

scrapy基本操作
-
基本介绍:基于异步爬虫的框架。高性能的数据解析,高性能的持久化存储,全站数据爬取,增量式,分布式…
-
环境的安装:
-
Linux:
pip install scrapy
- Windows:
a. pip install wheel
b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
- twisted插件是scrapy实现异步操作的三方组件。
c. 进入下载目录,执行 pip install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl
d. pip install pywin32
e. pip install scrapy
- scrapy基本使用
- 1.创建一个工程: scrapy startproject proName


- 工程的目录结构:
- spiders文件夹: 这里存放爬虫的主程序,这里可以写多个爬虫文件,分别执行不同的爬虫功能。
- 要求:必须要存储一个或者多页爬虫文件
- items.py: 这个文件定义了爬虫程序中爬取的字段信息,对应着数据库中的属性信息。
- middlewares.py: 下载中间件,可以对爬取到的网页信息尽心特定的处理。
- pipelines.py: 管道,也就是将返回来的item字段信息写入到数据库,这里可以写写入数据库的代码。
- settings.py: 配置文件。
- 2.创建爬虫文件
- cd proName
- scrapy genspider spiderName www.xxx.com
- 3.执行工程
- scrapy crawl spiderName
- 重点关注的日志信息:ERROR类型的日志信息
- settings.py:LOG_LEVEL = ‘ERROR’
- settings.py:不遵从robots协议
- settings.py:
- UA伪装:USER_AGENT = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36’
settings.py代码参考以及配置意思的含义:
BOT_NAME = 'vx_account'
FEED_EXPORT_ENCODING = 'utf-8'
SPIDER_MODULES = ['vx_account.spiders']
NEWSPIDER_MODULE = 'vx_account.spiders'
USER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
ROBOTSTXT_OBEY = False
LOG_LEVEL = 'ERROR'
数据解析
- 数据解析
- 使用xpath进行数据解析
- 注意:使用xpath表达式解析出来的内容不是直接为字符串,而是Selector对象,想要的
字符串数据是存储在该对象中。
- extract():如果xpath返回的列表元素有多个
- extract_first():如果xpath返回的列表元素只有一个
首先我们来看看 我们要爬的网页

小知识点:
- 数据解析
- 使用xpath进行数据解析
- 注意:使用xpath表达式解析出来的内容不是直接为字符串,而是Selector对象,想要的
字符串数据是存储在该对象中。
- extract():如果xpath返回的列表元素有多个
- extract_first():如果xpath返回的列表元素只有一个
打开spiders文件夹下爬虫文件
wechat/wechat/spiders/wechatspider.py
代码如下:
import scrapy
class WechatspiderSpider(scrapy.Spider):
name = 'wechatspider'
allowed_domains = ['mp.weixin.qq.com/s/kfIAZmK5bAOMHuuHnL_ZMw']
start_urls = ['http://mp.weixin.qq.com/s/kfIAZmK5bAOMHuuHnL_ZMw']
def parse(self, response):
all_list = []
course_list = response.xpath('//*[@id="js_content"]/section')
for i in course_list:
course_title = i.xpath('.//span//text()').extract_first()
course_url = i.xpath('.//@href').extract_first()
print(course_url)
print(course_title)
if course_title:
dic = {
'course_title': course_title,
'course_url': course_url
}
all_list.append(dic)
return all_list
持久化存储
- 持久化存储
- 基于终端指令的持久化存储
- 只可以将parse方法的返回值存储到制定后缀的文本文件中
- 局限性:
- 1.只可以将parse方法返回值进行持久化存储
- 2.只可以将数据存储到文件中无法写入到数据库
- 指令:scrapy crawl spiderName -o filePath
- 基于管道的持久化存储
- 1.在爬虫文件中进行数据解析
- 2.在items.py文件中定义相关的属性
- 属性的个数要和解析出来的字段个数同步
- 3.将解析出来的数据存储到item类型的对象中
- 4.将item提交给管道
- 5.在管道中接收item对象且将该对象中存储的数据做任意形式的持久化存储
- 6.在配置文件中开启管道机制
- 基于终端指令的持久化存储
cd 项目文件下
用命令把爬取课程名和url地址存在本地
scrapy crawl wechatspider -o qwq.csv

