

Scrapy框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted 异步网络库来处理网络通讯。整体架构大致如下:
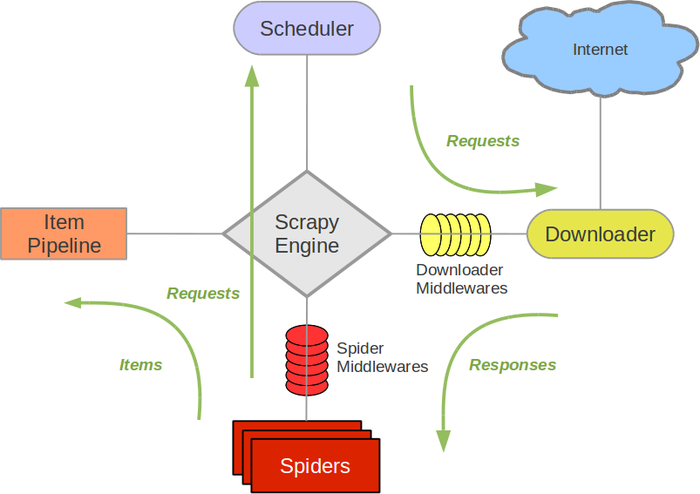

; 组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
Scheduler(调度器)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
引擎向调度器请求下一个要爬取的URL。 - 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。 - 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
Scrapy安装以及生成项目
下载方式
windows:
从 https://pip.pypa.io/en/latest/installing.html 安装 pip
打开命令行窗口,确认 pip 被正确安装:
pip --verison
安装scrapy:
pip install scrapy
项目初始化
startproject
语法: scrapy startproject <project_name>
是否需要项目: no
在 project_name 文件夹下创建一个名为 project_name 的Scrapy项目。
打开命令行窗口,切换到自己想要创建的项目的目录下,初始化一个名叫myproject的项目
scrapy startporject myproject
创建好后进入到我们所创建的项目中去,里面的目录结构如下所示:
scrapy.cfg
myproject/
__init__.py
items.py
pipelines.py
middlewares.py
settings.py
spiders/
__init__.py
...
接下来,就可以使用 scrapy 命令来管理和控制您的项目了。比如,创建一个新的spider,我们以MOOC网为例:
genspider
语法: scrapy genspider [-t template] <name> <domain>
是否需要项目: yes
在当前项目中创建spider。
这仅仅是创建spider的一种快捷方法。该方法可以使用提前定义好的模板来生成spider。您也可以自己创建spider的源码文件。
scrapy genspider course https://www.icourse163.org/
创建好后spider目录下会生成一个course .py的文件:
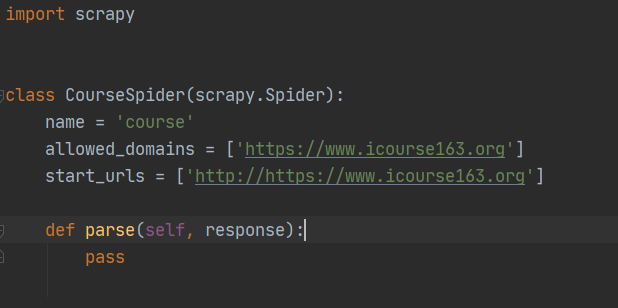
接下来我们看下项目的配置文件,项目的配置文件在目录下的setting.py
BOT_NAME:项目名称
USER_AGENT:用户代理
ROBOTSTXT_OBEY:是否遵循机器人协议,默认是true
CONCURRENT_REQUESTS:最大并发数
DOWNLOAD_DELAY:下载延迟时间,单位是秒,控制爬虫爬取的频率,根据你的项目调整,不要太快也不要太慢,默认是3秒,即爬一个停3秒,设置为1秒性价比较高,如果要爬取的文件较多,写零点几秒也行
COOKIES_ENABLED:是否保存COOKIES,默认关闭
DEFAULT_REQUEST_HEADERS:默认请求头,上面写了一个USER_AGENT,其实这个东西就是放在请求头里面的,这个东西可以根据你爬取的内容做相应设置。
ITEM_PIPELINES:项目管道,300为优先级,越低越爬取的优先度越高,默认是注释掉的
在使用Scrapy时,可以声明所要使用的设定。这可以通过使用环境变量: SCRAPY_SETTINGS_MODULE 来完成。
SCRAPY_SETTINGS_MODULE 必须以Python路径语法编写, 如 myproject.settings 。 注意,设定模块应该在 Python import search path 中。
接下来可以开始爬取任务,打开命令行输入scrapy crawl 开始爬取任务
crawl
