

- 目标界面:https://dg.lianjia.com/ershoufang/
- 爬取的信息:①标题 ②总价 ③小区名 ④所在地区名 ⑤详细信息 ⑥详细信息里的面积
- 存入:MongoDB
上面链接是东莞的二手房信息,如果需要爬取别的信息更改url即可,因为网页结构没变:
https://bj.lianjia.com/ershoufang/ 北京二手房信息
https://gz.lianjia.com/ershoufang/ 广州二手房信息
https://gz.lianjia.com/ershoufang/tianhe 广州天河区二手房信息
…
下面就是具体的代码了:

ershoufang_spider.py:
import scrapy
from lianjia_dongguan.items import LianjiaDongguanItem
class lianjiadongguanSpider(scrapy.Spider):
name = "ershoufang"
global start_page
start_page=1
start_urls=["https://gz.lianjia.com/ershoufang/haizhu/pg"+str(start_page)]
def parse(self, response):
for item in response.xpath('//div[@class="info clear"]'):
yield {
"title": item.xpath('.//div[@class="title"]/a/text()').extract_first().strip(),
"Community": item.xpath('.//div[@class="positionInfo"]/a[1]/text()').extract_first(),
"district": item.xpath('.//div[@class="positionInfo"]/a[2]/text()').extract_first(),
"price": item.xpath('.//div[@class="totalPrice"]/span/text()').extract_first().strip(),
"area": item.xpath('.//div[@class="houseInfo"]/text()').re("\d室\d厅 \| (.+)平米")[0],
"info": item.xpath('.//div[@class="houseInfo"]/text()').extract_first().replace("平米", "㎡").strip()
}
i=1
while i 15:
j=i+start_page
i = i + 1
next_url="https://gz.lianjia.com/ershoufang/haizhu/pg"+str(j)
yield scrapy.Request(next_url,dont_filter=True,callback=self.parse)
items.py:
import scrapy
class LianjiaDongguanItem(scrapy.Item):
title=scrapy.Field()
info=scrapy.Field()
location=scrapy.Field()
price=scrapy.Field()
Community=scrapy.Field()
pass
middlewares.py:
from scrapy import signals
class LianjiaDongguanSpiderMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
return None
def process_spider_output(self, response, result, spider):
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class LianjiaDongguanDownloaderMiddleware(object):
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
from fake_useragent import UserAgent
class UserAgentMiddleware(object):
def __init__(self, crawler):
super().__init__()
self.ua = UserAgent()
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request,spider):
request.headers['User-Agent'] = self.ua.random
print('User-Agent:'+str(request.headers.getlist('User-Agent')))
