

@Scrapy学习
Scrapy使用异步网络库处理网络通讯,
安装Scrapy
pip install Scrapy
可能遇到的坑
报错1
VC++14.0 Twisted
解决方法
离线安装,访问网站:
https://www.lfd.uci.edu/~gohlke/pythonlibs/
根据版本选择文件
使用命令进行安装离线文件
pip install xxx.whl
报错2
scrapy bencn 运行报错
解决方法
pip install pywin32
Scrapy原理
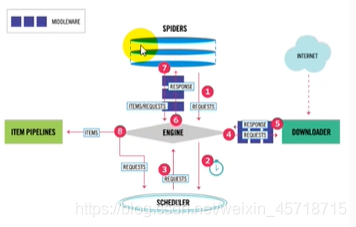

很重要!
; 直接项目
新建项目
采集目标
采集西刺网的ip代理
scrapy startproject xicidailiSpider
D:\untitled1>scrapy startproject xicidailiSpider
New Scrapy project 'xicidailiSpider', using template directory 'd:\anaconda3\lib\site-packages\scrapy\templates\project', created in:
D:\untitled1\xicidailiSpider
You can start your first spider with:
cd xicidailiSpider
scrapy genspider example example.com
创建成功之后使用cd命令移动到文件夹中:
D:\untitled1>cd D:\untitled1\xicidailiSpider

移动到有这个文件的目录下。
D:\untitled1\xicidailiSpider>scrapy genspider xicidaili xicidaili.com
其中xicidaili是爬虫名字(不能和项目名重复),xicidaili.com是域名。
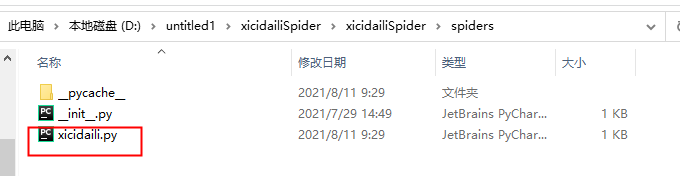
这个时候就会产生一个新的文件,这个文件就是我们的爬虫文件。
import scrapy
class XicidailiSpider(scrapy.Spider):
name = 'xicidaili'
allowed_domains = ['xicidaili.com']
start_urls = ['http://xicidaili.com/']
def parse(self, response):
pass
采集数据
1.正则表达式(基础 必回 难掌握)
2.XPath–》从html中提取数据
3.CSS
对于某些网站代理ip和端口号分开的情况,可以先用xpath对整个tr进行提取也就是 //tr 然后使用for循环遍历所有的提取项,再使用xpath进行提取,提取的时候使用 . 开头写xpath语句, . 的作用是表示当前的html中筛选。
import scrapy
class XicidailiSpider(scrapy.Spider):
name = 'xicidaili'
allowed_domains = ['xiladaili.com']
start_urls = ['http://www.xiladaili.com/gaoni/']
def parse(self, response):
data = response.xpath("/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()")
print(data)
pass
这里临时换个网址,因为我在学的时候西刺网已经无了
运行代码:
scrapy crawl xicidaili
最后的xicidaili是我们的爬虫名。
如果遇到反爬可以尝试增加user-agent
在settings.py文件中修改。

