

本篇将介绍使用scrapy爬取动态加载网站的方法,这样的网站我们很常见,我们这次就是爬取腾讯招聘的岗位数据
我们爬取的是这个页面里的岗位数据

点进去后是显示的是所有的岗位,我们想要什么岗位就直接搜就可以
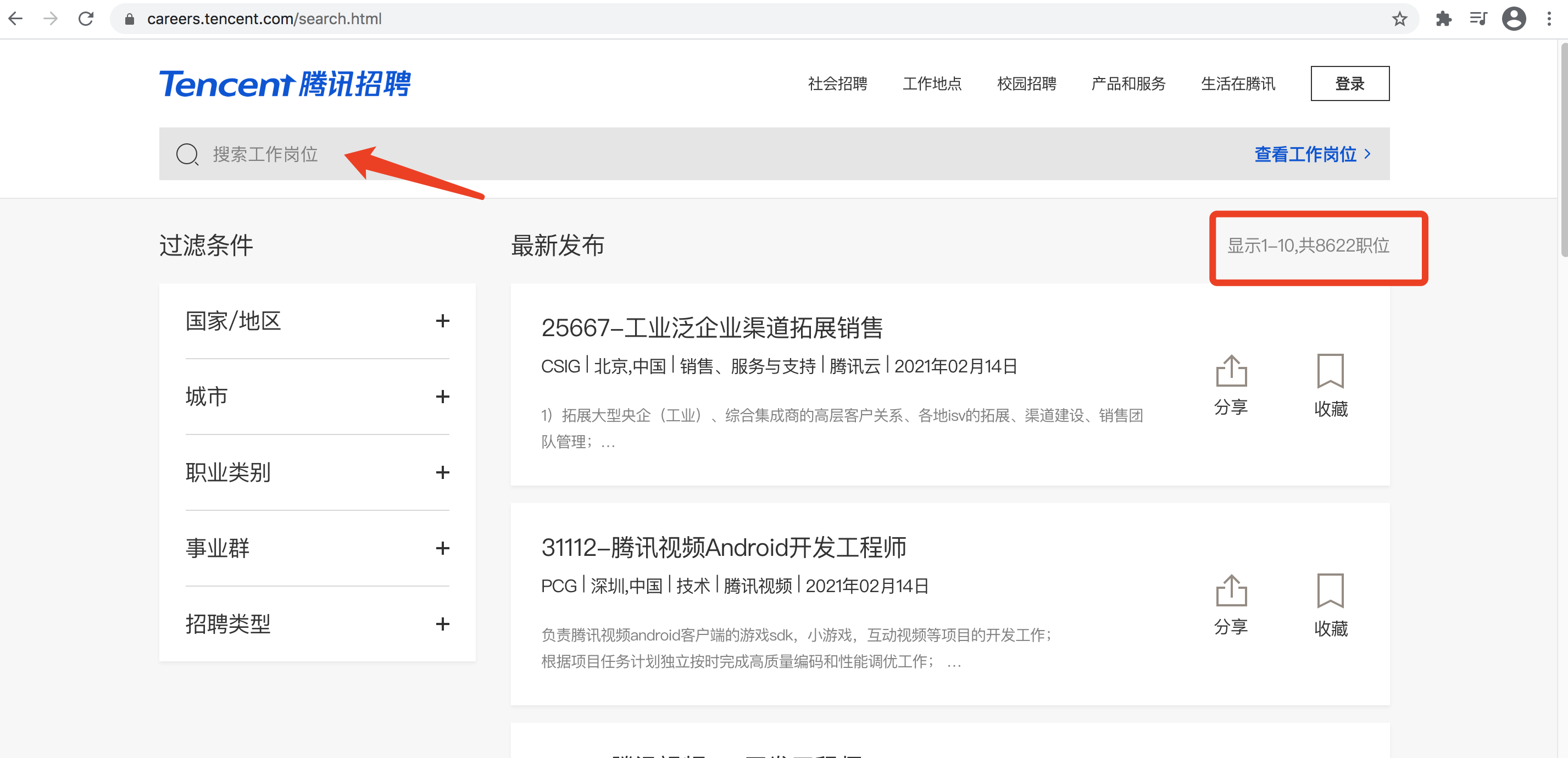
比如我们搜一个python方面的岗位吧,(此时出现的页面就是一级页面),但是呢,这些岗位的数据都是不全的,有工作职责,但是没有具体的工作要求,比如要求几年以上的工作经验,要什么学历等等
所以我们一级页面也不知要抓什么,但是我要抓取每个职位的信息,我们要到详情页里面去找,随便点击进一个职位看一下
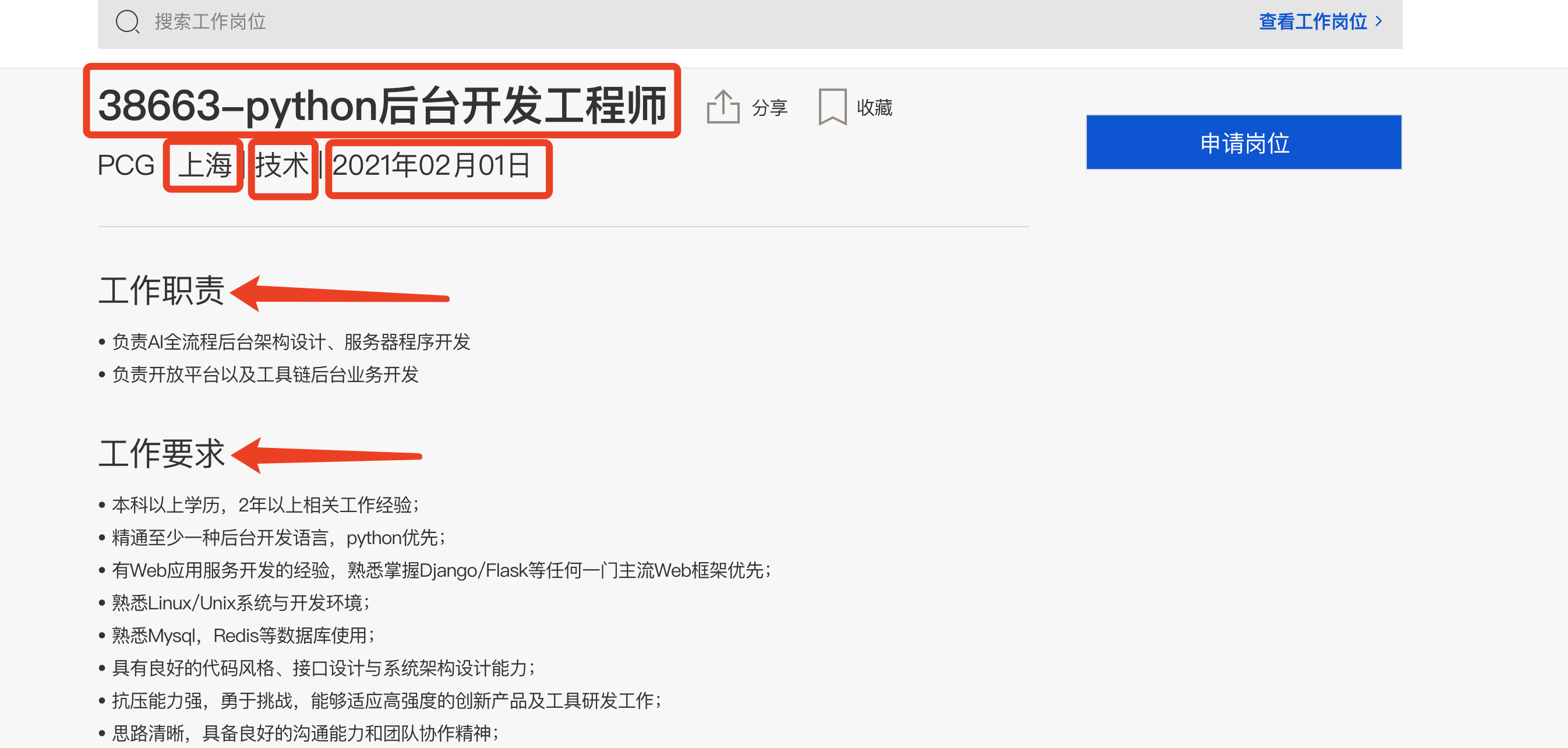
我们找到了有效的数据了,这个里面的数据就全了
第一个就是岗位名字,第二个是地点,第三个岗位的类型,是技术,是销售等等,第四个发布时间,第五个工作职责,第六个工作要求
因为 这样的网站是动态加载的,所以我们在一级页面直接 F12抓包,刷新一下,顺带手的点击下一页,我们直接进入到 XHR
先点击一个数据包看一下
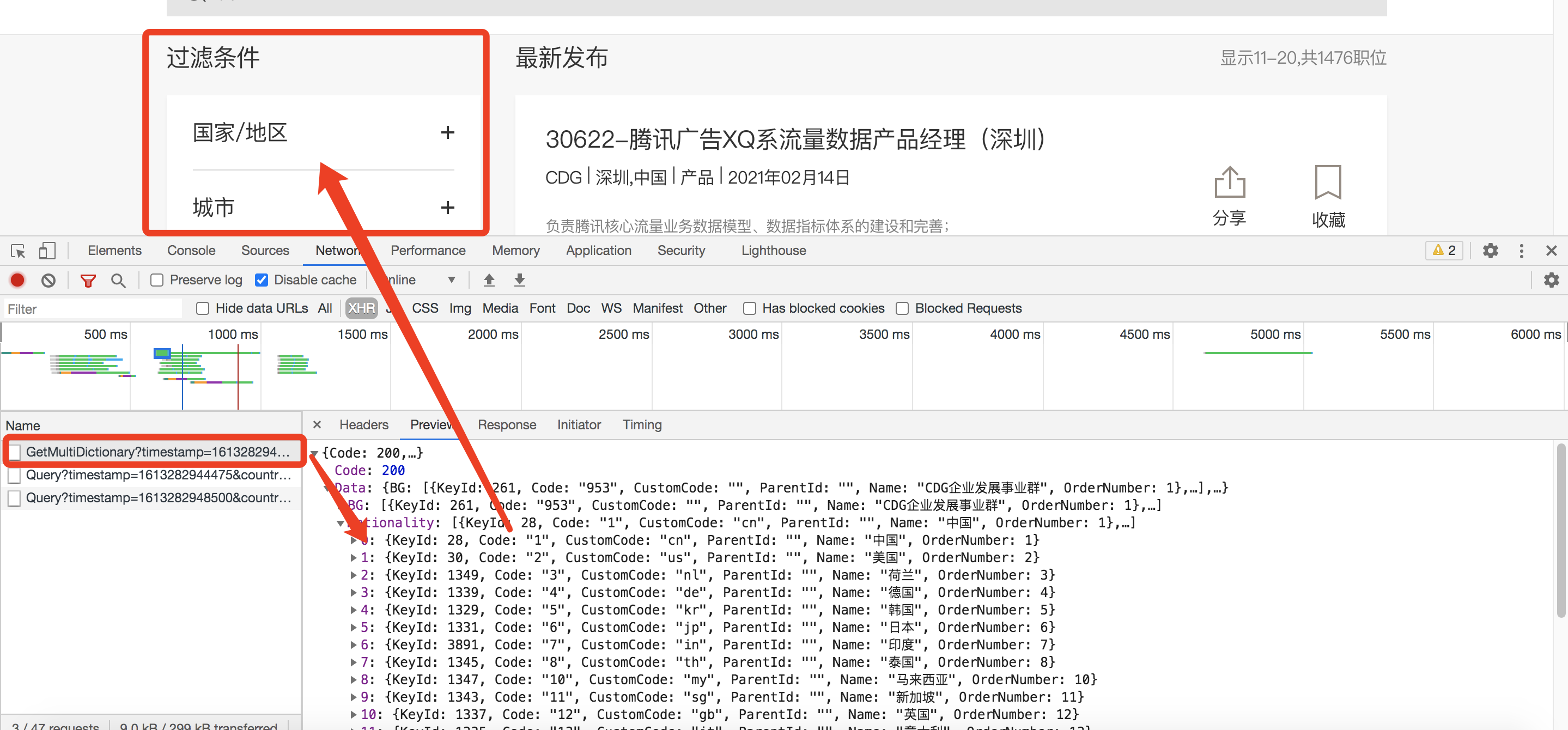
这个应该不是,它应该是上面的那些个过滤条件
我们接着看下面这个
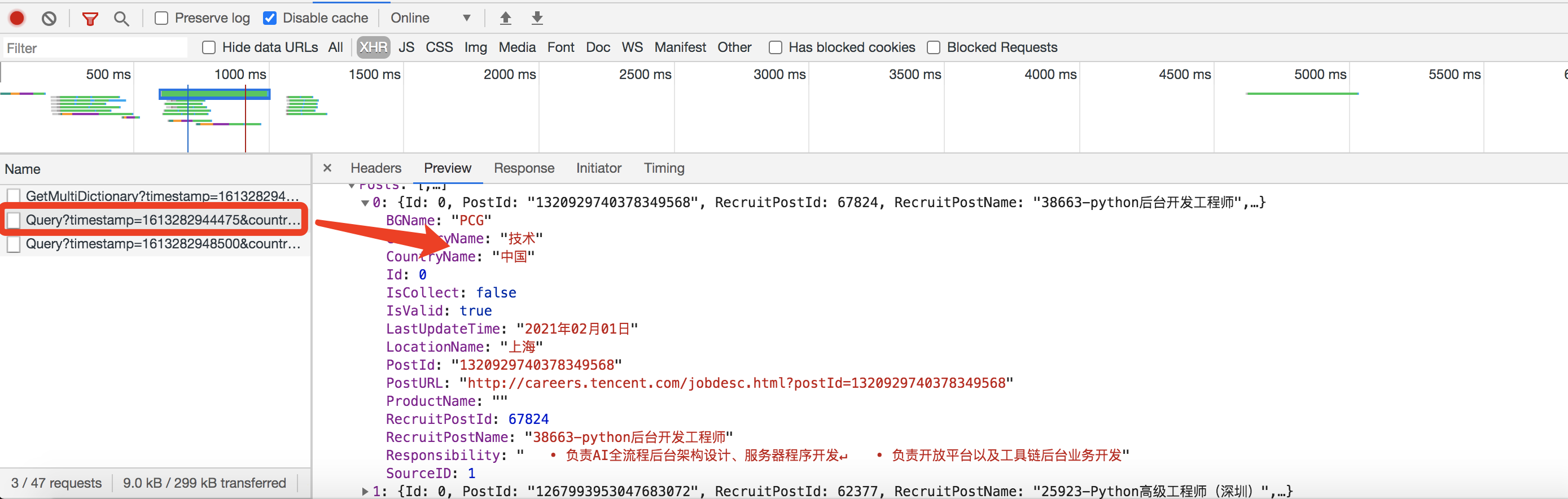
