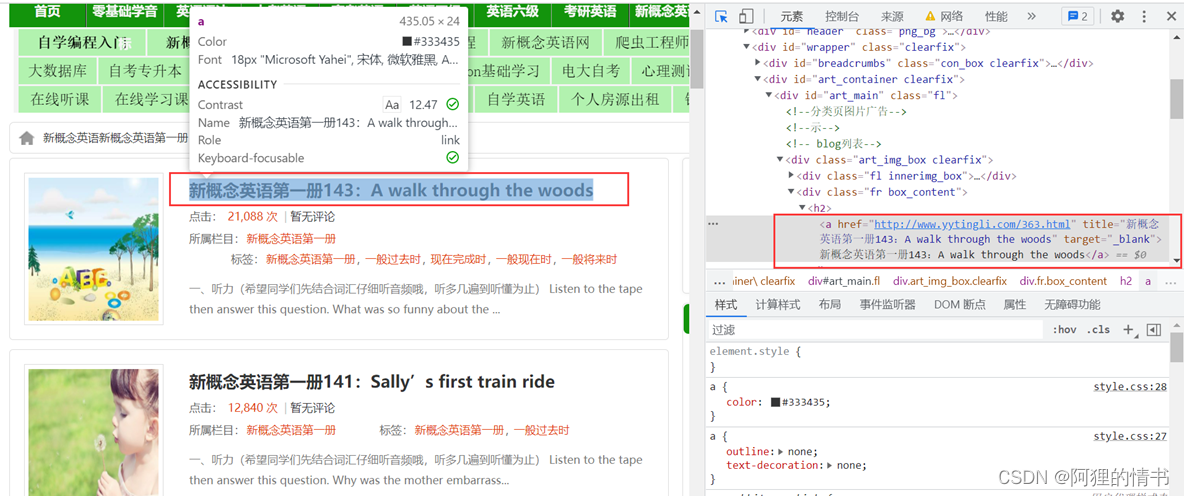

如上图,可以看到右边网页元素 a标签中的 href属性就是详情页的链接地址。
网页元素定位的方法有很多,可以使用 bs4库中的 find方法, select方法。可以用 xpath,可以用 pyquery,直接用 javascript操作 dom元素,还可以直接使用标准库 re,正则表达式来提取。
这里我们使用 xpath语句定位和解析元素。
元素定位和解析网页具体方法不是本教程的重点,这里可以参考:
这里给大家布置一个小作业,根据以上方法对详情页网页结构进行分析,并编写代码,网址为:http://www.yytingli.com/17.html,我们提取的信息只有两个,文章的英文文本和翻译内容。
; 七、列表页调试
首先需要修改 settings.py文件中的配置参数
找到 DEFAULT_REQUEST_HEADERS和 ROBOTSTXT_OBEY参数,改成如下:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9, */*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/96.0.4664.93 Safari/537.36',
}
ROBOTSTXT_OBEY = False
Scrapy提供一个shell命令行的调试方法,我们可以使用如下命令进入调试:
scrapy shell http://www.yytingli.com/category/xgnyy/nce-1
经过分析网页后,我们使用已经编写好的测试代码:
for i in response.xpath('// *[@id="art_main"]/div/div[2]/h2/a'):
title = i.xpath('@title').get()
link = i.xpath('@href').get()
print(title,link)
测试结果如下:
In [8]: for i in response.xpath('// *[@id="art_main"]/div/div[2]/h2/a'):
...: title = i.xpath('@title').get()
...: link = i.xpath('@href').get()
...: print(title,link)
...:
新概念英语第一册143:A walk through the woods http://www.yytingli.com/363.html
新概念英语第一册141:Sally's first train ride http://www.yytingli.com/360.html
新概念英语第一册139:Is that you, John? http://www.yytingli.com/357.html
新概念英语第一册137:A pleasant dream http://www.yytingli.com/354.html
新概念英语第一册135:The latest report http://www.yytingli.com/351.html
新概念英语第一册133:Sensational news http://www.yytingli.com/348.html
新概念英语第一册131:Don't be so sure http://www.yytingli.com/345.html
新概念英语第一册129:70 miles an hour http://www.yytingli.com/342.html
新概念英语第一册127:A famous actress http://www.yytingli.com/339.html
新概念英语第一册125:Tea for two http://www.yytingli.com/336.html
新概念英语第一册123:A trip to Australia http://www.yytingli.com/333.html
新概念英语第一册121:The man in the hat http://www.yytingli.com/330.html
新概念英语第一册119:A true story http://www.yytingli.com/327.html
新概念英语第一册117:Tommy's breakfast http://www.yytingli.com/323.html
新概念英语第一册115:Knock, knock! http://www.yytingli.com/320.html
新概念英语第一册113:small change http://www.yytingli.com/317.html
新概念英语第一册111:The most expensive model http://www.yytingli.com/314.html
新概念英语第一册109:A good idea http://www.yytingli.com/311.html
新概念英语第一册107:It's too small http://www.yytingli.com/308.html
新概念英语第一册105:Hello, Mr.boss http://www.yytingli.com/305.html
