

文章目录
- python编程快速上手(持续更新中…)
- python爬虫从入门到精通
- Scrapy爬虫框架
* - 一、scrapy_redis概念作用和流程
– - 二、scrapy_redis实现断点续爬
– - 三、爬取图书信息-邮乐网(https://ule.com)
–
一、scrapy_redis概念作用和流程
如果当前网站的数据比较庞大, 几十亿数据,明天交付,我们就需要使用分布式来更快的爬取数据
1. 分布式是什么
简单的说 分布式就是不同的节点(服务器,ip不同)共同完成一个任务
缺点:
加快运行速度,运行总资源不会少
分散,增加风险
2. scrapy_redis的概念
scrapy_redis是scrapy框架的基于redis的分布式组件
3. scrapy_redis的作用
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:
通过持久化请求队列和请求的指纹集合来实现:
断点续爬,记录
分布式快速抓取
4. scrapy_redis的原理
去重集合
任务队列
数据队列(存)
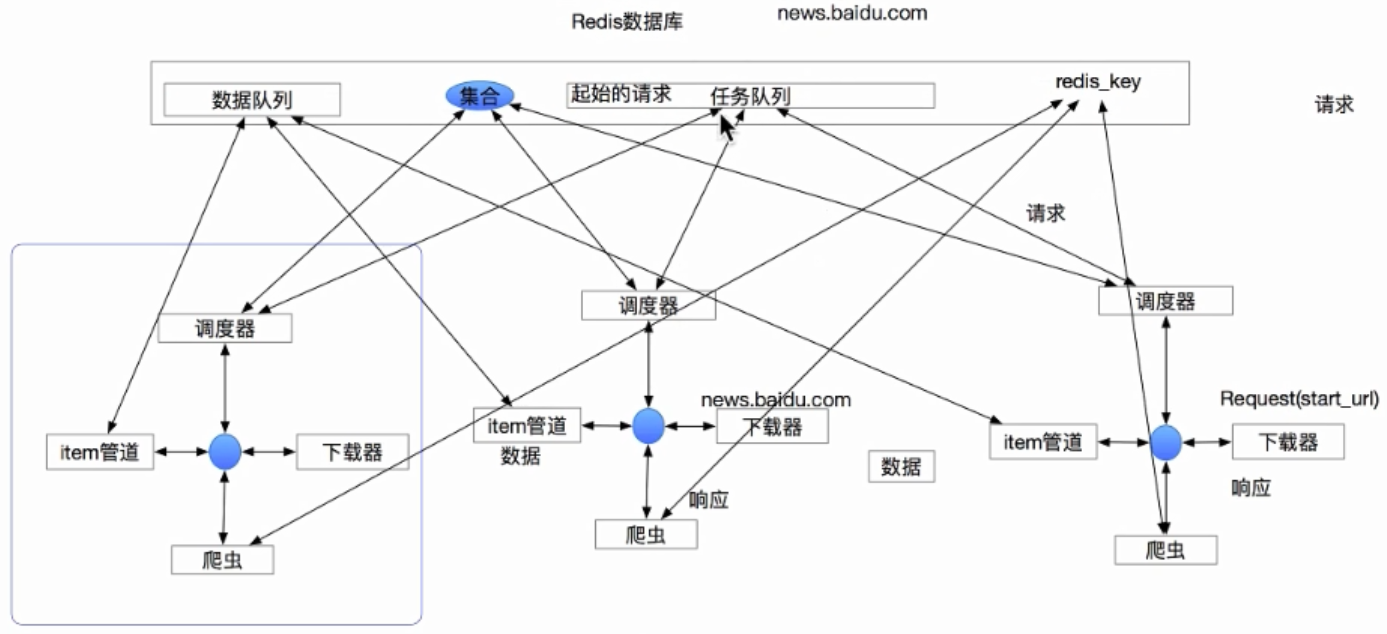

; 5. scrapy_redis的工作流程
5.1 回顾scrapy的流程
思考:那么,在这个基础上,如果需要实现分布式,即多台服务器同时完成一个爬虫,需要怎么做呢?
