

一、要爬的网站:
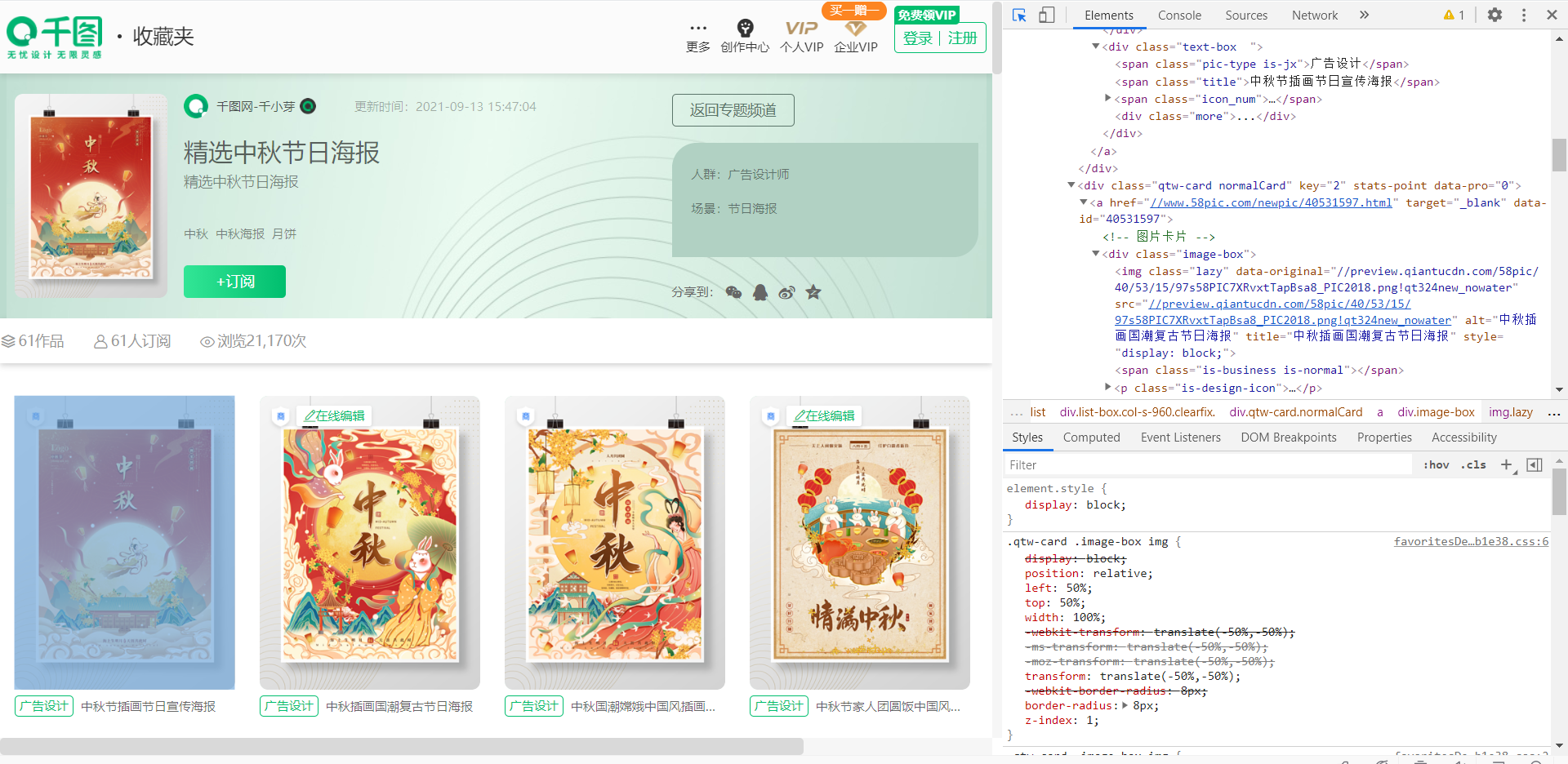

二、建个项目:
scrapy startproject demo
scrapy genspider image 网站域名
spiders下的image.py是scrapy自动为我们生成的
三、编辑image.py
用xpath提取我们需要的网站内容(图片标题以及链接)
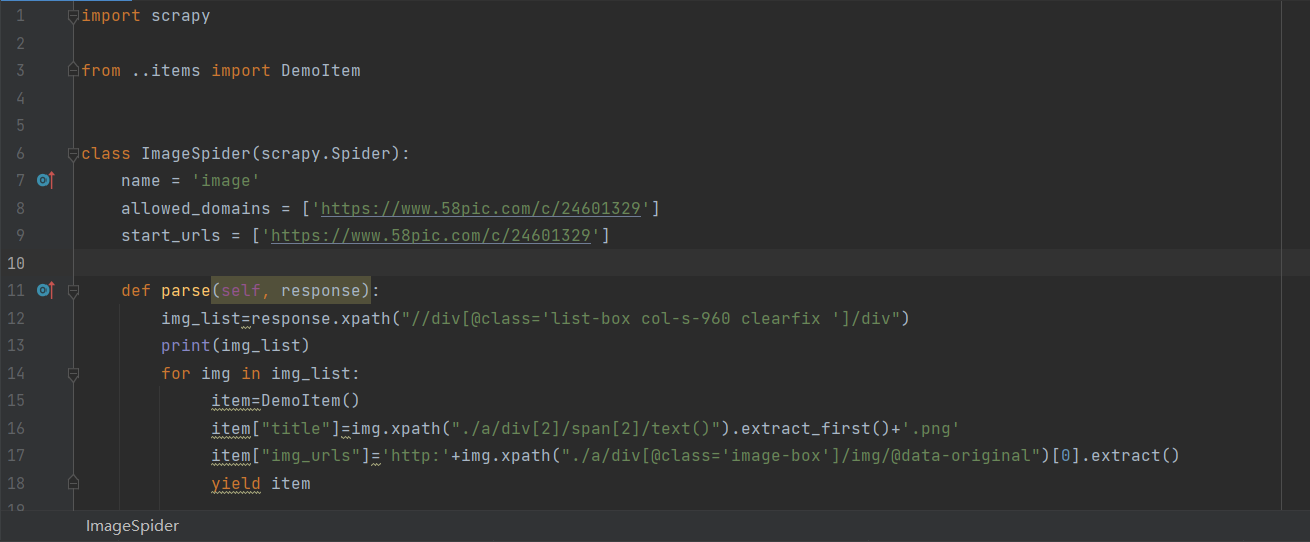
import scrapy
from ..items import DemoItem
class ImageSpider(scrapy.Spider):
name = 'image'
allowed_domains = ['https://www.58pic.com/c/24601329']
start_urls = ['https://www.58pic.com/c/24601329']
def parse(self, response):
img_list=response.xpath("//div[@class='list-box col-s-960 clearfix ']/div")