这个应该是了,虽然也没有具体的工作要求,但是大体的数据还是我们需要的,那我们到headers里面看看
这个是一个GET请求,查询的参数略微的有点多
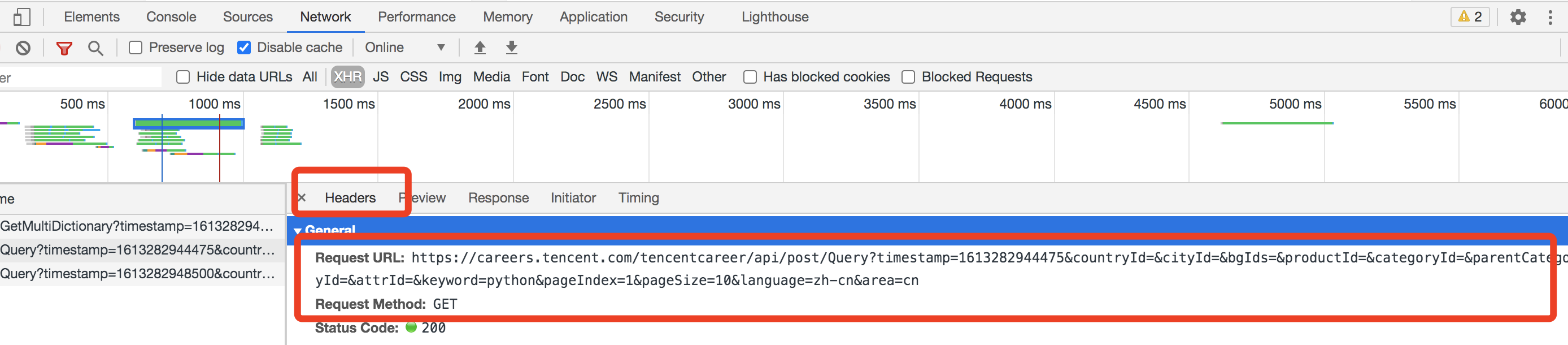
在来看一下查询参数,大概有这些

第一个就是一个13位的时间戳,下面空的没参数的就是筛选条件,再下面 keyword就是输入的关键字,是什么岗位, pageIndex这个是变得,就是页数, pageSize是一页有10个职位,这样还好,里面的问题也不是太大,唯一一个有问题的就是那个时间戳
上面Headers里面的URL地址就是json地址,我们复制放到浏览器地址栏里面看看是什么样子的

这些就是json数据,这就是一级页面,但是到现在一级页面到底抓什么我们还是不太清楚,那我们接下来看一下二级页面
同样我们也是抓包
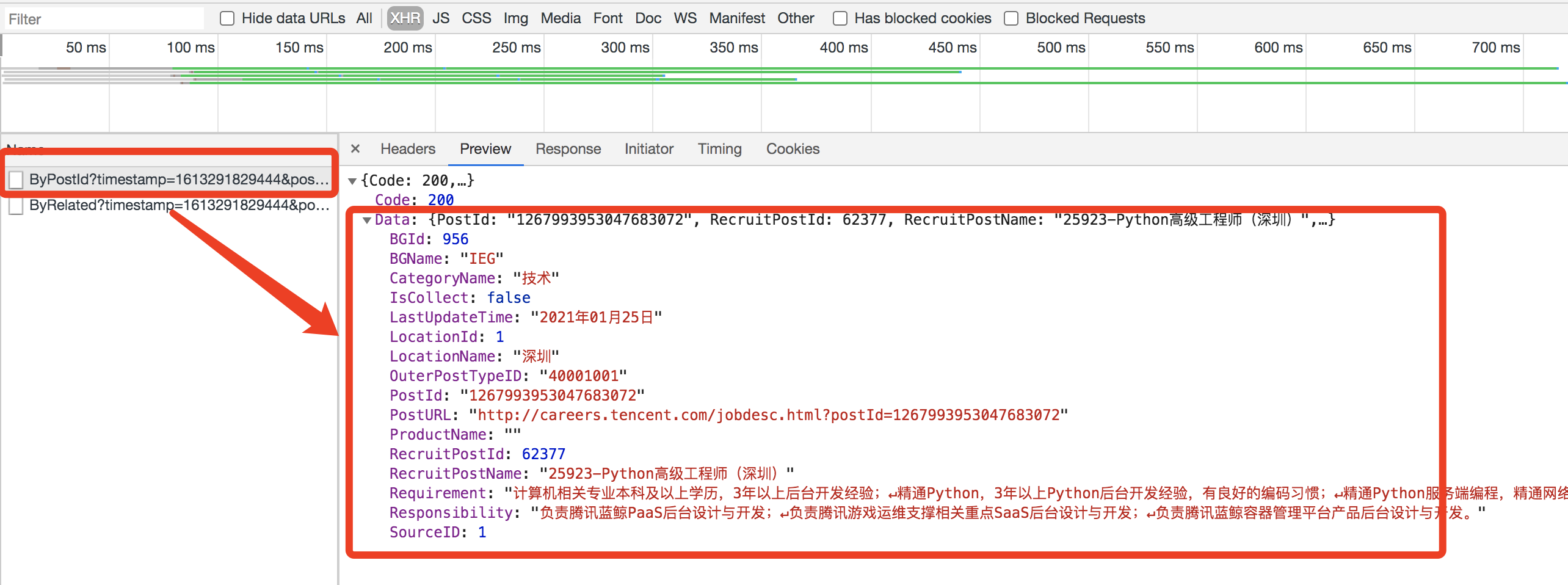
第一个数据包就是职位信息,这里面就有我们要抓的那六个信息,接着到Headers里面分析一下,同样是GET请求,我们还是看查询参数
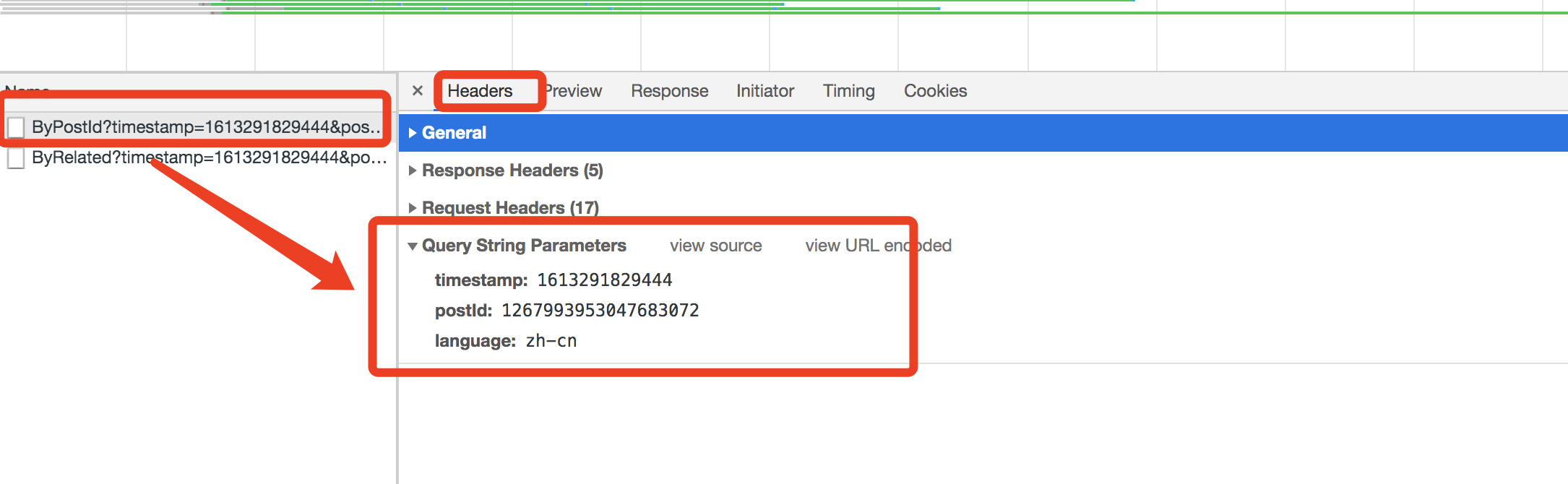
这个里面第一个还是个时间戳,第二个是职位id,这个每个职位和每个职位是不一样的,第三个就是语言,现在的问题是 职位id没有搞定,时间戳还是挺好搞定的