5.2 scrapy_redis的流程
在scrapy_redis中,所有的待抓取的request对象和指纹去重的request对象都存在所有的服务器公用的redis中
所有的服务器中的scrapy进程公用同一个redis中的request对象的队列
所有的request对象存入redis前,都会通过该redis中的request指纹集合进行判断,之前是否已经存入过
在默认情况下所有的数据会保存在redis中
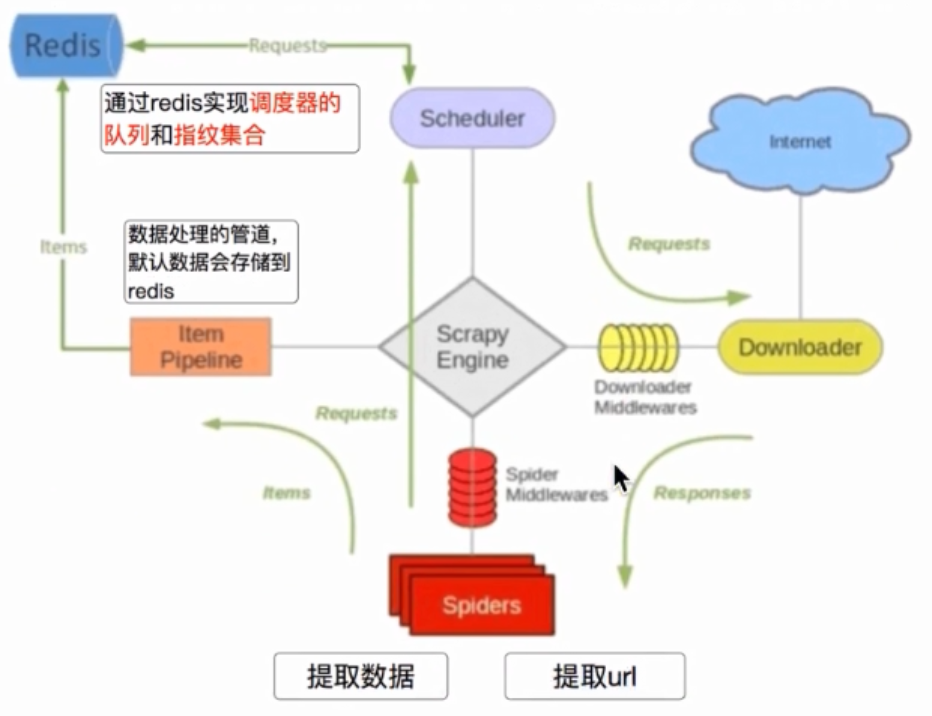
; 二、scrapy_redis实现断点续爬
1. 下载github的demo代码
clone github scrapy-redis源码文件
git clone https://github.com/rolando/scrapy-redis.git
研究项目自带的demo
scrapy-redis/example-project/example
2. 观察dmoz文件
在domz爬虫文件中,实现方式就是之前的crawlspider类型的爬虫,修改allowed_domains与start_urls
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
allowed_domains = ['dmoztools.net']
start_urls = ['http://dmoztools.net/'] # 这里修改了url
# 定义数据提取规则,使用了css选择器
rules = [
Rule(LinkExtractor(
restrict_css=('.top-cat', '.sub-cat', '.cat-item')
), callback='parse_directory', follow=True),
]
def parse_directory(self, response):
for div in response.css('.title-and-desc'):
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}
但是在settings.py中多了以下内容,这几行表示scrapy_redis中重新实现的了去重的类,以及调度器,并且使用RedisPipeline管道类
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
设置重复过滤器的模块
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
设置调取器,scrap_redis中的调度器具备与数据库交互的功能
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
设置当爬虫结束的时候是否保持redis数据库中的去重集合与任务队列
SCHEDULER_PERSIST = True
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
# 当开启该管道,该管道将会把数据存到Redis数据库中
'scrapy_redis.pipelines.RedisPipeline': 400,
}
设置redis数据库
REDIS_URL = "redis://127.0.0.1:6379"
LOG_LEVEL = 'DEBUG'
Introduce an artifical delay to make use of parallelism. to speed up the
crawl.
