

Scrapy源码阅读记录
文章目录
因为爬虫需求比较特殊(毕设要做社交网络相关的内容),网上的博客写的都比较拉,互相抄来抄去,找不到有用的东西,只好去啃源码。
主要围绕着 scrapy.core包,具体流程就是从爬虫运行的顺序开始分析,各个从上至下基本上是按顺序来的。
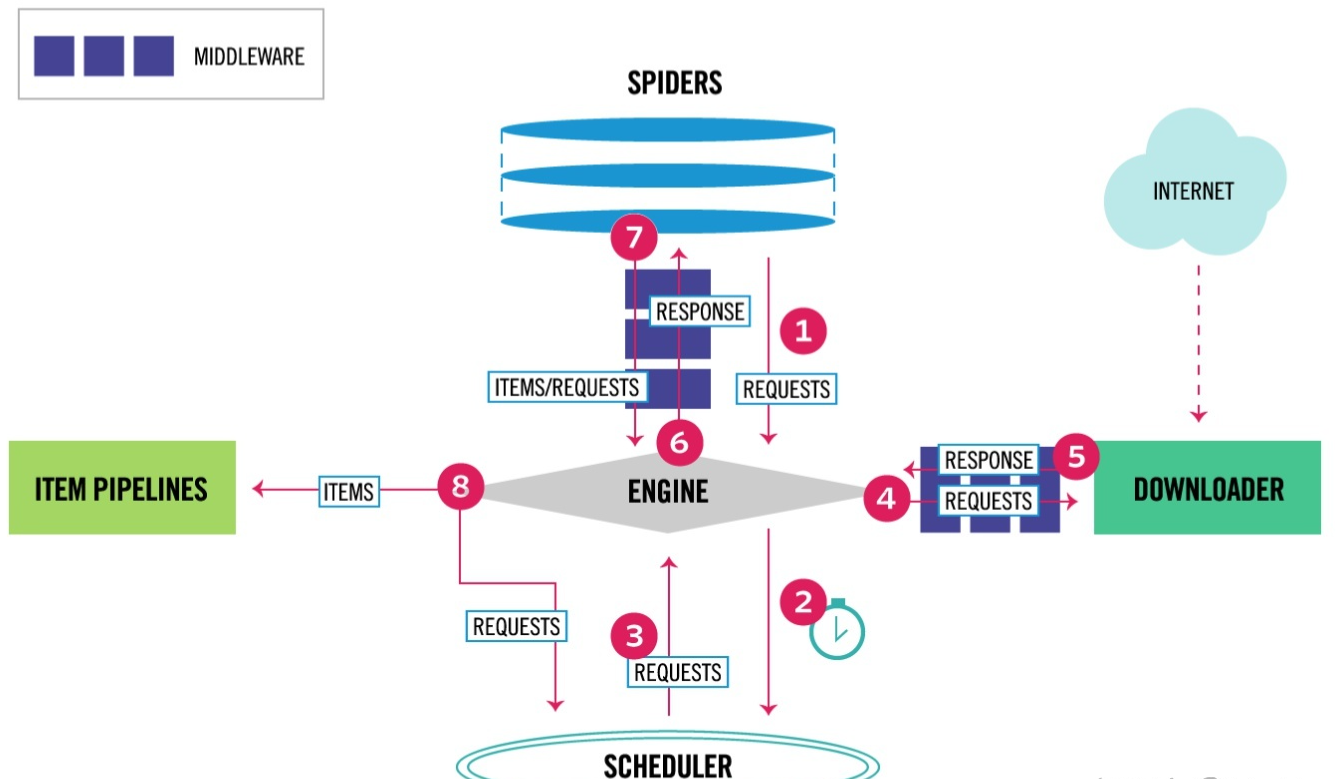

; 爬虫启动
这部分没找到详细的流程,大致是执行了 scrapy.cmdline的 execute方法。
Crawler类
职责
这个类负责初始启动scrapy的2个部件,包括 engine、 用户自定义的spider
此外还提供一个CrawlRunner类给用户做参考,让用户可以自定义爬虫爬取的调度方法
主要方法
- 构造方法 从settings.py读取各种有关设置,并通过反射设置日志、统计数据。
- crawl方法
@defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
self.spider = self._create_spider(*args, **kwargs)
self.engine = self._create_engine()
start_requests = iter(self.spider.start_requests())
yield self.engine.open_spider(self.spider, start_requests)
yield defer.maybeDeferred(self.engine.start)
except Exception:
if six.PY2:
exc_info = sys.exc_info()
self.crawling = False
if self.engine is not None:
yield self.engine.close()
if six.PY2:
six.reraise(*exc_info)
raise
def _create_spider(self, *args, **kwargs):
return self.spidercls.from_crawler(self, *args, **kwargs)
def _create_engine(self):
return ExecutionEngine(self, lambda _: self.stop())
Engine类
职责
这个类负责各种调度,包括request的出入、response的出入等。
主要方法
- 构造方法 设置了 crawler(这里的crawler就是上面提到过的Crawler类对象的引用)和engine的状态,以及从settings.py读取设置来生成相应的 scheduler的配置(注意是配置,scheduler对应的队列啥的还没配套)、 downloader,以及处理parse函数响应返回的 Item和 Request的 Scraper类对象
- open_spider方法
@defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
assert self.has_capacity(), "No free spider slot when opening %r" % \
spider.name
logger.info("Spider opened", extra={'spider': spider})
nextcall = CallLaterOnce(self._next_request, spider)
scheduler = self.scheduler_cls.from_crawler(self.crawler)
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
yield scheduler.open(spider)
yield self.scraper.open_spider(spider)
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
slot.nextcall.schedule()
slot.heartbeat.start(5)
- _next_requests方法 非常重要,这个方法写明了start_requests里面的请求和parse函数里面的请求有何不同。
def _next_request(self, spider):
slot = self.slot
if not slot:
return
if self.paused:
return
while not self._needs_backout(spider):
if not self._next_request_from_scheduler(spider):
break
"""
如果start_requests里面还有请求并且downloder、scraper还能承受
一般来说如果队列不空而是刚刚塞满,是不会执行下面这个if里面的内容的,因为网络延迟比cpu处理慢太多了
"""
if slot.start_requests and not self._needs_backout(spider):
try:
request = next(slot.start_requests)
except StopIteration:
slot.start_requests = None
except Exception:
slot.start_requests = None
logger.error('Error while obtaining start requests',
exc_info=True, extra={'spider': spider})