那我们看这个二级页面网络数据包中也找不到其他的数据包的职位ID了,我们想要所有职位的id,我们只能从一级页面中找所有的 postId只要一级页面中提取一页10个 postId,那我们就可以拼接10个二级页面详情页的json地址了
那我们就去一级页面中找看有没有 postId
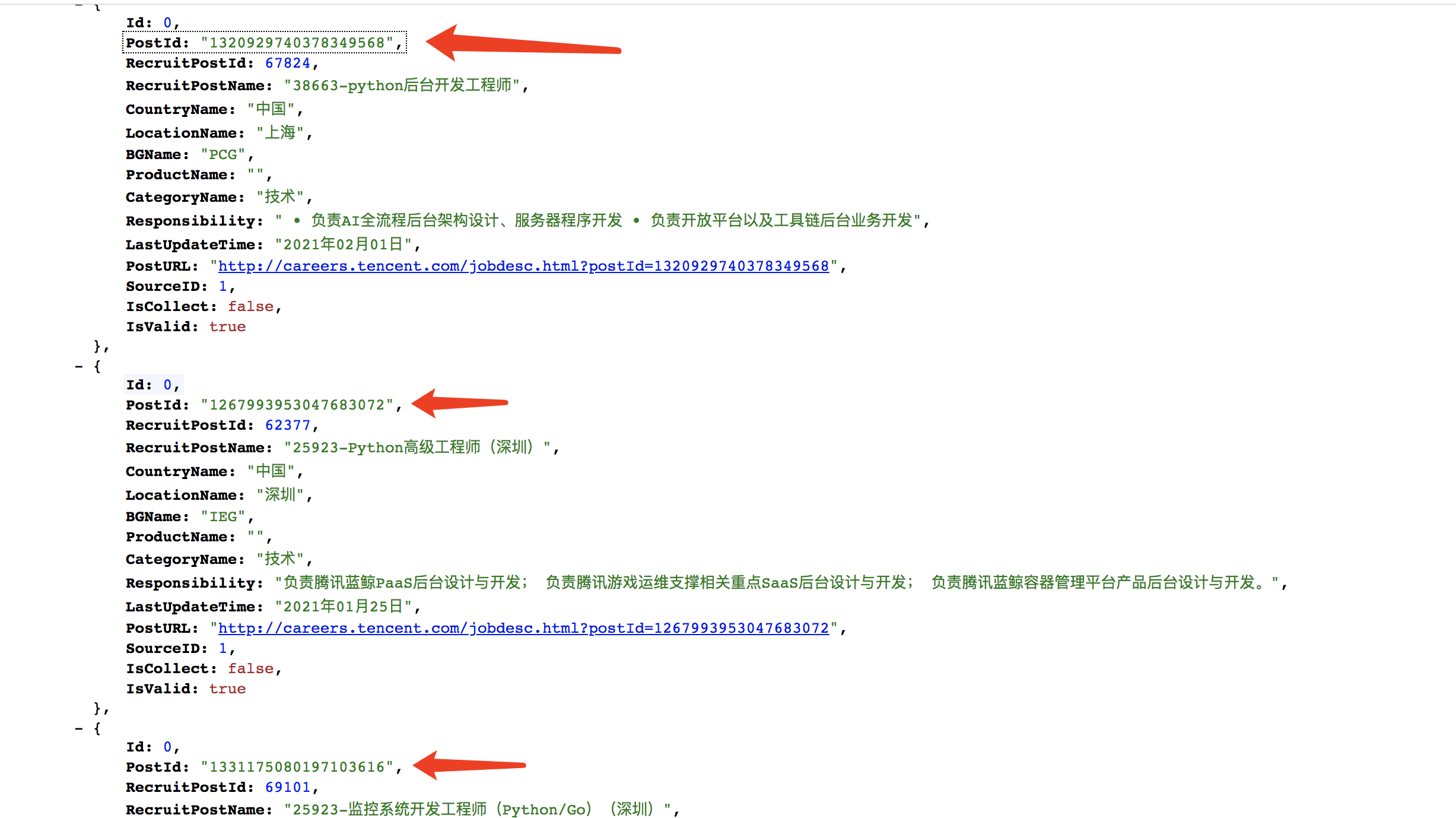
一级页面显示他是有的,且每个都不一样,好了,现在我们只需要做的就是想办法拼接 postId和二级页面的URL地址了
我先把二级页面的URL地址用浏览器打开放着

好接下来我们就正式去写代码了
首先还是创建爬虫项目以及爬虫文件,这里我就不啰嗦了,直接写代码了
items.py文件
import scrapy
class TencentItem(scrapy.Item):
job_id = scrapy.Field()
job_name = scrapy.Field()
job_type = scrapy.Field()
job_city = scrapy.Field()
job_time = scrapy.Field()
job_require = scrapy.Field()
job_duty = scrapy.Field()
tencent.py爬虫文件
import scrapy
import time
from urllib import parse
import json
from ..items import TencentItem