print(img_list)
for img in img_list:
item=DemoItem()
item["title"]=img.xpath("./a/div[2]/span[2]/text()").extract_first()+'.png'
item["img_urls"]='http:'+img.xpath("./a/div[@class='image-box']/img/@data-original")[0].extract()
yield item
四、编辑items.py
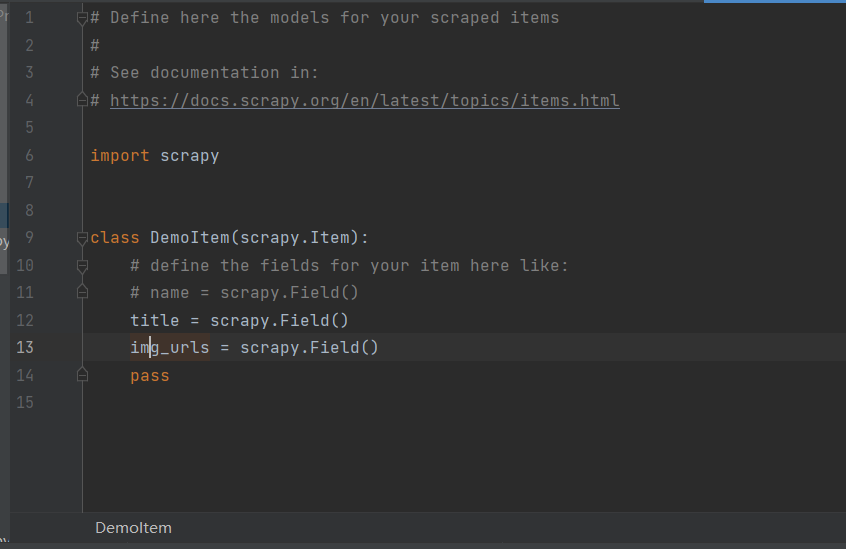
Define here the models for your scraped items
#
See documentation in:
https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DemoItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
img_urls = scrapy.Field()