else:
self.crawl(request, spider)
if self.spider_is_idle(spider) and slot.close_if_idle:
self._spider_idle(spider)
def _needs_backout(self, spider):
"""
当爬虫在运行、没有关闭、downloader和scraper还能继续往处理队列种塞东西的时候,返回False
"""
slot = self.slot
return not self.running \
or slot.closing \
or self.downloader.needs_backout() \
or self.scraper.slot.needs_backout()
def crawl(self, request, spider):
assert spider in self.open_spiders, \
"Spider %r not opened when crawling: %s" % (spider.name, request)
self.schedule(request, spider)
self.slot.nextcall.schedule()
def schedule(self, request, spider):
self.signals.send_catch_log(signal=signals.request_scheduled,
request=request, spider=spider)
if not self.slot.scheduler.enqueue_request(request):
self.signals.send_catch_log(signal=signals.request_dropped,
request=request, spider=spider)
- _next_request_from_scheduler方法 从scheduler的队列中取得下一个Request
def _next_request_from_scheduler(self, spider):
slot = self.slot
request = slot.scheduler.next_request()
if not request:
return
d = self._download(request, spider)
d.addBoth(self._handle_downloader_output, request, spider)
d.addErrback(lambda f: logger.info('Error while handling downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.remove_request(request))
d.addErrback(lambda f: logger.info('Error while removing request from slot',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
d.addBoth(lambda _: slot.nextcall.schedule())
d.addErrback(lambda f: logger.info('Error while scheduling new request',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
return d
def _handle_downloader_output(self, response, request, spider):
assert isinstance(response, (Request, Response, Failure)), response
if isinstance(response, Request):
self.crawl(response, spider)
return
d = self.scraper.enqueue_scrape(response, request, spider)
d.addErrback(lambda f: logger.error('Error while enqueuing downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': spider}))
return d
def _download(self, request, spider):
slot = self.slot
slot.add_request(request)
def _on_success(response):
assert isinstance(response, (Response, Request))
if isinstance(response, Response):
response.request = request
logkws = self.logformatter.crawled(request, response, spider)
logger.log(*logformatter_adapter(logkws), extra={'spider': spider})
self.signals.send_catch_log(signal=signals.response_received, \
response=response, request=request, spider=spider)
return response
def _on_complete(_):
