

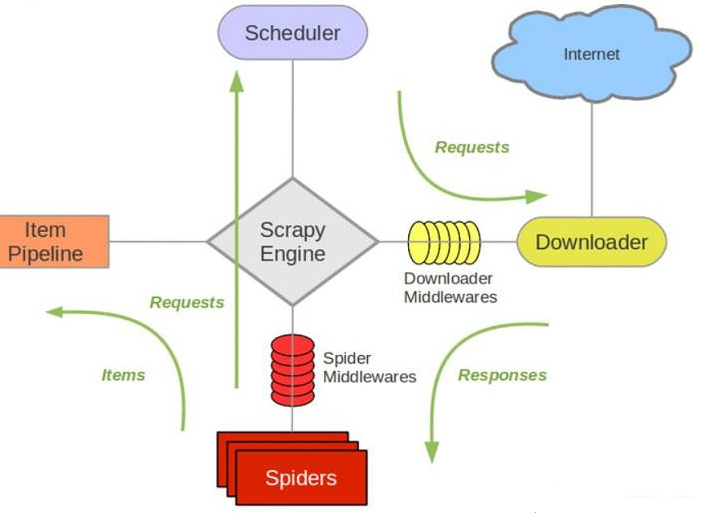

crawl spider继承Spider类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(Rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合,也可以重写一些方法来实现特定的功能。简单来说就是简单高效的爬取一些url比较固定的网址
This is the most commonly used spider for crawling regular websites, as it provides a convenient mechanism for following links by defining a set of rules. It may not be the best suited for your particular web sites or project, but it’s generic enough for several cases, so you can start from it and override it as needed for more custom functionality, or just implement your own spider.
Rule使用参数:
Rule(link_extractor=None, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None, errback=None)
官方文档如下:
Spiders — Scrapy 2.5.1 documentation
案列:
1.创建项目:在scrapy安装目录下打开cmd窗口 执行 scrapy startproject pigyitong
2.创建一个crawlspider爬虫 scrapy genspider -t crawl pig "bj.zhue.com.cn"
https://bj.zhue.com.cn/search_list.php?sort=&pid=22&s_id=19&cid=2209&county_id=0&mid=&lx=&page=1 目标网址
由于发布作品的规范要求,这里只列出几个主要项目文件代码:
pig.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from pigyitong.items import PigyitongItem
class PigSpider(CrawlSpider):
name = 'pig'
allowed_domains = ['bj.zhue.com.cn']
start_urls = ['https://bj.zhue.com.cn/search_list.php?sort=&pid=22&s_id=19&cid=2209&county_id=0&mid=&lx=&page=1']
rules = (
Rule(LinkExtractor(allow=r'.*?sort=&pid=22&s_id=19&cid=2209&county_id=0&mid=&lx=&page=\d'),
follow=False, callback='parse_item'),)
def parse_item(self, response):
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
tr = response.xpath('//tr[@bgcolor="#efefef"]/../tr')
for i in tr[2:]:
date = i.xpath('./td[1]/a/text()').get()
province = i.xpath('./td[2]/a/text()').get()
region = i.xpath('./td[3]/a/text()').get()
p_name = i.xpath('./td[4]/a/text()').get()
species = i.xpath('./td[5]/a/text()').get()
price = i.xpath('./td[6]//li/text()').get()
item = PigyitongItem(data=date, province=province, region=region, p_name=p_name, species=species, price=price)
yield item
pipelines.py
from itemadapter import ItemAdapter
from scrapy.exporters import JsonLinesItemExporter
class PigyitongPipeline:
def __init__(self):
self.f = open('猪易通.json', mode='wb')
self.export = JsonLinesItemExporter(self.f, ensure_ascii=False, encoding='utf-8')
def open_spider(self, spider):
pass
def process_item(self, item, spider):
self.export.export_item(item)
return item
def close_spider(self, spider):
self.f.close()
item.py
import scrapy
class PigyitongItem(scrapy.Item):
data = scrapy.Field()
province = scrapy.Field()
region = scrapy.Field()
p_name = scrapy.Field()
species = scrapy.Field()
price = scrapy.Field()
setting文件正常设置就好
没毛病!
Original: https://blog.csdn.net/zm024212/article/details/120628757
Author: Hill.
Title: scrapy框架之crawl spider
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789953/
转载文章受原作者版权保护。转载请注明原作者出处!