DOWNLOAD_DELAY = 0.5
3. 运行dmoz爬虫,观察现象
安装
pip install scrapy_redis
运行
cd scrapy-redis/example-project
scrapy crawl dmoz

我们执行domz的爬虫,会发现redis中多了一下三个键:
中止进程后再次运行dmoz爬虫
继续执行程序,会发现程序在前一次的基础之上继续往后执行,所以domz爬虫是一个基于url地址的增量式的爬虫
; 4. scrapy_redis的原理分析
我们从settings.py中的三个配置来进行分析
分别是:
RedisPipeline # 管道类
RFPDupeFilter # 指纹去重类
Scheduler # 调度器类
SCHEDULER_PERSIST # 是否持久化请求队列和指纹集合
4.1 Scrapy_redis之RedisPipeline
RedisPipeline中观察process_item,进行数据的保存,存入了redis中
4.2 Scrapy_redis之RFPDupeFilter
RFPDupeFilter 实现了对request对象的加密
4.3 Scrapy_redis之Scheduler
scrapy_redis调度器的实现了决定什么时候把request对象加入带抓取的队列,同时把请求过的request对象过滤掉
4.4 由此可以总结出request对象入队的条件
request的指纹不在集合中
request的dont_filter为True,即不过滤
start_urls中的url地址会入队,因为他们默认是不过滤
4.5 实现单机断点续爬
改写网易招聘爬虫,该爬虫就是一个经典的基于url地址的增量式爬虫
5. 实现分布式爬虫
5.1 分析demo中代码
打开example-project项目中的myspider_redis.py文件
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'myspider_redis'
redis_key = 'py21'
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
super(MySpider, self).__init__(*args, **kwargs)
def parse(self, response):
return {
'name': response.css('title::text').extract_first(),
'url': response.url,
}
settings.py中关键的配置
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}
REDIS_URL = "redis://127.0.0.1:6379"
打开3个窗口,分别运行
scrapy-redis\example-project\example\spiders
scrapy runspider myspider_redis.py
启用
lpush py21 http://www.badu.com
结果

开发步骤
1.继承自父类为RedisSpider
2.增加了一个redis_key的键,没有start_urls,因为分布式中,如果每台电脑都请求一次start_url就会重复
3.多了__init__方法,该方法不是必须的,可以手动指定allow_domains
4.启动方法:
在每个节点正确的目录下执行scrapy crawl 爬虫名,使该节点的scrapy_redis爬虫程序就位
在共用的redis中 lpush redis_key ‘start_url’,使全部节点真正的开始运行
5.settings.py中关键的配置
5.2 动手实现分布式爬虫步骤

; 三、爬取图书信息-邮乐网(https://ule.com)
1.全部商品分类-图书音像
首页
全部商品分类-图书/音像
计算机/网络
方案:涉及传参,使用spider爬虫
; 2.代码实现
A.创建项目
scrapy startproject ule
B.模型设计
class UleItem(scrapy.Item):
# define the fields for your item here like:
big_category = scrapy.Field()
big_category_link = scrapy.Field()
small_category = scrapy.Field()
small_category_link = scrapy.Field()
bookname = scrapy.Field()
author = scrapy.Field()
link = scrapy.Field()
price = scrapy.Field()
pass
C.创建爬虫
cd ule
scrapy genspider book ule.com
D.修改url:https://search.ule.com/
E.检查domain:ule.com
F.邮乐爬虫-大分类xpath
//*[@id=”fenlei10″]/div/div/div[1]/a
import scrapy
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['ule.com']
start_urls = ['https://search.ule.com/']
def parse(self, response):
# 获取所有图书大分类节点列表
big_node_list = response.xpath('//*[@id="fenlei17"]/div/div/div[1]/a')
for big_node in big_node_list:
big_category = big_node.xpath('./text()').extract_first()
big_category_link = response.urljoin(big_node.xpath('./@href').extract_first())
print(big_category, big_category_link)
G.运行
scrapy crawl book
H.邮乐爬虫-获取小分类
根据大分类xpath获取小分类,上级兄弟节点div下a标签
//*[@id=”fenlei17″]/div[1]/div/div[1]/a/…/following-sibling::div[1]/a
获取所有图书小分类节点列表
small_node_list = big_node.xpath('../following-sibling::div[1]/a')
print(len(small_node_list))
break
I.模拟点击小分类链接
模拟点击小分类链接
yield scrapy.Request(
url=temp['small_category_link'],
callback=self.parse_book_list,