以上,我们拿到了详情页url和标题,完成列表页的测试。
八、详情页调试
我们可以使用如下命令进入调试:
scrapy shell http://www.yytingli.com/31.html
修改完毕后再次进入调试,我们使用已经编写好的测试代码:
text = response.xpath('// *[@id="art_main1"]/div[2]/p[6]/text()').getall()
translation = response.xpath('// *[@id="art_main1"]/div[2]/p[8]/text()').getall()
我们输入text查看结果,如下:
In [2]: text
Out[2]:
['My coat and my umbrella please.',
'\nHere is my ticket.',
'\nThank you, sir.',
'\nNumber five.',
"\nHere's your umbrella and your coat.",
'\nThis is not my umbrella.',
'\nSorry sir.',
'\nIs this your umbrella?',
"\nNo, it isn't.",
'\nIs this it?',
'\nYes, it is.',
'\nThank you very much.']
我们输入translation 查看结果,如下:
In [3]: translation
Out[3]:
['请把我的大衣和伞拿给我。',
'\n这是我(寄存东西)的牌子。',
'\n谢谢,先生。',
'\n是5号。',
'\n这是您的伞和大衣',
'\n这不是我的伞。',
'\n对不起,先生。',
'\n这把伞是您的吗?',
'\n不,不是!',
'\n这把是吗?',
'\n是,是这把。',
'\n非常感谢。']
以上完成了详情页的调试内容。
九、编辑条目文件
经过调试,我们已经成功拿到数据,此时应该编写 items.py文件,确定我们要爬取的内容。
import scrapy
class NewconceptItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
text = scrapy.Field()
translation = scrapy.Field()
十、完成爬虫代码
现在让我们完成 myspider.py文件。
import scrapy
from newconcept.items import NewconceptItem
class MyspiderSpider(scrapy.Spider):
name = 'myspider'
allowed_domains = ['www.yytingli.com']
start_urls = ['http://www.yytingli.com/category/xgnyy/nce-1']
def parse(self, response):
for i in response.xpath('// *[@id="art_main"]/div/div[2]/h2/a'):
item = NewconceptItem()
title = i.xpath('@title').get()
link = i.xpath('@href').get()
item['link'] = link
item['title'] = title
yield scrapy.Request(url=link, meta={'item': item}, callback=self.detail)
def detail(self, response):
item = response.meta['item']
text = response.xpath('// *[@id="art_main1"]/div[2]/p[6]/text()').getall()
translation = response.xpath('// *[@id="art_main1"]/div[2]/p[8]/text()').getall()
item['text'] = "".join(text).replace(' ', '').replace(':', '')
item['translation'] = "".join(translation).replace(' ', '').replace(':', '')
yield item
切换到项目路径使用命令运行:
scrapy crawl myspider -o mydata.json
程序完毕后会生成一个 mydata.json文件,里面就是我们想要的内容。
start_urls类属性是一个 list类型,它决定你刚开始爬取的 url列表,这里我们只用列表页的第一页进行爬取演示,如果你想爬取全部页内容,请将 start_urls参数改成如下:
start_urls = ['http://www.yytingli.com/category/xgnyy/nce-1']+['http://www.yytingli.com/category/xgnyy/nce-1/page/%s'%i for i in range(2, 4)]
查看文件部分内容如下:
...
