

文章目录
- 前言
- 一、架构介绍
* - 引擎(EGINE)
- 调度器(SCHEDULER)
- 下载器(DOWLOADER)
- 爬虫(SPIDERS)
- 项目管道(ITEM PIPLINES)
- 下载器中间件(Downloader Middlewares)
- 爬虫中间件(Spider Middlewares)
- 一、安装
- 一、项目创建
* - 1 创建scrapy项目
- 2 创建爬虫
- 3启动爬虫,爬取数据
- 二、目录介绍
- 三、解析数据
- 四、配置
* - 1.基础配置
- 2.增加爬虫的爬取效率配置
- 五、持久化方案
- 第一种:parse返回值(很少使用)
- 第二种:pipline模式(通用的)
- 六、爬虫和下载中间件
- 七、加代理,cookie,header
* - 1.加代理
- 2.cookie
- 3.header
- 八、集成selenium
- 九、去重规则源码分析
- 十、布隆过滤器使用
* - 安装
- 1.定长的布隆过滤器
- 2.可自动扩容的布隆过滤器
- 3.布隆过滤器方法
- 十一、redis实现分布式爬虫
前言
Scrapy一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速、简单、可扩展的方式从网站中提取所需的数据。但目前Scrapy的用途十分广泛,可用于如数据挖掘、监测和自动化测试等领域,也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫
一、架构介绍
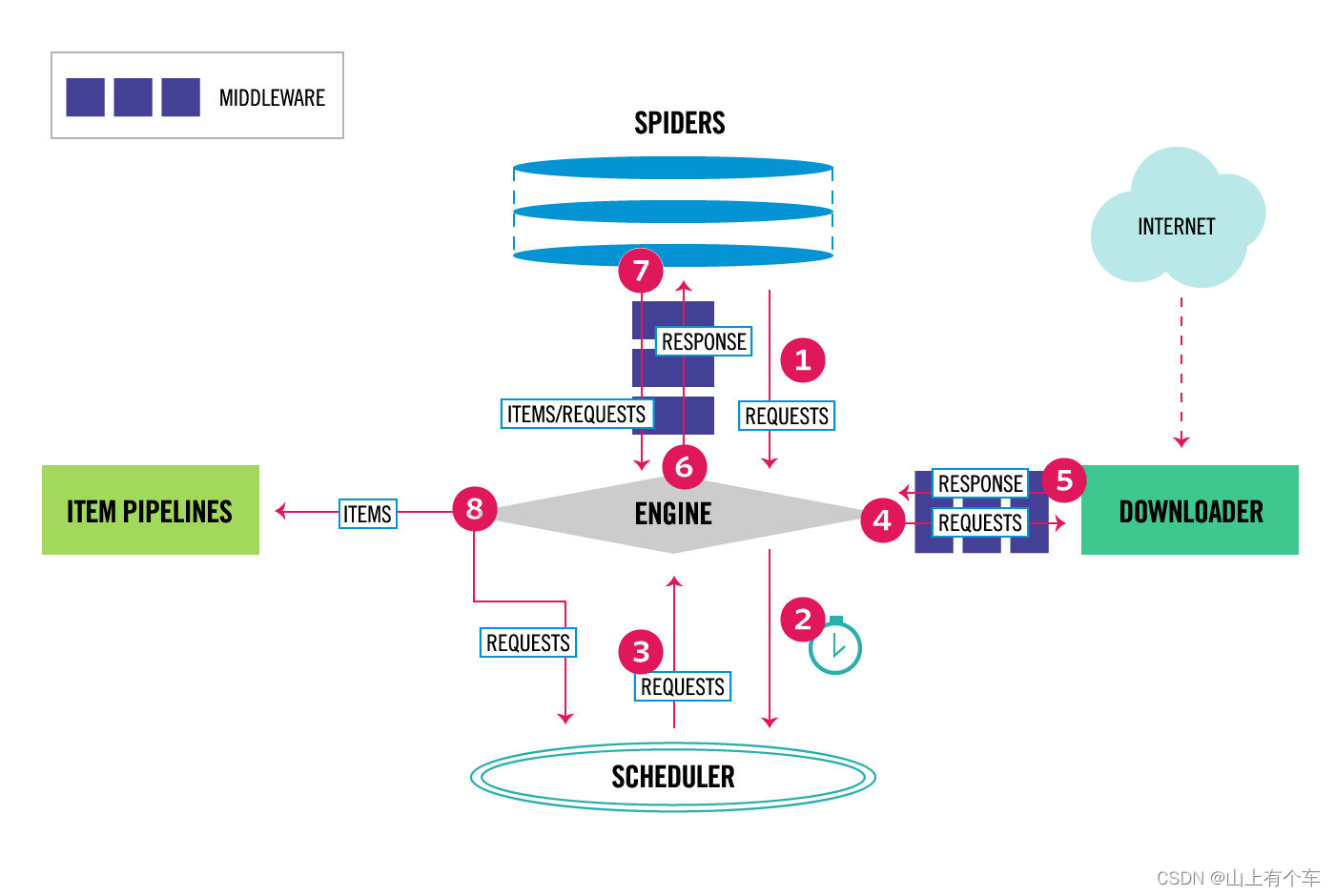

; 引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。
调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,
爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
一、安装
针对于mac、linux基本不会出现问题
pip3 install scrapy
针对windows有概率失败
失败解决方案:
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
2、pip3 install lxml
3、pip3 install pyopenssl
4、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
一、项目创建
scrapy与django类似
1 创建scrapy项目
scrapy startproject 项目名
2 创建爬虫
scrapy genspider 爬虫名 爬取网址
3启动爬虫,爬取数据
方法一指令启动:
scrapy crawl 爬虫名字 –nolog(该参数为不打印日志,可忽略)
方法二使用脚本来启动:
项目路径下新建main.py
from scrapy.cmdline import execute
execute(['scrapy','crawl','爬虫名','--nolog'])
二、目录介绍
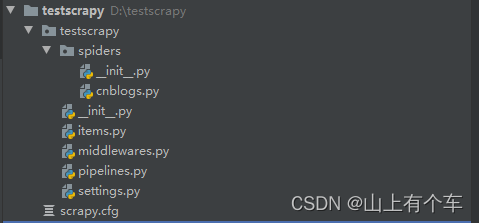
firstscrapy
firstscrapy
spiders
cnblogs.py
items.py
middlewares.py
pipelines.py
settings.py
scrapy.cfg
三、解析数据
分析数据写在爬虫文件中的parse方法里(spiders下的爬虫文件,本文为cnblogs.py)
response对象有css方法和xpath方法
- css中写css选择器
- xpath中写xpath选择
俩种方法可以独立使用也可以混合使用,俩种方法找到的是标签对象,会转化为类对象,所以可以根据类对象再次进行标签查找
示例:
-xpath取文本内容
'.//a[contains(@class,"link-title")]/text()'
-xpath取属性
'.//a[contains(@class,"link-title")]/@href'
-css取文本
'a.link-title::text'
-css取属性
'img.image-scale::attr(src)'
取到的标签对象可以是多个或者一个再选择对应的方法即可(使用以下俩个方法获取的标签不再是类对象,无法再次对其下内容进行查找)
.extract_first() 取一个,使得提取内容转换为unicodez字符串
.extract() 取所有,使得提取内容转换为unicodez字符串,返回一个list
示例代码:
import scrapy
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['cnblogs.com']
start_urls = ['http://cnblogs.com/']
def parse(self, response):
articles = response.xpath('.//article[@class="post-item"]')
for article in articles:
title = article.xpath('.//a[@class="post-item-title"]/text()').extract_first()
url = article.xpath('.//a[@class="post-item-title"]/@href').extract_first()
desc = article.xpath('.//p[@class="post-item-summary"]/text()').extract()
author = article.xpath('.//footer[@class="post-item-foot"]/a/span/text()').extract_first()
四、配置
修改settings.py
1.基础配置
ROBOTSTXT_OBEY = False
LOG_LEVEL='ERROR'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