- 基于管道的持久化存储
1.spider文件下得爬虫文件wechatspider.py
import scrapy
from wechat.wechat.items import WechatItem
class WechatspiderSpider(scrapy.Spider):
name = 'wechatspider'
allowed_domains = ['mp.weixin.qq.com/s/kfIAZmK5bAOMHuuHnL_ZMw']
start_urls = ['http://mp.weixin.qq.com/s/kfIAZmK5bAOMHuuHnL_ZMw']
def parse(self, response):
all_list = []
course_list = response.xpath('//*[@id="js_content"]/section')
for i in course_list:
course_title = i.xpath('.//span//text()').extract_first()
course_url = i.xpath('.//@href').extract_first()
print(course_url)
print(course_title)
item = WechatItem()
item['course_title'] = course_title
item['course_url'] = course_url
yield item
2.items.py代码
import scrapy
class WechatItem(scrapy.Item):
course_url = scrapy.Field()
course_title = scrapy.Field()
3.去settings里开启管道配置。
- 300:表示管道的优先级,数值越小优先级越高,优先级越高表示该管道越先被执行
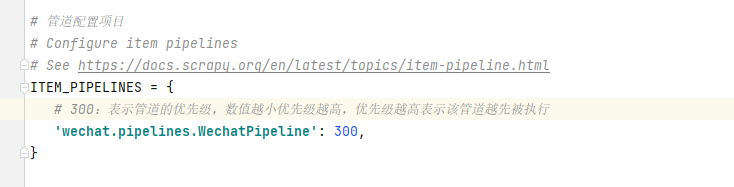
4.1 封装管道类,把数据储存到txt文件里 ; pipelines.py代码:
from itemadapter import ItemAdapter
class WechatPipeline:
fp = None
def open_spider(self, spider):
print('i am open_spider()')
self.fp = open('./qwq.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
course_url = item['course_url']
course_title = item['course_title']
self.fp.write(course_url + ':' + course_title)
return item
def close_spider(self, spider):
print('i am close_spider()')
self.fp.close()
4.1 封装管道类,把数据储存到mysql里 ; pipelines.py代码:
,我比较懒,不喜写SQL语句,用sqlalchemy来处理的。
mysql 创建库:
create database wechat charset utf8mb4;
cd spiderst同级目录下
mkdir docs
新建models.py:
from sqlalchemy import Column, String, DateTime, Boolean, create_engine, Integer, Text, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy.ext.declarative import declarative_base
from alembic import op
Base = declarative_base()
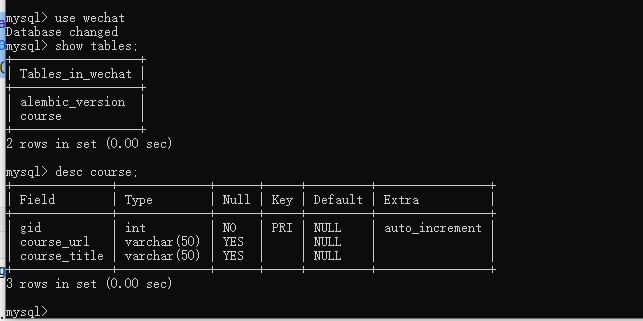
class Course(Base):
__tablename__ = 'course'
gid = Column(Integer(), primary_key=True, comment='主键ID')
course_url = Column(String(5000), comment="课程url")
course_title = Column(String(50), comment='课程标题!')
执行命令:
alembic init migrations

修改alembic.ini、enc.py代码 ,参考:https://blog.csdn.net/yutu75/article/details/117362459
也可以自行百度如何迁移,
alembic revision –autogenerate -m “v1”

alembic upgrade head

去settings添加管道:

修改pipelines.py,代码:
下面封装了三个管道类:
txt文件,mysql,Redis
from wechat.docs.models import Course
from sqlalchemy import Column, String, DateTime, Boolean, create_engine, Integer, Text, ForeignKey
from sqlalchemy.orm import sessionmaker, relationship
import pandas as pd
import pymysql
import redis
from itemadapter import ItemAdapter
class MysqlPipeline:
engine = None
Session = None
session = None
def open_spider(self, spider):
self.engine = create_engine('mysql+pymysql://root:123456@127.0.0.1:3306/wechat', echo=True)
self.Session = sessionmaker(bind=self.engine)
print(self.engine)
def process_item(self, item, spider):
course_url = item['course_url']
course_title = item['course_title']
self.session = self.Session()
print('qwq')
try:
new_page = Course(course_title=course_title, course_url=course_url)
self.session.add(new_page)
self.session.commit()
except Exception as e:
print(e)
self.session.rollback()
return item
def close_spider(self, spider):
self.session.close()
class WechatPipeline:
fp = None
def open_spider(self, spider):
print('i am open_spider()')
self.fp = open('./qwq.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
course_url = item['course_url']
course_title = item['course_title']
if course_url is not None or course_title is not None:
self.fp.write([course_title if course_title is not None else 'null'][0] + ':' + [course_url if course_url is not None else 'null'][0] + '\n')
return item
def close_spider(self, spider):
print('i am close_spider()')
self.fp.close()
class redisPipeLine:
conn = None
def open_spider(self,spider):
self.conn = redis.Redis(host='192.168.152.128', port=6379)
def process_item(self,item,spider):
course_url = item['course_url']
course_title = item['course_title']
if course_url is not None or course_title is not None:
self.conn.lpush('wechat', [course_title if course_title is not None else 'null'][0] + ':' + [course_url if course_url is not None else 'null'][0])
return item
执行命令 :
scrapy crwal wechatspider
储存后的mysql:

储存后的redis:

储存后txt:

持久化储存的知识点总结
- 持久化存储
- 基于终端指令的持久化存储
- 只可以将parse方法的返回值存储到制定后缀的文本文件中
- 局限性:
- 1.只可以将parse方法返回值进行持久化存储
- 2.只可以将数据存储到文件中无法写入到数据库
- 指令:scrapy crawl spiderName -o filePath
- 基于管道的持久化存储
- 1.在爬虫文件中进行数据解析
- 2.在items.py文件中定义相关的属性
- 属性的个数要和解析出来的字段个数同步
- 3.将解析出来的数据存储到item类型的对象中
- 4.将item提交给管道
- 5.在管道中接收item对象且将该对象中存储的数据做任意形式的持久化存储
- 6.在配置文件中开启管道机制
- 管道细节处理
- 在配置文件中,管道对应的数值表示的是优先级
- 什么情况下需要使用多个管道类?
- 数据备份。一个管道类表示将数据存储到一种形式的载体中。
- 想要将数据存储到mysql一份,redis一份,需要有两个管道类来实现。
- 小知识点:
- 爬虫文件向管道提交的item只会提交给优先级最高的那一个管道类
- proces_item方法中的return item的作用?
- 将item对象提交给下一个即将被执行的管道类
redis的基础使用
- redis数据库的使用
- redis是一个非关系型数据库
- 查看所有数据:keys *
- 删除所有数据:flushall
- set集合:
- 插入数据sadd 集合的名称 存储的值
- 查看数据:smembers 集合的名称
- set集合可以去重
- list列表
- 插入数据:lpush 列表的名称 插入的值
- 查看数据:lrange 列表名称 0 -1
- 查看长度:llen 列表名称
- 可以存储重复的数据
- 在redis官网中下载安装redis数据库
- 1.启动redis的服务器端
- redis-server
- 2,启动客户端
- redis-cli
全站数据爬取
- 全站数据爬取
- 将所有页码对应的数据进行爬取+存储
- 手动请求发送:
- 通过代码的形式进行请求发送
- yield scrapy.Request(url,callback):
- 可以对指定url发起get请求,回调callback进行数据解析
- 手动发起post请求:
- yield scrapy.FormRequest(url,formdata,callback)
- 问题:start_urls列表中的url是如何发起post请求?
重写父类如下方法即可:
def start_requests(self):
for url in self.start_urls:
yield scrapy.FormRequest(url=url,callback=self.parse)
Original: https://blog.csdn.net/yutu75/article/details/117445689
Author: 於 兔シ
Title: scrapy爬取微信公众号内容,多管道储存,orm数据储存
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/790052/
转载文章受原作者版权保护。转载请注明原作者出处!