语法: scrapy crawl
是否需要项目: yes
使用spider进行爬取。
scrapy crawl course
日志模块
Scrapy提供了log功能。您可以通过 scrapy.log 模块使用。当前底层实现使用了 Twisted logging ,不过可能在之后会有所变化。
log服务必须通过显示调用 scrapy.log.start() 来开启。
Scrapy提供5层logging级别:
CRITICAL - 严重错误(critical)
ERROR - 一般错误(regular errors)
WARNING - 警告信息(warning messages)
INFO - 一般信息(informational messages)
DEBUG - 调试信息(debugging messages)
可以通过终端选项(command line option) –loglevel/-L 或 LOG_LEVEL 来设置log级别。设置log级别为WARNING,就只会WARNING等级之下的ERROR和CRITICAL
用WARNING记录
from scrapy import log
log.msg("This is a warning", level=log.WARNING)
在spider中添加log的推荐方式是使用Spider的 log() 方法。该方法会自动在调用 scrapy.log.msg() 时赋值 spider 参数。其他的参数则直接传递给 msg() 方法。
也可自己封装一个日志模块
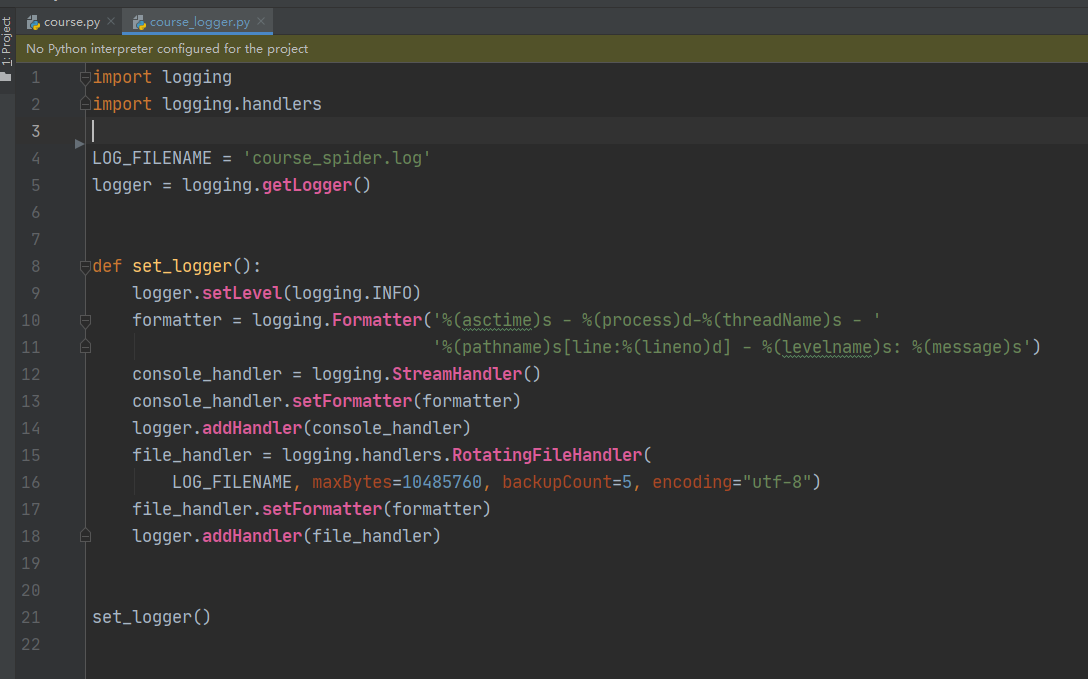
在使用的调用日志模块
from .course_logger import logger
实际案例
接下来以中国大学MOOC为例,爬取免费公开课的一些信息
以高等数学(三)为例,课程的地址必须类似以下两种格式:
https://www.icourse163.org/course/NUDT-42002
https://www.icourse163.org/course/NUDT-42002?tid=1462924451

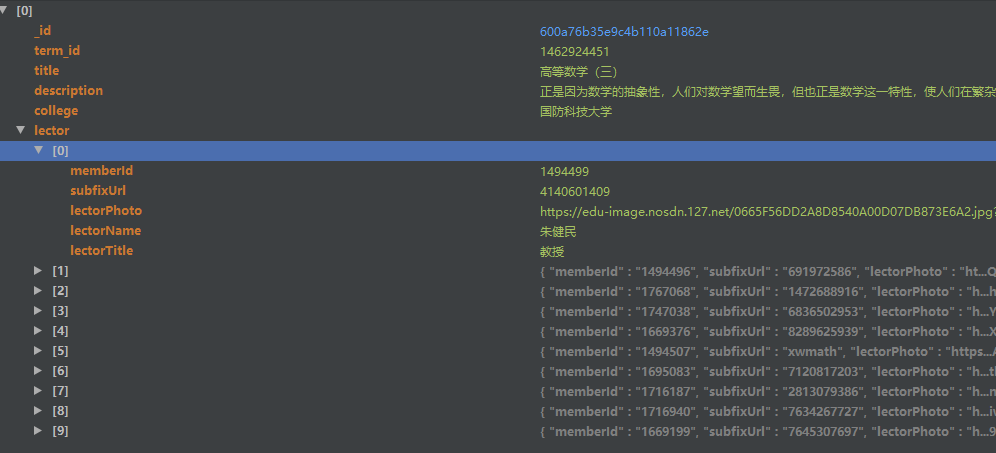
首先在item.py中,定义好你要提取的内容,比如我们提取的是课程的名称、ID、讲师、简介、学校,相应创造这几个变量。Field方法实际上的做法是创建一个字典,给字典添加一个建,暂时不赋值,等待提取数据后再赋值
import scrapy
class MoocItem(scrapy.Item):
term_id = scrapy.Field()
title = scrapy.Field()
description = scrapy.Field()
college = scrapy.Field()
lector = scrapy.Field()
思路
我们需要爬取的只是一个单页面,主要就是分析HTML元素,利用xpath编写路径表达式来获取节点/节点集,和常规电脑文件路径类似。
re — 正则表达式操作
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用
yield
scrapy框架会根据 yield 返回的实例类型来执行不同的操作:
a. 如果是 scrapy.Request 对象,scrapy框架会去获得该对象指向的链接并在请求完成后调用该对象的回调函数
b. 如果是 scrapy.Item 对象,scrapy框架会将这个对象传递给 pipelines.py做进一步处理
def parse(self, response):
item = {'term_id': re.search(r'termId : "(\d+)"', response.text).group(1),
'title': response.xpath("//meta[@name= 'description']/@content").extract_first().split(',')[0],
'description': response.xpath("//meta[@name= 'description']/@content").extract_first().split(',')[1][