2021-08-11 10:02:04 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.xiladaili.com/gaoni/> (referer: None)
[<Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='103.103.3.6:8080'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='27.192.200.7:9000'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='113.237.3.178:9999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='61.37.223.152:8080'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='118.117.188.171:3256'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='45.228.188.241:999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='104.254.238.122:20171'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='211.24.95.49:47615'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='47.104.66.204:80'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='191.101.39.193:80'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='112.104.28.117:3128'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='103.205.15.97:8080'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='185.179.30.130:8080'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='190.108.88.97:999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='81.30.220.116:8080'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='218.88.204.125:3256'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='178.62.56.172:80'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='178.134.208.126:50824'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='193.149.225.163:80'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='182.87.136.228:9999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='175.42.122.142:9999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='192.109.165.128:80'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='181.3.91.56:10809'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='182.84.144.91:3256'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='188.166.125.206:38892'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='118.194.242.57:80'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='167.172.180.46:33555'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='58.255.7.90:9999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='190.85.244.70:999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='118.99.100.164:8080'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='182.84.145.181:3256'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='94.180.72.40:3128'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='45.236.168.183:999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='01.20.217.52:8080'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='175.146.211.158:9999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='114.233.189.228:9999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='125.113.133.47:8118'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='171.35.213.44:9999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='131.153.151.250:43064'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='106.45.220.42:3256'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='177.229.194.30:999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='191.101.39.110:80'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='195.46.124.94:4444'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='113.237.1.179:9999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='182.84.144.12:3256'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='36.56.102.35:9999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='131.153.151.250:8003'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='45.225.88.220:999'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='195.9.61.22:45225'>, <Selector xpath='/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()' data='43.239.152.254:8080'>]
数据很乱而且没有拿出来,修改代码:
import scrapy
class XicidailiSpider(scrapy.Spider):
name = 'xicidaili'
allowed_domains = ['xiladaili.com']
start_urls = ['http://www.xiladaili.com/gaoni/']
def parse(self, response):
data = response.xpath("/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()")
print(data.getall())
pass
2021-08-11 10:10:36 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.xiladaili.com/gaoni/> (referer: None)
['103.103.3.6:8080', '27.192.200.7:9000', '113.237.3.178:9999', '61.37.223.152:8080', '118.117.188.171:3256', '45.228.188.241:999', '104.254.238.122:20171', '211.24.95.49:47615', '47.104.66.204:80', '191.101.39.193:80', '112.104.28.117:3128', '103.205.15.97:8080', '185.179.30.130:8080', '190.108.88.97:999', '81.30.220.116:8080', '218.88.204.125:3256', '178.62.56.172:80', '178.134.208.126:50824', '193.149.225.163:80', '182.87.136.228:9999', '175.42.122.142:9999', '192.109.165.128:80', '181.3.91.56:10809', '182.84.144.91:3256', '188.166.125.206:38892', '118.194.242.57:80', '167.172.180.46:33555', '58.255.7.90:9999', '190.85.244.70:999', '118.99.100.164:8080', '182.84.145.181:3256', '94.180.72.40:3128', '45.236.168.183:999', '01.20.217.52:8080', '175.146.211.158:9999', '114.233.189.228:9999', '125.113.133.47:8118', '171.35.213.44:9999', '131.153.151.250:43064', '106.45.220.42:3256', '177.229.194.30:999', '191.101.39.110:80', '195.46.124.94:4444', '113.237.1.179:9999', '182.84.144.12:3256', '36.56.102.35:9999', '131.153.151.250:8003', '45.225.88.220:999', '195.9.61.22:45225', '43.239.152.254:8080']
如果只有一个元素使用get()就行如果多个元素使用getall()
翻页操作
import scrapy
class XicidailiSpider(scrapy.Spider):
name = 'xicidaili'
allowed_domains = ['xiladaili.com']
start_urls = ['http://www.xiladaili.com/gaoni/']
def parse(self, response):
data = response.xpath("/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()")
print(data.getall())
next_page = response.xpath("/html/body/div/div[3]/nav/ul/li[16]/a/@href")
if next_page:
print(next_page.get())
pass
2021-08-11 10:24:34 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2021-08-11 10:24:35 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.xiladaili.com/gaoni/> (referer: None)
['103.103.3.6:8080', '27.192.200.7:9000', '113.237.3.178:9999', '61.37.223.152:8080', '118.117.188.171:3256', '45.228.188.241:999', '104.254.238.122:20171', '211.24.95.49:47615', '47.104.66.204:80', '191.101.39.193:80', '112.104.28.117:3128', '103.205.15.97:8080', '185.179.30.130:8080', '190.108.88.97:999', '81.30.220.116:8080', '218.88.204.125:3256', '178.62.56.172:80', '178.134.208.126:50824', '193.149.225.163:80', '182.87.136.228:9999', '175.42.122.142:9999', '192.109.165.128:80', '181.3.91.56:10809', '182.84.144.91:3256', '188.166.125.206:38892', '118.194.242.57:80', '167.172.180.46:33555', '58.255.7.90:9999', '190.85.244.70:999', '118.99.100.164:8080', '182.84.145.181:3256', '94.180.72.40:3128', '45.236.168.183:999', '01.20.217.52:8080', '175.146.211.158:9999', '114.233.189.228:9999', '125.113.133.47:8118', '171.35.213.44:9999', '131.153.151.250:43064', '106.45.220.42:3256', '177.229.194.30:999', '191.101.39.110:80', '195.46.124.94:4444', '113.237.1.179:9999', '182.84.144.12:3256', '36.56.102.35:9999', '131.153.151.250:8003', '45.225.88.220:999', '195.9.61.22:45225', '43.239.152.254:8080']
/gaoni/2/
2021-08-11 10:24:35 [scrapy.core.engine] INFO: Closing spider (finished)
2021-08-11 10:24:35 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 303,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 39781,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'elapsed_time_seconds': 0.542365,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2021, 8, 11, 2, 24, 35, 437527),
'log_count/DEBUG': 1,
'log_count/INFO': 10,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2021, 8, 11, 2, 24, 34, 895162)}
2021-08-11 10:24:35 [scrapy.core.engine] INFO: Spider closed (finished)
获取到的网址并不全,所以需要进行网址的拼接。
import scrapy
class XicidailiSpider(scrapy.Spider):
name = 'xicidaili'
allowed_domains = ['xiladaili.com']
start_urls = ['http://www.xiladaili.com/gaoni/']
def parse(self, response):
data = response.xpath("/html/body/div/div[3]/div[2]/table/tbody/tr/td[1]/text()")
print(data.getall())
next_page = response.xpath("/html/body/div/div[3]/nav/ul/li[16]/a/@href")
if next_page:
print(next_page.get())
next_url = response.urljoin(next_page)
yield scrapy.Request(next_url,callback=self.parse)
pass
回调函数别写 () 。 此处不再尝试,怕被封。。
Original: https://blog.csdn.net/weixin_45718715/article/details/119574844
Author: 亚古兽超进化
Title: Scrapy
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789075/
转载文章受原作者版权保护。转载请注明原作者出处!