print('User-Agent:' + str(request.headers['User-Agent']))
def process_response(self, request, response, spider):
print("请求头Cookie:" + str(request.headers.getlist('Cookie')))
print("响应头Cookie:" + str(response.headers.getlist('Set-Cookie')))
print("这是响应头:"+str(response.headers))
print("这是请求头:"+str(request.headers))
return response
pipelines.py:
import pymongo
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class LianjiaPipeline(object):
def __init__(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
db_name = settings["MONGODB_DBNAME"]
client = pymongo.MongoClient(host=host, port=port)
db = client[db_name]
self.post = db[settings["MONGODB_DOCNAME"]]
def process_item(self, item, spider):
zufang = dict(item)
self.post.insert(zufang)
return item
settings.py:
BOT_NAME = 'lianjia_dongguan'
SPIDER_MODULES = ['lianjia_dongguan.spiders']
NEWSPIDER_MODULE = 'lianjia_dongguan.spiders'
ROBOTSTXT_OBEY = True
DOWNLOAD_DELAY = 10
DOWNLOAD_DELAY_RANDOM=True
COOKIES_ENABLED = False
COOKIES_DEBUG = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'Cookie': {'TY_SESSION_ID': '84ad2c08-9ea5-4193-927a-221fd9bae52b', 'lianjia_uuid': '4fc8b1ad-d17f-45c5-85a3-6e0072d35e1e', 'UM_distinctid': '170a9b9075c4d0-0efd9a9b0cf32d-34564a7c-e1000-170a9b9075d52f', '_jzqc': '1', '_jzqy': '1.1583395441.1583395441.1.jzqsr', '_jzqckmp': '1', '_smt_uid': '5e60b270.14483188', 'sajssdk_2015_cross_new_user': '1', '_ga': 'GA1.2.887972367.1583395443', '_gid': 'GA1.2.365215785.1583395443', 'select_city': '441900', '_qzjc': '1', 'Hm_lvt_9152f8221cb6243a53c83b956842be8a': '1583395559', 'sensorsdata2015jssdkcross': '%7B%22distinct_id%22%3A%22170a9b909b4715-0769015f66a016-34564a7c-921600-170a9b909b553%22%2C%22%24device_id%22%3A%22170a9b909b4715-0769015f66a016-34564a7c-921600-170a9b909b553%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D', 'CNZZDATA1254525948': '426683749-1583390573-https%253A%252F%252Fwww.baidu.com%252F%7C1583401373', 'CNZZDATA1255604082': '143512665-1583390710-https%253A%252F%252Fwww.baidu.com%252F%7C1583401510', 'lianjia_ssid': 'd4d26773-ce0d-8cfe-ab64-d39d54960c3c', 