pass
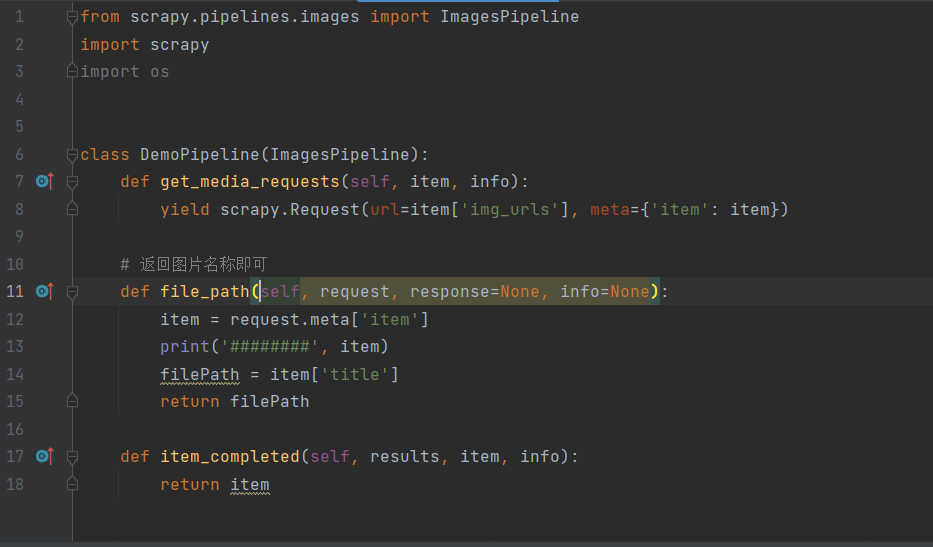
五、编辑pipelines.py
from scrapy.pipelines.images import ImagesPipeline
import scrapy
import os
class DemoPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(url=item['img_urls'], meta={'item': item})
# 返回图片名称即可
def file_path(self, request, response=None, info=None):
item = request.meta['item']
print('########', item)
filePath = item['title']
return filePath
def item_completed(self, results, item, info):
return item
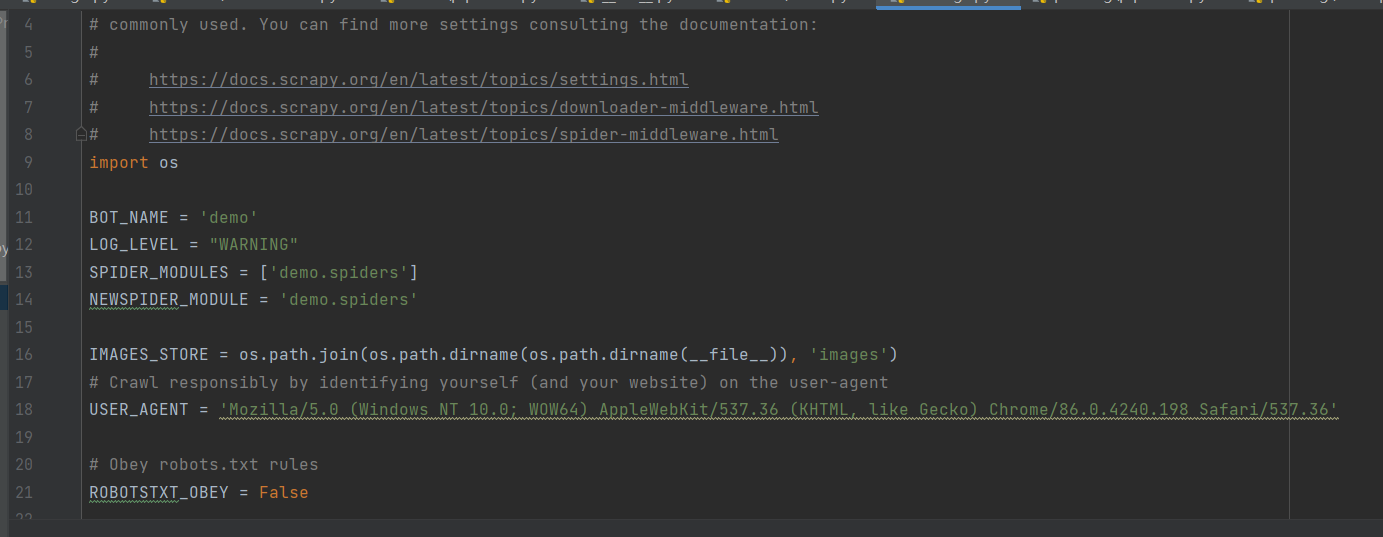
