

逆向爬虫18 Scrapy抓取全站数据和Redis入门
一、全站数据抓取
1. 什么是抓取全站数据?
我们曾经在过猪八戒,图片之家,BOSS直聘等网站,利用网站官方提供的搜索功能,搜索指定关键词的内容,并把这些内容都抓取下来。现在我们来总结一下这些网站信息的共同点。
1. 利用浏览器访问指定网站,并在官方的搜索栏中搜索想要的内容信息。
2. 服务器返回一系列页面列表,每个页面内包含着若干条被搜索内容的简介信息。
3. 逐条点击这些简介信息的网页链接就可以获得该条信息的详情内容。
4. 对服务器返回的每个页面列表均执行步骤3,直到页面列表全都遍历完成。
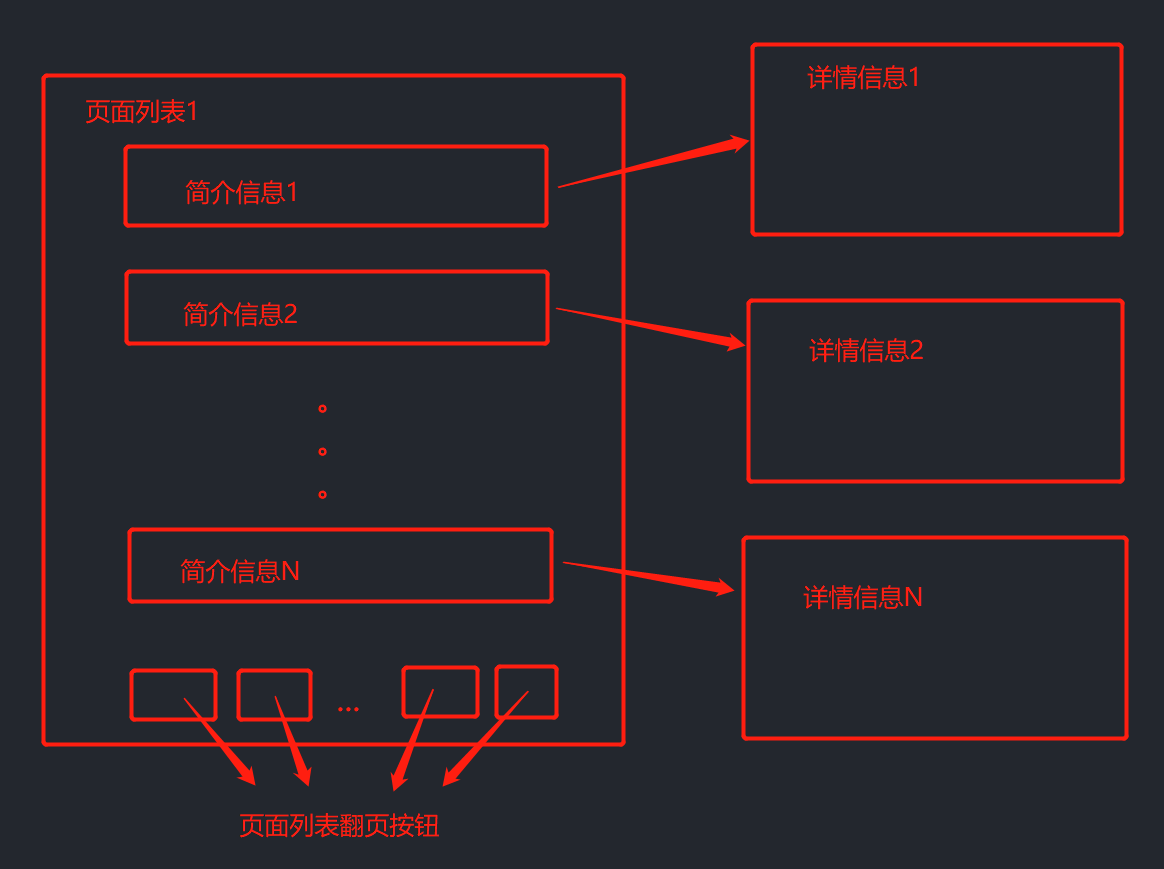

