

目录
基于Spider的全站数据抓取
-
就是将网站中某板块下的全部页码对应的页面数据进行抓取
-
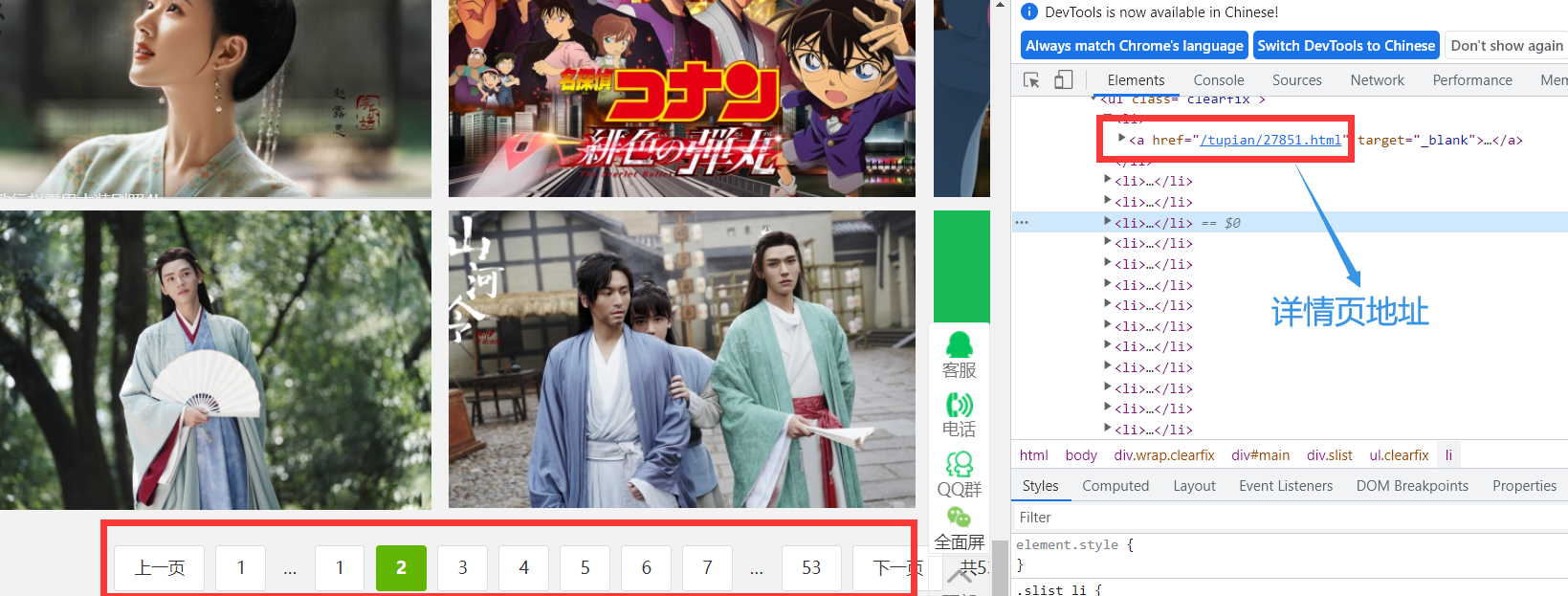
需求:爬取 https://pic.netbian.com/4kmeinv/的照片的名称
-
实现方式: – 将所有页面的url添加到start_urls列表(不推荐)
-
自行手动进行请求发送(推荐)
-
手动请求发送:
-
yield scrapy.Request(url,callback)


#爬虫文件中
import scrapy
class GirlSpider(scrapy.Spider):
name = 'girl'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://pic.netbian.com/4kmeinv/']
#生成一个通用的url模板(不可变)
url='https://pic.netbian.com/4kmeinv/index_%d.html'
page_num=2
def parse(self, response):
li_list=response.xpath('//ul[@class="clearfix"]/li')
for li in li_list:
name=li.xpath('./a/b/text()').extract_first()
if self.page_num
五大核心组件:
引擎(Scrapy) :用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler) :用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回.