slot.nextcall.schedule()
return _
dwld = self.downloader.fetch(request, spider)
dwld.addCallbacks(_on_success)
dwld.addBoth(_on_complete)
return dwld
Scraper类
职责
处理spider的IO,包括进入spider和从spider出来的数据,可以视作 spidermiddleware的控制器
主要方法
- _scrape_next方法
def _scrape_next(self, spider, slot):
while slot.queue:
response, request, deferred = slot.next_response_request_deferred()
self._scrape(response, request, spider).chainDeferred(deferred)
def _scrape(self, response, request, spider):
"""Handle the downloaded response or failure through the spider
callback/errback"""
assert isinstance(response, (Response, Failure))
dfd = self._scrape2(response, request, spider)
dfd.addErrback(self.handle_spider_error, request, response, spider)
dfd.addCallback(self.handle_spider_output, request, response, spider)
return dfd
- handle_spider_output方法 比较重要,这里可以了解到为什么parse函数能够一口气处理很多的Request和item。
def handle_spider_output(self, result, request, response, spider):
if not result:
return defer_succeed(None)
it = iter_errback(result, self.handle_spider_error, request, response, spider)
dfd = parallel(it, self.concurrent_items,
self._process_spidermw_output, request, response, spider)
return dfd
def _process_spidermw_output(self, output, request, response, spider):
"""Process each Request/Item (given in the output parameter) returned
from the given spider
"""
if isinstance(output, Request):
self.crawler.engine.crawl(request=output, spider=spider)
elif isinstance(output, (BaseItem, dict)):
self.slot.itemproc_size += 1
dfd = self.itemproc.process_item(output, spider)
dfd.addBoth(self._itemproc_finished, output, response, spider)
return dfd
elif output is None:
pass
else:
typename = type(output).__name__
logger.error('Spider must return Request, BaseItem, dict or None, '
'got %(typename)r in %(request)s',
{'request': request, 'typename': typename},
extra={'spider': spider})
结论
Scrapy的start_requests方法相当于森林中所有树的根,当爬完第一棵树的时候才会考虑进行下一棵树的爬取。因此,对于后续的爬取存在循环回调且树根的优先级比循环爬取的节点更高的时候,应该考虑利用parse函数处理yield的特性,将森林中所有的根节点先以一定的优先级加入scheduler的队列中,避免出现吊死在一颗树上的情况。
更通俗的说
scrapy的start_requests里面如果有循环发送请求的情况,实际上scrapy是不会先执行完start_requests的,也就是说里面写了
def start_requests(self):
for url in urls:
yield Request(url=url)
像这样的代码,scheduler的队列中并不会存在urls中所有的请求!这是个大坑
Original: https://blog.csdn.net/deltapluskai/article/details/113919109
Author: deltapluskai
Title: 关于Scrapy的start_requests中的所有Requests不一口气加入请求队列这件事
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789951/
转载文章受原作者版权保护。转载请注明原作者出处!