上图描述了全站数据抓取的基本模型,这个是个可以应用于很多网站,需求场景的通用模型,因此Scrapy专门针对这种情况专门写了一个全站数据抓取的案例,使我们只需要去关注简介信息,详情信息,页面列表翻页按钮这些每个网站不同的东西,而无需再编写这套通用的抓取数据业务逻辑的控制。总之,Scrapy想尽办法把通用的功能抽象出来只写一次,不通用的地方留出接口供用户自己实现。
本节使用汽车之家二手车页面来介绍如何进行全站数据抓取。
2. Scrapy传统的全站数据抓取
这部分内容之前做过,直接开干。
开始动手:
scrapy startproject qiche
cd qiche
scrapy genspider ershouche che168.com
代码说明:
ershouche.py文件

; settings.py文件

源码展示:
ershouche.py源码
import scrapy
from scrapy.linkextractors import LinkExtractor
class ErshoucheSpider(scrapy.Spider):
name = 'ershouche'
allowed_domains = ['che168.com', 'autohome.com.cn']
start_urls = ['https://www.che168.com/china/list/#pvareaid=110965']
def parse(self, resp):
print(resp.url)
print(resp.xpath('//title/text()').extract_first().strip())
le = LinkExtractor(restrict_xpaths=('//ul[@class="viewlist_ul"]/li/a',))
links = le.extract_links(resp)
for link in links:
yield scrapy.Request(
url=link.url,
callback=self.parse_detail
)
page_le = LinkExtractor(restrict_xpaths=("//div[@id='listpagination']/a",))
pages = page_le.extract_links(resp)
for page in pages:
yield scrapy.Request(
url=page.url,
callback=self.parse
)
def parse_detail(self, resp):
try:
print(resp.url)
print(resp.xpath('//title/text()').extract_first().strip())
except Exception as e:
print(resp.url)
print("上面的URL报错了")
3. Scrapy CrawlSpider全站数据抓取
开始动手:
scrapy genspider -t ershou che168.com
代码说明:
ershou.py文件

; 源码展示:
ershou.py源码
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class ErshouSpider(CrawlSpider):
name = 'ershou'
allowed_domains = ['che168.com', 'autohome.com.cn']
start_urls = ['https://www.che168.com/china/list/#pvareaid=110965']
rules = (
Rule(LinkExtractor(restrict_xpaths=('//ul[@class="viewlist_ul"]/li/a')), callback='parse_item', follow=False),
Rule(LinkExtractor(restrict_xpaths=("//div[@id='listpagination']/a")), follow=True),
)
def parse_item(self, resp):
if "topicm.che168.com" not in resp.url:
try:
title = resp.xpath("//h3[@class='car-brand-name']/text()").extract_first()
price = resp.xpath("//span[@id='overlayPrice']/text()").extract_first()
if not title:
title = resp.xpath("//h3[@class='car-brand-name']/i[@class='icon-cxc']/text()").extract_first()
if not price:
price = resp.xpath("//div[@class='goodstartmoney']/text()").extract_first()
title = title.replace(" ","").strip()
price = price.replace(" ","").strip()
print(title, price)
with open("title_price.txt", mode="a", encoding="utf-8") as f:
f.write(f"{title},{price},{resp.url}\n")
except Exception as e:
print(f"{resp.url} 出错了")
print(e)
with open("error.txt", mode="a", encoding="utf-8") as f:
f.write(f"{resp.url} 出错了\n")
f.write(f"{e}\n")
4. 小结
使用Scrapy中的CrawlSpider模板可以帮我们快速的抓取全站数据,用起来很方便。
二、Redis简单使用
redis作为一款目前这个星球上性能最高的非关系型数据库之一。拥有每秒近十万次的读写能力,其实力只能用恐怖来形容。
1. 安装redis
redis是我见过这个星球上最好安装的软件了。比起前面的那一坨。它简直了…
直接把压缩包解压。然后配置一下环境变量就可以了。


接下来, 在环境变量中将该文件夹配置到path中。

我们给redis多配置几个东西(修改redis的配置文件, mac是: redis.conf, windows是: )
- 关闭bind
- 关闭保护模式 windows不用设置
protected-mode no
- 设置密码
requirepass 123456
将redis怼到windows服务必须进入到redis目录后才可以

将redis安装到windows服务
redis-server.exe --service-install redis.windows.conf --loglevel verbose
卸载服务:
redis-server --service-uninstall
开启服务:
redis-server --service-start
停止服务:
redis-server --service-stop
使用redis-cli链接redis
redis-cli -h ip地址 -p 端口 --raw
auth 密码

附赠RDM, redis desktop manager。可以帮我们完成redis数据库的可视化操作(需要就装, 不需要就算)