{"link": "http://www.yytingli.com/348.html", "title": "\u65b0\u6982\u5ff5\u82f1\u8bed\u7b2c\u4e00\u518c133\uff1aSensational news", "text": "mink coat \u8c82\u76ae\u5927\u8863", "translation": "Reporter: Have you just made a new film, Miss Marsh?\nMiss Marsh: Yes, I have.\nReporter: Are you going to make another?\nMiss Marsh: No, I'm not. I'm going to retire. I feel very tired. I don't want to make another film for a long time."},
{"link": "http://www.yytingli.com/354.html", "title": "\u65b0\u6982\u5ff5\u82f1\u8bed\u7b2c\u4e00\u518c137\uff1aA pleasant dream", "text": "JULIE: Are you doing the football pools, Brain?\nBRAIN: Yes, I've nearly finished, Julie. I'm sure we'll win something this week.\nJULIE: You always say that, but we never win anything! What will you do if you win a lot of money?\nBRAIN: If I win a lot of money I'll buy you a mink coat.\nJULIE: I don't want a mink coat! I want to see the world.\nBRAIN: All right. If we win a lot of money we'll travel round the world and we'll stay at the best hotels. Then we'll return home and buy a big house in the country. We'll have a beautiful garden and...\nJULIE: But if we spend all that money we'll be poor again. What'll we do then?\nBRAIN: If we spend all the money we'll try and win the football pools again.\nJULIE: It's a pleasant dream but everything depends on 'if'!", "translation": "\u6731 \u8389\u5e03\u83b1\u6069\uff0c\u4f60\u6b63\u5728\u4e0b\u8db3\u7403\u8d5b\u7684\u8d4c\u6ce8\u5417\uff1f\n\u5e03\u83b1\u6069\u662f\u7684\u3002\u6211\u8fd9\u5c31\u505a\u5b8c\u4e86\uff0c\u6731\u8389\u3002\u6211\u6562\u80af\u5b9a\u8fd9\u661f\u671f\u6211\u4eec\u4f1a\u8d62\u4e00\u70b9\u4ec0\u4e48\u7684\u3002\n\u6731 \u8389\u4f60\u8001\u662f\u90a3\u6837\u8bf4\uff0c\u4f46\u662f\u6211\u4eec\u4ece\u6765\u6ca1\u8d62\u8fc7\uff01\u8981\u662f\u4f60\u8d62\u4e86\u8bb8\u591a\u94b1\uff0c\u4f60\u6253\u7b97\u505a\u4ec0\u4e48\u5462\uff1f\n\u5e03\u83b1\u6069\u8981\u662f\u6211\u8d62\u4e86\u8bb8\u591a\u94b1\uff0c\u6211\u7ed9\u4f60\u4e70\u4ef6\u8c82\u76ae\u5927\u8863\u3002\n\u6731 \u8389\u6211\u4e0d\u8981\u8c82\u76ae\u5927\u8863\u3002\u6211\u8981\u53bb\u89c1\u89c1\u4e16\u9762\u3002\n\u5e03\u83b1\u6069\u597d\u5427\u3002\u8981\u662f\u6211\u4eec\u8d62\u4e86\u5f88\u591a\u94b1\uff0c\u6211\u4eec\u5c31\u53bb\u5468\u6e38\u4e16\u754c\uff0c\u5e76\u4e14\u4f4f\u6700\u597d\u7684\u65c5\u9986\u3002\u7136\u540e\u6211\u4eec\u8fd4\u56de\u5bb6\u56ed\uff0c\u5728\u4e61\u4e0b\u4e70\u5e62\u5927\u623f\u5b50\u3002\u6211\u4eec\u5c06\u6709\u4e00\u4e2a\u6f02\u4eae\u7684\u82b1\u56ed\u548c......"},
