

环境
pycharm
安装好scrapy
创建一个scrapy项目
在pycharm中的命令行界面创建一个beijingbus的scrapy项目
D:\python\beibusTest>scrapy startproject beijingbus
#这里的D:\python\beibusTest>是我自己使用的路径,自己可以设置自己想要将项目保存的路径
切换到beijingbus目录,并使用genspider创建一个spider
D:\python\beibusTest>cd beijingbus
D:\python\beibusTest\beijingbus>scrapy genspider bei_bus beijing.8684.cn
使用pycharm打开我们创建的beijingbus项目


找到自己项目的路径(像我D:\python\beibusTest\beijingbus)
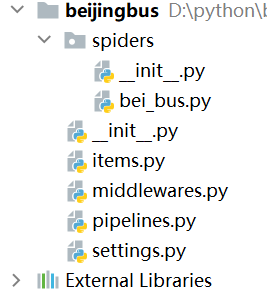
beijingbus/spiders/:放置spider代码的目录,用于编写用户自定义的爬虫
beijingbus/items.py:项目中的item文件,用于定义用户要抓取的字段
beijingbus/middlewares.py:主要是对功能的拓展,用于用户添加一些自定义的功能
beijingbus/pipelines.py:管道文件,当spider抓取到内容(item)以后,会被送到这里,这些信息在这里会被清洗,去重,保存到数据或者数据库
beijingbus/settings.py:项目的设置文件,用来设置爬虫的默认信息,及相关功能的开启与否,如是否遵循robots协议,设置默认的hesder等
开始编写代码:
进入settings.py将ROBOTSTXT_OBEY的参数改为False,使爬虫不遵循Robots协议
ROBOTSTXT_OBEY = False
将DEFAULT_REQUEST_HEADERS方法注释掉,添加User-Agent属性
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36'
}
User-Agent的获取方法(打开浏览器,右键检查(或者f12)——Network——Headers)

(此操作是为了实现模拟浏览器访问的效果)
进入bei_bus.py文件:
1.先爬取一级网页

代码:
进入bei_bus.py文件
#对自动生成的start_urls进行修改,改成如下
import scrapy
class BeiBusSpider(scrapy.Spider):
name = 'bei_bus'
allowed_domains = ['beijing.8684.cn']
start_urls = 'http://beijing.8684.cn/'
def start_requests(self):
for page in range(1): #这里我只爬取了list1,可以自己选择加循环条件
url = '{url}/list{page}'.format(url=self.start_urls, page=(page+1)) #是在构建一级网页的网址
yield FormRequest(url, callback=self.parse_index)
def parse(self, response):
pass
在pycharm中的命令行界面(Terminal)执行’scrapy crawl bei_bus’可以实现一级网页的爬取:

2.再爬取二级网页
import scrapy
from scrapy import Spider, FormRequest, Request
from urllib.parse import urljoin
class BeiBusSpider(scrapy.Spider):
name = 'bei_bus'
allowed_domains = ['beijing.8684.cn']
start_urls = 'http://beijing.8684.cn/'
def start_requests(self): # start_requests方法固定
for page in range(1):
url = '{url}/list{page}'.format(url=self.start_urls, page=(page+1))
yield FormRequest(url, callback=self.parse_index)
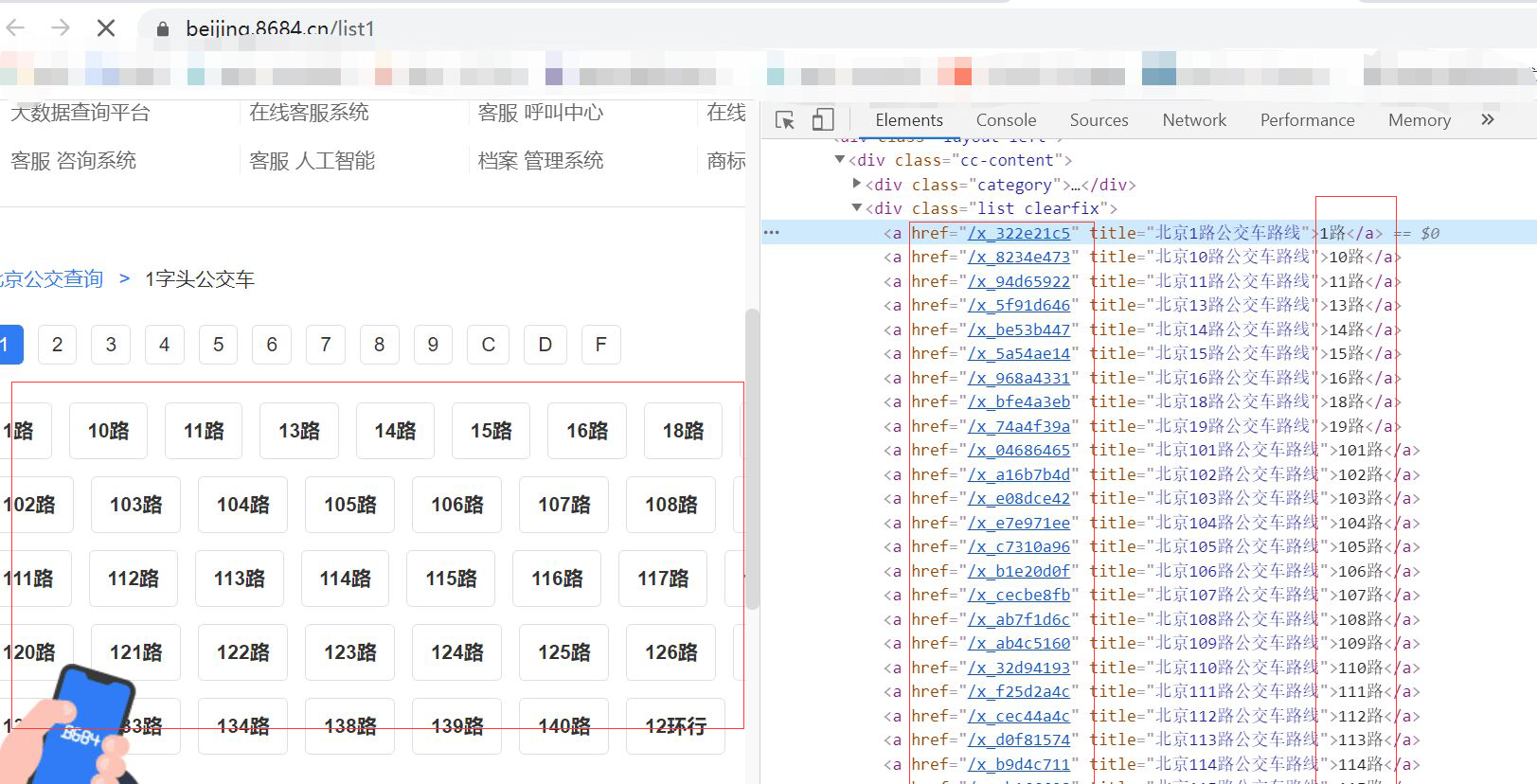
def parse_index(self, response):
beijingbus = response.xpath('//div[@class="list clearfix"]/a//@href').extract() #爬取二级网页
for href in beijingbus:
url2 = urljoin(self.start_urls, href) #拼接二级网页
yield Request(url2, callback=self.parse_detail)
def parse_detail(self, response):
pass
def parse(self, response):
pass
在pycharm中的命令行界面(Terminal)执行’scrapy crawl bei_bus’可以实现二级网页的爬取:

3.再爬取详细信息

#这也是bei_bus.py中的完整代码
import scrapy
from scrapy import Spider, FormRequest, Request
from urllib.parse import urljoin
from ..items import BeijingbusItem
class BeiBusSpider(scrapy.Spider):
name = 'bei_bus'
allowed_domains = ['beijing.8684.cn']
start_urls = 'http://beijing.8684.cn/'
# 一级网页
def start_requests(self):
for page in range(1):
url = '{url}/list{page}'.format(url=self.start_urls, page=(page+1))
yield FormRequest(url, callback=self.parse_index)
# 二级网页
def parse_index(self, response):
#使用xpath寻找详细信息页面的url,具体用法可以搜索“xpath语法”
beijingbus = response.xpath('//div[@class="list clearfix"]/a//@href').extract() # extract()方法表示符合条件的所有文本
for href in beijingbus:
url2 = urljoin(self.start_urls, href) # urljoin()方法拼接url
# yield再次发起网页访问,callback后的方法用于回调函数,可以在回调函数中对网页进行处理
yield Request(url2, callback=self.parse_detail)
下面是爬取详细页的代码:
def parse_detail(self,response):
bus_name = response.xpath('//div[@class="info"]/h1//text()').extract_first() # extract_frist()方法用于返回符合条件的第一个数据
bus_time = response.xpath('//div[@class="info"]/ul/li[1]//text()').extract_first()
bus_type = response.xpath('//div[@class="info"]/ul/li[2]//text()').extract_first()
#格式化数据
bus_item = BeijingbusItem()
for field in bus_item.fields:
bus_item[field] = eval(field) # eval() 函数用来执行一个字符串表达式,并返回表达式的值
yield bus_item
# pass
def parse(self, response):
pass
在pycharm中的命令行界面(Terminal)执行’scrapy crawl bei_bus’可以实现详细页面的爬取:

(上图只是一部分)
进入items.py文件,修改其中的class以格式化数据
import scrapy
class BeijingbusItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
bus_name = scrapy.Field()
bus_type = scrapy.Field()
bus_time = scrapy.Field()
# pass
在数据库中创建数据表(shuju)并设置编码格式:
create table shuju(
bus_name varchar(100),
bus_time varchar(100),
bus_type varchar(100)
)CHARACTER SET utf8;
在settings.py中:
文末添加如下内容
DB_HOST = 'localhost'
DB_USER = 'root'
DB_PWD = '123456'
DB = 'test' # 数据库 
DB_CHARSET = 'utf8'
将ITEM_PIPELINES 方法的注释去掉,并将其中的内容改为如下:
ITEM_PIPELINES = {
'beijingbus.pipelines.BeijingbusPipeline': 300, # 数字代表优先级,数字越小,优先级越高
}
在pipelines.py文件中:
from . import settings
import pymysql
#修改类为BeijingbusPipeline,添加初始化方法,将host,user,pwd,b,charset从settings中读取出来,并通过一个connect()方法建立与数据库的连接
class BeijingbusPipeline:
# 初始化方法
def __init__(self):
self.host = settings.DB_HOST
self.user = settings.DB_USER
self.pwd = settings.DB_PWD
self.db = settings.DB
self.charset = settings.DB_CHARSET
self.connect()
# 建立与数据的连接
def connect(self):
# 连接数据库,创建一个数据库对象
self.conn = pymysql.connect(host=self.host,
user=self.user,
password=self.pwd,
db=self.db,
charset=self.charset
)
# 开启游标功能,创建游标对象
self.cursor = self.conn.cursor() # 这里使用的是数据库对象self.conn中的cursor()方法
# 实现process_item方法,用于完成向数据库中插入数据的操作
def process_item(self, item, spider):
sql = 'insert into shuju(bus_name,bus_time,bus_type) values ("%s","%s","%s")'%(item['bus_name'], item['bus_time'], item['bus_type'])
# 执行SQL语句
self.cursor.execute(sql) # 使用execute方法执行SQL语句
self.conn.commit() # 提交到数据库执行
return item
# 用于关闭数据库的连接
def close_spiders(self):
self.conn.close()
self.cursor.close()
关于更多的python操作mysql数据库(cursor()游标讲解)可以参考下面这篇文章的讲解:
https://www.jb51.net/article/177865.htm
(转载别人的链接,如有侵权望作者告知,本人立即删除)
最后在pycharm中的命令行界面(Terminal)执行’scrapy crawl bei_bus’,再查看数据表:

Original: https://blog.csdn.net/qq_45925324/article/details/111763883
Author: 败北L
Title: 使用scrapy爬取北京公交
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789327/
转载文章受原作者版权保护。转载请注明原作者出处!