

能看到这篇文章的人想必是有一定了解 scrapy的人,但是由于 redis_key非动态性以及不符合业务的 url拼接的原因,导致scrapy_redis对于某些业务非常不顺手,甚至不适应业务!!但是!!通过截胡修改源码的方式能够使得redis_key动态变化,并且url能够自由拼接~~必须点赞!!
一、咱们先来看看框架的简介
scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署。
有如下特征:
1、分布式爬取
您可以启动多个spider工程,相互之间共享单个redis的requests队列。最适合广泛的多个域名网站的内容爬取。
2、分布式数据处理
爬取到的scrapy的item数据可以推入到redis队列中,这意味着你可以根据需求启动尽可能多的处理程序来共享item的队列,进行item数据持久化处理
3、Scrapy即插即用组件
Scheduler调度器 + Duplication复制 过滤器,Item Pipeline,基本spider
4、scrapy-redis架构
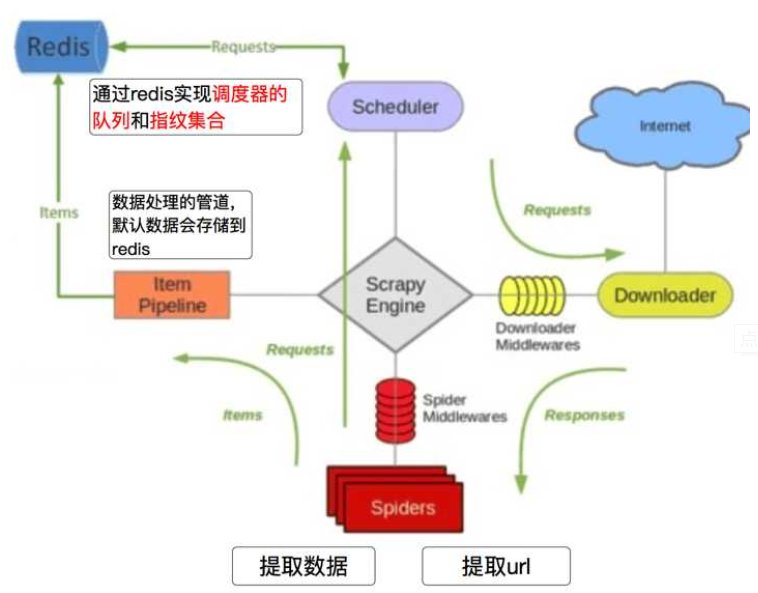

; 二、修改make_request_from_data方法
由于我的业务使用了很多redis,所以代码会比较多看起来会比较繁荣,但是都是有存在必要的,这个方法主要是为了拼接url以及获取到任务需要的参数
def make_request_from_data(self, data):
"""
重写make_request_from_data方法,data是scrapy-redis读取redis中的"'关键词||大词id||小词id'",然后发送get请求
:param data: redis中消息队列数据,是一个string
:yield: 一个Request对象
"""
if data == 1:
return "等待任务"
article_page = self.article_page
small_word = data.split("||")[0]
big_id = data.split("||")[1]
small_id = data.split("||")[2]
smallinfo = [(small_id, big_id, small_word, datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))]
self.cur.executemany(f"insert into {self.sql_dbname}.s_word(id, bid,s_keyword,create_time) values(%s,%s,%s,%s)",smallinfo)
self.conn.commit()
for page in range(article_page):
info = self.redis_db2.sismember(f"{self.sql_dbname}_None", f"No infos:{str(small_id)}")
if info:
self.redis_db2.srem(f"{self.sql_dbname}_None", f"No infos:{str(small_id)}")
print("删除并break")
break
url1 = f"https://www.alibaba.com/products/{small_word}.html?IndexArea=product_es&page={page}"
response1 = scrapy.Request(url=url1,meta={"big_id":big_id,"db_name": self.sql_dbname, "small_id": small_id, "small_word": small_word, "db_id": self.db_id},callback=self.parse)
yield response1
三、修改next_requests方法
这里是重点,为了适应动态的redis_key,从而修改的方法,也是本文的重中之重!!大家仔细看注释,一定要有耐心!!
def next_requests(self):
"""Returns a request to be scheduled or none."""
use_set = self.settings.getbool('REDIS_START_URLS_AS_SET', defaults.START_URLS_AS_SET)
fetch_one = self.server.spop if use_set else self.server.lpop
found = 0
for key in self.redis_db2.keys():
if "_task_info" in key:
db_name = key.rsplit('_', 2)[0]
pd, task_info = 0, ''
for key1 in self.redis_db1.keys():
if f'{db_name}_task_start' == key1:
pd = 1
if pd == 0:
self.sql_dbname = db_name
total = self.redis_db2.llen(f"{db_name}_task_start")
cc = list(self.redis_db2.smembers(f"{db_name}_task_state"))
if total and not cc:
totalinfo = {"total": total}
self.redis_db2.sadd(f"{db_name}_task_state", json.dumps(totalinfo))
self.Bigworlen = self.redis_db2.llen(f"{db_name}_task_start")
task_info = json.loads(list(self.redis_db2.smembers(key))[0])
if task_info:
article_engines = task_info["article_engines"]
if article_engines == "Alibaba":
self.article_page = task_info["article_page"]
self.db_id = task_info["db_id"]
self.redis_key = f"{self.sql_dbname}_task_start"
self.redis_batch_size = self.Bigworlen
if not self.Bigworlen:
req = self.make_request_from_data(1)
return req
while found < self.redis_batch_size:
data = fetch_one(self.redis_key)
if not data:
req = self.make_request_from_data(1)
return req
break
data = bytes.decode(data)
req = self.make_request_from_data(data)
if req:
return req
found += 1
else:
self.logger.debug("请求不是从数据发出的: %r")
if found:
self.logger.debug("Read %s requests from '%s'", found, self.redis_key)
四、修改start_requests方法
这个方法主要是拿来初始化数据库链接
def start_requests(self):
"""Returns a batch of start requests from redis."""
self.conn = pymysql.connect(host='r.aliyuncs.com', user='root',password='C', charset='utf8')
self.cur = self.conn.cursor()
self.redis_db1 = redis.Redis(host='r.aliyuncs.com', port=6379,password='8', db=1, decode_responses=True, encoding="utf-8",errors='ignore')
self.redis_db2 = redis.Redis(host='r.aliyuncs.com', port=6379,password='8', db=2, decode_responses=True, encoding="utf-8",errors='ignore')
self.sql_dbname, self.Bigworlen, self.article_page, self.db_id = '', 0, '', ''
return self.next_requests()
五、然后就可以打包成docker镜像扔k8s了,美滋滋

当然还有不会的朋友可以加群交流,然后点个赞吧,给点动力!!~~
Original: https://blog.csdn.net/pengshengege/article/details/112170821
Author: 鹏神哥哥
Title: Python截胡修改scrapy-redis适应动态redis_key,自由拼接url!!
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/790217/
转载文章受原作者版权保护。转载请注明原作者出处!