{"link": "http://www.yytingli.com/357.html", "title": "\u65b0\u6982\u5ff5\u82f1\u8bed\u7b2c\u4e00\u518c139\uff1aIs that you, John?", "text": "GRAHAM TURNER: Is that you, John?\nJOHN SMITH: Yes, speaking.\nGRAHAM TURNER: Tell Mary we'll be late for dinner this evening.\nJOHN SMITH: I'm afraid I don't understand.\nGRAHAM TURNER: Hasn't Mary told you? She invited Charlotte and me to dinner this evening. I said I would be at your house at six o'clock, but the boss wants me to do some extra work. I'll have to stay at the office. I don't know when I'll finish. Oh, and by the way, my wife wants to know if Mary needs any help.\nJOHN SMITH: I don't know what you're talking about.\nGRAHAM TURNER: That is John Smith, isn't it?\nJOHN SMITH: Yes, I'm John Smith.\nGRAHAM TURNER: You are John Smith, the engineer, aren't you?\nJOHN SMITH: That's right.\nGRAHAM TURNER: You work for the Overseas Engineering Company, don't you?\nJOHN SMITH: No, I don't. I'm John Smith the telephone engineer and I'm repairing your telephone line.", "translation": "\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u662f\u4f60\u5417\uff0c\u7ea6\u7ff0\uff1f\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u662f\u6211\uff0c\u8bf7\u8bb2\u3002\n\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u4f60\u544a\u8bc9\u739b\u4e3d\uff0c\u4eca\u665a\u5403\u996d\u6211\u4eec\u5c06\u665a\u5230\u4e00\u4f1a\u513f\u3002\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u6050\u6015\u6211\u8fd8\u4e0d\u660e\u767d\u60a8\u7684\u610f\u601d\u3002\n\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u739b\u4e3d\u6ca1\u6709\u544a\u8bc9\u4f60\u5417\uff1f\u5979\u9080\u8bf7\u6211\u548c\u590f\u6d1b\u7279\u4eca\u665a\u53bb\u5403\u996d\u3002\u6211\u8bf4\u8fc7\u62116\u70b9\u5230\u4f60\u5bb6\uff0c\u4f46\u8001\u677f\u8981\u6211\u52a0\u73ed\u3002\u6211\u4e0d\u5f97\u4e0d\u7559\u5728\u529e\u516c\u5ba4\uff0c\u4e0d\u77e5\u9053\u4ec0\u4e48\u65f6\u5019\u624d\u80fd\u7ed3\u675f\u3002\u5594\uff0c\u987a\u4fbf\u95ee\u4e00\u53e5\uff0c\u6211\u59bb\u5b50\u60f3\u77e5\u9053\u739b\u4e3d\u662f\u5426\u9700\u8981\u5e2e\u5fd9\u3002\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u6211\u4e0d\u77e5\u9053\u60a8\u5728\u8bf4\u4e9b\u4ec0\u4e48\u3002\n\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u4f60\u662f\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\uff0c\u5bf9\u5417\uff1f\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u662f\u7684\uff0c\u6211\u662f\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u3002\n\u683c\u96f7\u5384\u59c6\uff0c\u7279\u7eb3\u4f60\u662f\u5de5\u7a0b\u5e08\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\uff0c\u5bf9\u5417\uff1f\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u5bf9\u3002\n\u683c\u96f7\u5384\u59c6\u00b7\u7279\u7eb3\u4f60\u5728\u6d77\u5916\u5de5\u7a0b\u516c\u53f8\u4e0a\u73ed\uff0c\u662f\u5417\uff1f\n\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\u4e0d\uff0c\u4e0d\u662f\u3002\u6211\u662f\u7535\u8bdd\u5de5\u7a0b\u5e08\u7ea6\u7ff0\u00b7\u53f2\u5bc6\u65af\uff0c\u6211\u6b63\u5728\u4fee\u7406\u60a8\u7684\u7535\u8bdd\u7ebf\u3002\n\n"},
无需担心title中的中文显示问题,使用专业工具读取,或者python读取即可正常显示。
你可以加入QQ群与大家一起学习交流,这里我会给你解答学习中的问题。
点击链接加入群聊【Python】:https://jq.qq.com/?_wv=1027&k=4fve4VeJ
Original: https://blog.csdn.net/qq_17802895/article/details/125587057
Author: 阿狸的情书
Title: Scrapy教程经典实战【新概念英语】
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/790459/
转载文章受原作者版权保护。转载请注明原作者出处!