meta={"py21": temp}
)
J.获取图书节点
//*[@id=”wrapper”]/div/div[5]/div[3]/div/ul/li/div
def parse_book_list(self, response):
temp = response.meta['py21']
book_list = response.xpath('//*[@id="wrapper"]/div/div[5]/div[3]/div/ul/li/div')
print(len(book_list))
for book in book_list:
item = UleItem()
# item['big_category'] = temp['big_category']
# item['big_category_link'] = temp['big_category_link']
# item['small_category'] = temp['small_category']
# item['small_category_link'] = temp['small_category_link']
item['bookname'] = book.xpath('./p[2]/a/text()').extract_first().strip()
item['store'] = book.xpath('./p[2]/a/text()').extract_first().strip()
item['link'] = response.urljoin(book.xpath('./p[1]/a[1]/@href').extract_first())
# strong标签获取不到值
# item['price'] = book.xpath('./div/span/strong/text()').extract_first()
print(item)
运行效果

K.邮乐爬虫-图书价格
strong标签获取不到值,extract
通过分析可以从去详情的json获取
https://item-service.ule.com/itemserviceweb/api/v1/price/queryListingPrice?listId=3767119
strong标签获取不到值,extract
item['price'] = book.xpath('./div/span/strong').strip()
获取图书编号
skuid = book.xpath('./p[1]/a[2]/@data-listingid').extract_first()
print("1111111111111111111111: ", skuid)
pri_url = 'https://item-service.ule.com/itemserviceweb/api/v1/price/queryListingPrice?listId=' + skuid
yield scrapy.Request(url=pri_url, callback=self.parse_price, meta={'meta_1': item})
print(item)
def parse_price(self, response):
item = response.meta['meta_1']
dict_data = json.loads(response.body)
# print("222222222: ", dict_data)
item['price'] = dict_data['ulePrice']
yield item
3.邮乐爬虫-修改为分布式爬虫
A.导入分布爬虫类
from scrapy_redis.spiders import RedisSpider
B.继承分布式爬虫类
class BookSpider(RedisSpider):
C.注销 allowed_domains和start_urls
allowed_domains = [‘ule.com’]
start_urls = [‘https://search.ule.com/’]
D.设置redis_key
redis_key = ‘py21’
E.设置__init__
def __init__(self, *args, **kwargs):
domain = kwargs.pop('domain', '')
self.allowed_domains = list(filter(None, domain.split(',')))
super(BookSpider, self).__init__(*args, **kwargs)
D.修改settings
SPIDER_MODULES = ['ule.spiders']
NEWSPIDER_MODULE = 'ule.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
设置重复过滤器的模块
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
设置调取器,scrap_redis中的调度器具备与数据库交互的功能
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
设置当爬虫结束的时候是否保持redis数据库中的去重集合与任务队列
SCHEDULER_PERSIST = True
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
#SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
ITEM_PIPELINES = {
# 'ule.pipelines.ExamplePipeline': 300,
# 当开启该管道,该管道将会把数据存到Redis数据库中
'scrapy_redis.pipelines.RedisPipeline': 400,
}
设置redis数据库
REDIS_URL = "redis://172.16.123.223:6379"
LOG_LEVEL = 'DEBUG'
Introduce an artifical delay to make use of parallelism. to speed up the
crawl.
DOWNLOAD_DELAY = 1
运行:
cd ule\spiders
scrapy runspider book.py
测试:
lpush py21 https://search.ule.com/
Original: https://blog.csdn.net/u012441595/article/details/121742519
Author: IT瘾君
Title: Scrapy-Redis分布式爬虫框架详解-邮乐网(ule.com)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789235/
转载文章受原作者版权保护。转载请注明原作者出处!