class TencentSpider(scrapy.Spider):
name = 'tencent'
allowed_domains = ['careers.tencent.com']
one_url = 'https://careers.tencent.com/tencentcareer/api/post/Query?timestamp={}&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword={}&pageIndex={}&pageSize=10&language=zh-cn&area=cn'
two_url = 'https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp={}&postId={}&language=zh-cn'
keyword = input('请输入职位类别:')
keyword = parse.quote(keyword)
start_urls = [one_url.format(int(time.time() * 1000), keyword, 1)]
def parse(self, response):
"""生成所有一级页面的url地址,交给调度器入队列"""
html = json.loads(response.text)
count = html['Data']['Count']
total = count // 10 if count % 10 == 0 else count // 10 + 1
for index in range(1, total + 1):
page_url = self.one_url.format(int(time.time() * 1000),
self.keyword,
index)
yield scrapy.Request(url=page_url, callback=self.detail_page)
def detail_page(self, response):
"""一级页面:提取每个职位的postId的值"""
html = json.loads(response.text)
for one_job_dict in html['Data']['Posts']:
item = TencentItem()
item['job_id'] = one_job_dict['PostId']
url = self.two_url.format(int(time.time() * 1000), item['job_id'])
yield scrapy.Request(url=url, meta={'item': item}, callback=self.get_job_info)
def get_job_info(self, response):