2. redis常见数据类型
redis中常见的数据类型有5个。
命令规则: 命令 key 参数
string
字符串(它自己认为是字符串, 我认为是任何东西。), redis最基础的数据类型。
常用命令
set key value
get key
incr key
incrby key count
type key
例如
set name zhangsan
get name
set age 10
get age
incr age
get age
incrby age 5
hash
哈希, 相当于字典。
常见操作
hset key k1 v1
hget key k1
hmset key k1 v1 k2 v2 k3 v3....
hmget key k1 k2....
hgetall key
hkeys key
hvals key
示例:
HMSET stu id 1 name sylar age 18
HMGET stu name age
HGETALL stu
HKEYS stu
HVALS stu
list
列表, 底层是一个双向链表。可以从左边和右边进行插入。记住每次插入都要记得这货是个双向链表
常见操作
LPUSH key 数据1 数据2 数据3....
RPUSH key 数据1 数据2 数据3....
LRANGE key start stop
LLEN key
LPOP key
RPOP key
示例:
LPUSH banji yiban erban sanban siban
LRANGE banji 0 -1
RPUSH ban ban1 ban2 ban3
LRANGE ban 0 -1
LPOP ban
LLEN key
set
set是无序的超大集合。无序, 不重复。
常见操作
SADD key 值
SMEMBERS key
SCARD key
SISMEMBER key val
SUNION key1 key2
SDIFF key1 key2
SINTER key1 key2
SPOP key
SRANDMEMBER key count
实例:
SADD stars 柯震东 吴亦凡 张默 房祖名
SADD stars 吴亦凡
SMEMBERS stars
SISMEMBER stars 吴亦凡
SADD my 周杰伦 吴亦凡 房祖名
SINTER stars my
SPOP my
SRANDMEMEBER my 2
zset
有序集合, 有序集合中的内容也是不可以重复的。并且存储的数据也是redis最基础的string数据。但是在存储数据的同时还增加了一个score。表示分值。redis就是通过这个score作为排序的规则的。
常用操作
ZADD key s1 m1 s2 m2 ...
ZRANGE key start stop [withscores]
ZREVRANGE key start stop
ZCARD key
ZCOUNT key min max
ZINCRBY key score member
ZSCORE key m
示例:
ZADD fam 1 sylar 2 alex 3 tory
ZRANGE fam 0 -1 WITHSCORES
ZREVRANGE fam 0 -1 WITHSCORES
ZINCRBY fam 10 alex
ZADD fam 100 alex
ZSCORE fam alex
ZCARD fam
redis还有非常非常多的操作。我们就不一一列举了。各位可以在网络上找到非常多的资料。
各位大佬们注意。数据保存完一定要save一下, 避免数据没有写入硬盘而产生的数据丢失
3. python搞定redis
python处理redis使用专用的redis模块。同样的, 它也是一个第三方库.
pip install redis
获取连接(1)
from redis import Redis
red = Redis(host="127.0.0.1",
port=6379,
db=0,
password=123456,
decode_responses=True)
获取连接(2)
pool = redis.ConnectionPool(
host="127.0.0.1",
port=6379,
db=0,
password=123456,
decode_responses=True
)
r = redis.Redis(connection_pool=pool)
print(r.keys())
我们以一个免费代理IP池能用到的操作来尝试一下redis
red.set("sylar", "邱彦涛")
print(red.get("sylar"))
lst = ["张三丰", "张无忌", "张翠山", "张娜拉"]
red.lpush("names", *lst)
result = red.lrange("names", 0, -1)
print(result)
red.zadd("proxy", {"192.168.1.1": 10, "192.168.1.2": 10})
red.zadd("proxy", {"192.168.1.3": 10, "192.168.1.6": 10})
red.zadd("proxy", {"192.168.1.4": 10, "192.168.1.7": 10})
red.zadd("proxy", {"192.168.1.5": 10, "192.168.1.8": 10})
red.zadd("proxy", {"192.168.1.4": 100})
red.zincrby("proxy", -10, "192.168.1.4")
red.zrem("proxy", "192.168.1.4")
c = red.zcard("proxy")
print(c)
r = red.zrangebyscore("proxy", 0, 100)
print(r)
r = red.zrevrange('proxy', 0, 100)
r = red.zscore("proxy", "192.168.1.4")
print(r)
Original: https://blog.csdn.net/weixin_40743639/article/details/122792696
Author: 一个小黑酱
Title: 逆向爬虫18 Scrapy抓取全站数据和Redis入门
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789831/
转载文章受原作者版权保护。转载请注明原作者出处!