下载器(Downloader) :用于下载网页内容, 并将网页内容返回给蜘蛛
爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体 (Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
项目管道(Pipeline) :负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的 有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次 序处理数据。

1.spider中的url被封装成请求对象交给引擎(每一个对应一个请求对象)
2.引擎拿到请求对象之后,将全部交给调度器
3.调度器闹到所有请求对象后,通过内部的过滤器过滤掉重复的url,最后将去重后的所有url对应的请求对象压入到队列中,随后调度器调度出其中一个请求对象,并将其交给引擎
4.引擎将调度器调度出的请求对象交给下载器
5.下载器拿到该请求对象去互联网中下载数据
6.数据下载成功后会被封装到response中,随后response会被交给下载器
7.下载器将response交给引擎
8.引擎将response交给spiders
9.spiders拿到response后调用回调方法进行数据解析,解析成功后生成item,随后spiders将item交给引擎
10引擎将item交给管道,管道拿到item后进行数据的持久化存储
请求传参
(需要将在不同解析方法中解析到的数据封装到同一个iterm当中)
- 使用场景:如果爬取解析的数据不在同一张页面中。(深度爬取)
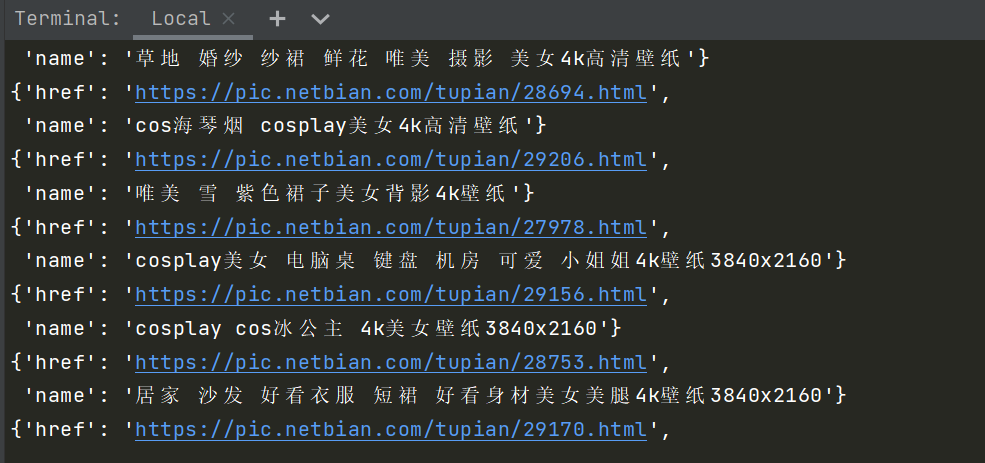
例如:比如说我们请求到一个页面https://pic.netbian.com/4kmeinv/可以拿到这些图片的详情页的网址,但是还想对它的详情页里面的数据进行抓取。即爬去解析的数据在不同页面中。
需求: 在第一个页面获取每张图的详情地址 ,然后进入详情页获取图片介绍。
#爬虫文件的代码
import scrapy
from sgirl.items import SgirlItem
class GirlSpider(scrapy.Spider):
name = 'girl'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://pic.netbian.com/4kmeinv/']
url = 'https://pic.netbian.com/4kmeinv/index_%d.html'
page_num = 1
#详情页面解析
def parse_detail(self,response):
item=response.meta['item']
name=response.xpath('//*[@id="main"]/div[2]/div[1]/div[1]/h1/text()').extract_first()
item['name']=name
yield item
#首页数据解析
def parse(self, response):
li_list = response.xpath('//*[@id="main"]/div[3]/ul/li')
for li in li_list:
item = SgirlItem()
href = li.xpath('./a/@href').extract_first()
href='https://pic.netbian.com'+href
# print(href)
item['href'] = href
# 对详情页发送请求获取详情页的页面源码数据
# 手动请求的发送
# 请求传参:meta={} 可以将meta字典传递给请求对应的回调函数
yield scrapy.Request(href, callback=self.parse_detail, meta={'item': item})
# # 分页操作
if self.page_num < 3:
new_url = format(self.url % self.page_num)
self.page_num += 1
yield scrapy.Request(new_url, callback=self.parse)
#pipelines.py
class SgirlPipeline:
def process_item(self, item, spider):
print(item)
return item
#items.py
import scrapy
class SgirlItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
href = scrapy.Field()
name = scrapy.Field()
图片数据爬取之ImagesPipeline:
-
基于scrapy爬取字符串类型的数据和爬取图片类型的数据区别?