六、修改setting文件
1.把管道打开:
ITEM_PIPELINES:项目管道,300为优先级,越低越爬取的优先度越高

2.其他:
BOT_NAME:项目名
LOG_LEVEL:屏蔽warning
USER_AGENT:默认是注释的,这个东西非常重要,不写容易被判断为电脑,简单点写一个Mozilla/5.0即可
ROBOTSTXT_OBEY:是否遵循机器人协议,默认是true,需要改为false,否则很多东西爬不了
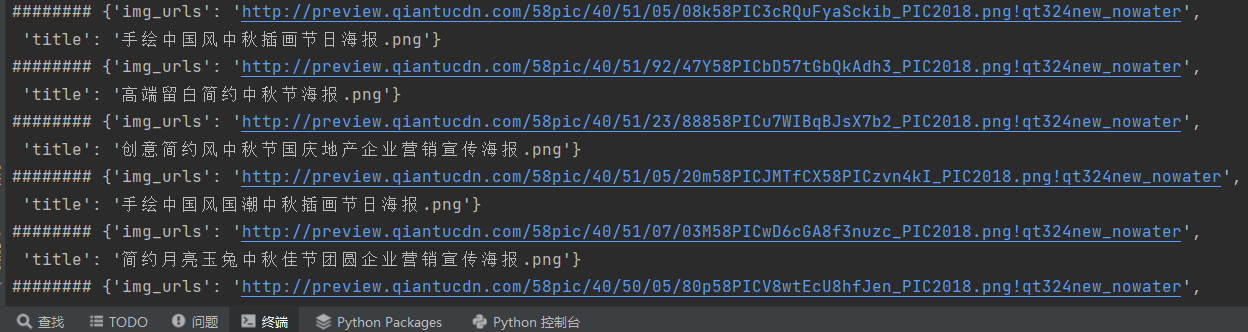
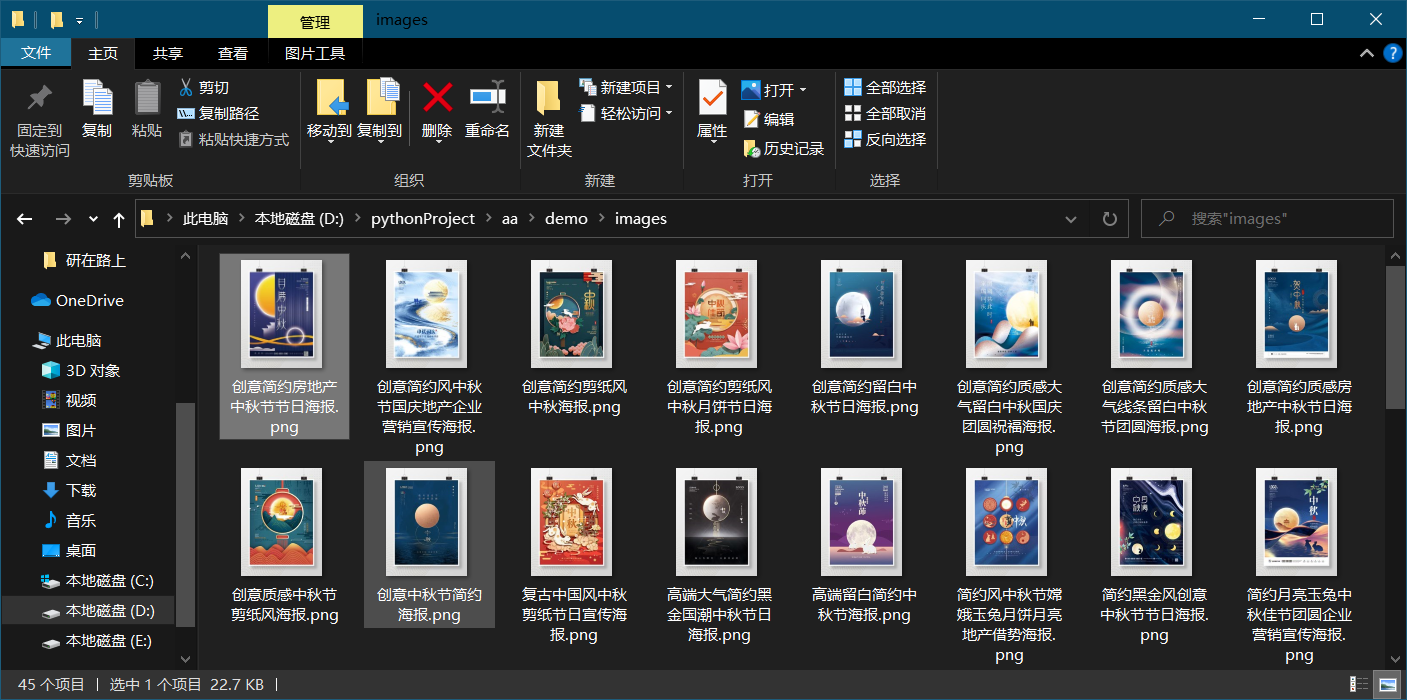
scrapy crawl image
Original: https://blog.csdn.net/ahc176/article/details/120271318
Author: 我啊困的唉
Title: Scrapy爬图片入门——静态网站
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789310/
转载文章受原作者版权保护。转载请注明原作者出处!