"""二级页面:提取每个职位的信息"""
html = json.loads(response.text)
item = response.meta['item']
item['job_name'] = html['Data']['RecruitPostName']
item['job_type'] = html['Data']['CategoryName']
item['job_city'] = html['Data']['LocationName']
item['job_time'] = html['Data']['LastUpdateTime']
item['job_require'] = html['Data']['Requirement']
item['job_duty'] = html['Data']['Responsibility']
yield item
写管道文件之前呢,要先把数据库整理好,我这里给出一份样本,可供参考,进入数据库后,直接复制粘题即可
create database tencentdb charset utf8;
use tencentdb;
create table tencenttab(
job_id varchar(100),
job_name varchar(500),
job_type varchar(500),
job_city varchar(200),
job_time varchar(200),
job_require varchar(5000),
job_duty varchar(5000)
)charset=utf8;
pipelines.py管道文件
class TencentPipeline(object):
def process_item(self, item, spider):
print(dict(item))
return item
import pymysql
class TencentMysqlPipeline(object):
def open_spider(self, spider):
self.db = pymysql.connect('localhost', 'root', '123456', 'tencentdb', charset='utf8')
self.cur = self.db.cursor()
self.ins = 'insert into tencenttab values(%s,%s,%s,%s,%s,%s,%s)'
def process_item(self, item, spider):
li = [
item['job_id'],
item['job_name'],
item['job_type'],
item['job_city'],
item['job_time'],
item['job_require'],
item['job_duty'],
]
self.cur.execute(self.ins, li)
self.db.commit()
return item
def close_spider(self, spider):
self.cur.close()
self.db.close()
setting.py全剧配置文件
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36',
}
ITEM_PIPELINES = {
'Tencent.pipelines.TencentPipeline': 300,
'Tencent.pipelines.TencentMysqlPipeline': 200,
}
run.py文件
from scrapy import cmdline
cmdline.execute('scrapy crawl tencent'.split())
Original: https://blog.csdn.net/Yxh666/article/details/113616312
Author: 杨旭华
Title: 使用scrapy框架爬取腾讯招聘的岗位
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789664/
转载文章受原作者版权保护。转载请注明原作者出处!