-
字符串:只需要基于xpath进行解析且提交管道进行持久化存储
-
图片:xpath解析出图片src的属性值。单独的对图片地址发起请求获取图片二进制类型 的数据
-
ImagesPipeline: – 只需要将img的src的属性值进行解析,提交到管道,管道就会对图片的 src进行请求发送获取图片的二进制类型的数据,且还会帮我们进行持久化存储。
-
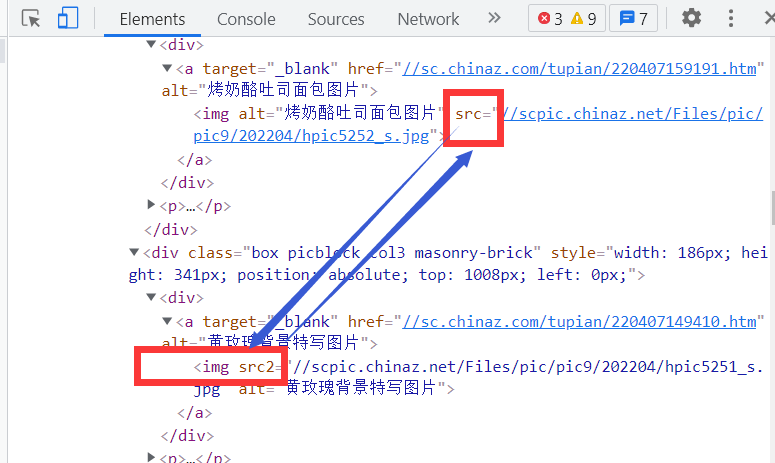
需求:爬取站长素材中的高清图片
-
使用流程:
-
数据解析(图片的地址)
-
将存储图片地址的item提交到制定的管道类
-
在管道文件中自定制一个基于ImagesPipeLine的一个管道类:
-
get_media_request – file_path – item_completed
-
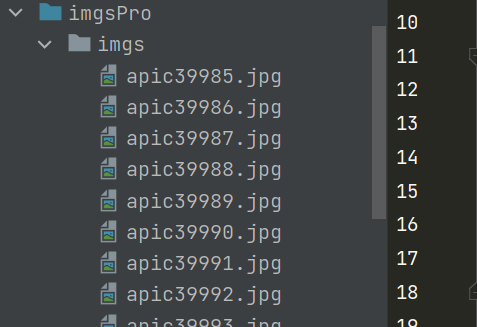
在配置文件中: -指定图片存储的目录:IMAGES_STORE = ‘./imgs’
-
指定开启的管道:自定制的管道类
import scrapy
from imgsPro.items import ImgsproItem
class ImgsSpider(scrapy.Spider):
name = 'imgs'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://sc.chinaz.com/tupian/']
def parse(self, response):
div_list=response.xpath('//*[@id="container"]/div')
for div in div_list:
#注意图片伪属性
src=div.xpath('./div/a/img/@src2').extract_first()
src='https:'+src[0:-6]+'.jpg'
item=ImgsproItem()
item['src']=src
yield item
# print(src)
#pipelines.py
Define your item pipelines here
#
Don't forget to add your pipeline to the ITEM_PIPELINES setting
See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class ImgsproPipeline:
def process_item(self, item, spider):
return item
from scrapy.pipelines.images import ImagesPipeline
import scrapy
class imgsPileLine(ImagesPipeline):
#就是可以根据图片地址进行图片数据的请求
def get_media_requests(self, item, info):
yield scrapy.Request(item['src'])
#指定图片存储的路径
def file_path(self, request, response=None, info=None):
imgName = request.url.split('/')[-1]
return imgName
def item_completed(self, results, item, info):
return item #返回给下一个即将被执行的管道类
#items.py
import scrapy
class ImgsproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
src = scrapy.Field()
运行成功:
Original: https://blog.csdn.net/weixin_54824895/article/details/124003094
Author: 一事无成~
Title: scrapy框架初识02
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789296/
转载文章受原作者版权保护。转载请注明原作者出处!