10:],
'college': response.xpath("//meta[@name= 'keywords']/@content").extract_first().split(',')[1],
}
lectors = []
script = response.css('script:contains("window.staffLectors")::text').get()
chiefLector_str = ''.join(re.findall('chiefLector = \\{([^}]*)\\}', script))
chiefLector_list = re.sub('\s+', '', ' '.join(chiefLector_str.split())).strip()
chiefLector = demjson.decode("{" + chiefLector_list + "}")
lectors.append(chiefLector)
staffLectors_str = ''.join(re.findall('staffLectors = \[([^\[\]]+)\]', script))
staffLectors_list = re.sub('\s+', '', ' '.join(staffLectors_str.split())).strip()
staffLector = demjson.decode("[" + staffLectors_list + "]")
if staffLector:
for staff in staffLector:
lectors.append(staff)
item['lector'] = lectors
yield item
在提取讲师内容的时候有一点麻烦,讲师内容是在script标签中
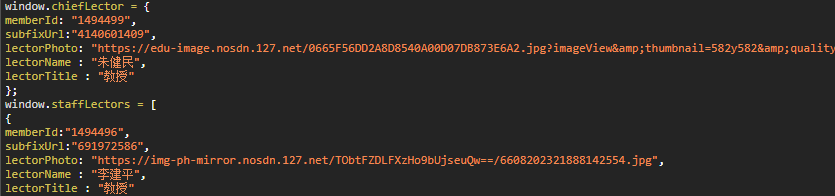
利用正则表达式去匹配变量名,然后再去匹配中括号或是大括号中的内容,还需要借助demjson处理JSON
demjson
python处理json是需要第三方json库来支持,工作中遇到处理json数据,是没有安装第三方的json库。demjson模块提供用于编码或解码用语言中性JSON格式表示的数据的类和函数(这在ajax Web应用程序中通常被用作XML的简单替代品)。此实现尽量尽可能遵从JSON规范(RFC 4627),同时仍然提供许多可选扩展,以允许较少限制的JavaScript语法。它包括完整的Unicode支持,包括UTF-32,BOM,和代理对处理。
pipline.py管道可以处理提取的数据,如存Mongo数据库,代码敲好后不要忘记在settings里开启pipelines。
from pymongo import MongoClient
class MyprojectPipeline:
MONGO_URL = "mongodb://localhost:27017"
MONGO_DB = "mooc"
MONGO_TABLE = "course"
client = MongoClient(MONGO_URL)
db = client[MONGO_DB]
def process_item(self, item, spider):
self.save_to_mongo(item)
return item
def save_to_mongo(self, data):
if self.db[self.MONGO_TABLE].insert(data):
print("SAVE SUCCESS", data)
return True
return False
存储成功
Original: https://blog.csdn.net/woaichihanbao/article/details/112919711
Author: woaichihanbao
Title: Scrapy爬虫框架的解析与实例(中国大学MOOC)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789442/
转载文章受原作者版权保护。转载请注明原作者出处!