'CNZZDATA1255633284': '201504093-1583390793-https%253A%252F%252Fwww.baidu.com%252F%7C1583401593', '_jzqa': '1.637230317292238100.1583395441.1583401552.1583405268.4', 'Hm_lpvt_9152f8221cb6243a53c83b956842be8a': '1583405272', '_qzja': '1.884599034.1583395479079.1583401552386.1583405267952.1583405267952.1583405271972.0.0.0.13.4', '_qzjb': '1.1583405267952.2.0.0.0', '_qzjto': '13.4.0', '_jzqb': '1.2.10.1583405268.1'},
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
}
MONGODB_HOST="127.0.0.1"
MONGODB_PORT=27017
MONGODB_DBNAME="lianjia"
MONGODB_DOCNAME="ershoufang"
ITEM_PIPELINES={"lianjia_dongguan.pipelines.LianjiaPipeline":300}
RETRY_ENABLED=True
RETRY_TIMES = 1000
RETRY_HTTP_CODES = [500, 503, 504, 400, 404 ,403,408,301,302]
DOWNLOADER_MIDDLEWARES = {
'lianjia_dongguan.middlewares.UserAgentMiddleware': 200,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 90,
'scrapy_proxies.RandomProxy': 100,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 110,
}
PROXY_LIST = 'C:/Users/wzq1643/Desktop/HTTPSip.txt'
PROXY_MODE = 0
import random
CUSTOM_PROXY = "http://49.81.190.209"
HTTPERROR_ALLOWED_CODES = [301,302]
MEDIA_ALLOW_REDIRECTS =True
以上就是scrapy的全部代码了,去年写的,亲测还能用:
(base) PS C:\Users\wzq1643\scrapy\lianjia_dongguan\lianjia_dongguan\spiders> scrapy runspider ershoufang_spider.py
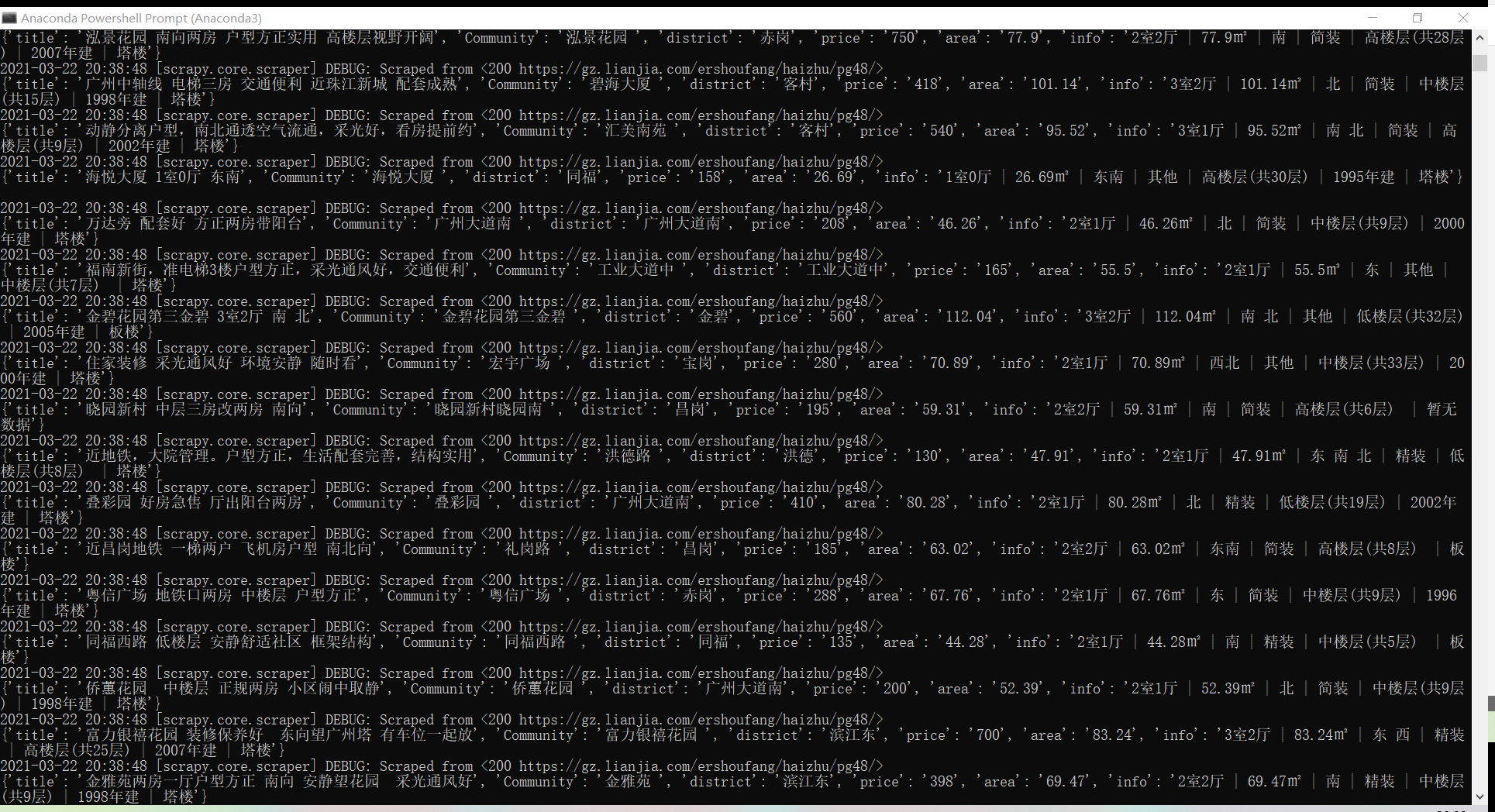
说一下这里用到的反爬技巧:
随机UA:python有个库fake_useragent可以自动生成随机UA,在middleware.py里
参考:https://blog.csdn.net/cnmnui/article/details/99852347
IP池:实力有限,我是从网上找的免费的ip,质量可能不高,放到txt里,调用方法在settings.py
参考:https://www.jianshu.com/p/c656ad21c42f
cookie池:这里没用到什么cookie池,就是多弄了几个cookie放到settings.py
最后,附上一个用pymongo从MongoDB中将这些数据导出为excel的代码:
import pandas as pd
import pymongo
client=pymongo.MongoClient(host='127.0.0.1' , port=27017)
db = client['lianjia']
collection=db.ershoufang
list=[]
for i in collection.find () :
list.append(dict(i))
print(list)
df=pd.DataFrame (list)
print(df)
df.to_excel("C:/Users/wzq1643/Desktop/gz_ershoufang.xls")
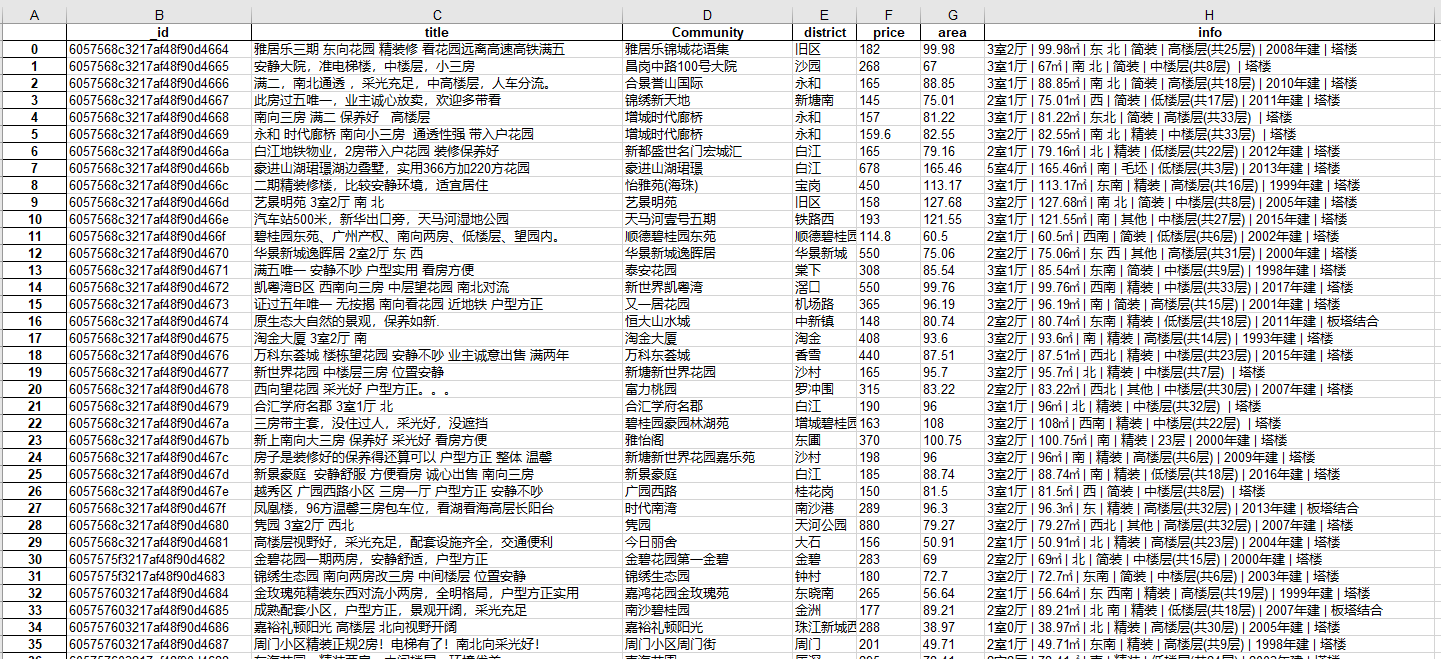
excel打开如下:
Original: https://blog.csdn.net/ones133/article/details/115095525
Author: � ONES
Title: python爬虫:用scrapy框架爬取链家网房价信息并存入mongodb
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789257/
转载文章受原作者版权保护。转载请注明原作者出处!