SPIDER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsSpiderMiddleware': 543,
}
DOWNLOADER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'cnblogs.pipelines.CnblogsPipeline': 300,
}
2.增加爬虫的爬取效率配置
CONCURRENT_REQUESTS = 100
LOG_LEVEL = 'INFO'
COOKIES_ENABLED = False
RETRY_ENABLED = False
DOWNLOAD_TIMEOUT = 10
五、持久化方案
第一种:parse返回值(很少使用)
解析函数中parse,要return [{},{},{}],返回一个列表套字典的数据
def parse(self, response):
articles = response.xpath('.//article[@class="post-item"]')
article_list = []
for article in articles:
item = CnblogsItem()
title = article.xpath('.//a[@class="post-item-title"]/text()').extract_first()
url = article.xpath('.//a[@class="post-item-title"]/@href').extract_first()
desc = article.xpath('.//p[@class="post-item-summary"]/text()').extract()
author = article.xpath('.//footer[@class="post-item-foot"]/a/span/text()').extract_first()
article_list.append({'title':title, 'url':url, 'desc':desc, 'desc':desc, 'author':author, })
return article_list
使用指令 scrapy crawl cnblogs -o 文件名(json,csv等后缀)
scrapy crawl cnblogs -o data.json
第二种:pipline模式(通用的)
1.在items.py中写一个类,继承scrapy.Item
在类中编写属性
import scrapy
class CnblogsItem(scrapy.Item):
title = scrapy.Field()
desc = scrapy.Field()
pub_time = scrapy.Field()
author = scrapy.Field()
url = scrapy.Field()
content = scrapy.Field()
2.在爬虫中导入类,实例化得到对象,把要保存的数据放到对象中
import scrapy
from scrapy import Request
from testscrapy.items import CnblogsItem
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['cnblogs.com']
start_urls = ['http://cnblogs.com/']
def parse(self, response):
articles = response.xpath('.//article[@class="post-item"]')
for article in articles:
item = CnblogsItem()
title = article.xpath('.//a[@class="post-item-title"]/text()').extract_first()
url = article.xpath('.//a[@class="post-item-title"]/@href').extract_first()
desc = article.xpath('.//p[@class="post-item-summary"]/text()').extract()
author = article.xpath('.//footer[@class="post-item-foot"]/a/span/text()').extract_first()
res_desc = desc[0].replace('\n', '').replace(' ', '')
if not res_desc:
res_desc = desc[1].replace('\n', '').replace(' ', '')
item['title'] = title
item['url'] = url
item['desc'] = desc
item['author'] = author
item['desc'] = res_desc
yield item
3.修改配置文件,指定pipline,数字表示优先级,越小越大
ITEM_PIPELINES = {
'crawl_cnblogs.pipelines.CrawlCnblogsPipeline': 300,
}
4.写一个pipline:CrawlCnblogsPipeline
-open_spider:数据初始化,打开文件,打开数据库链接
-process_item:真正存储的地方
-一定不要忘了return item,交给后续的pipline继续使用
-close_spider:销毁资源,关闭文件,关闭数据库链接
pipelines.py
class CnblogsFilePipeline:
def open_spider(self, spider):
print('open')
self.f = open('cnblogs.txt', 'w', encoding='utf-8')
def close_spider(self, spider):
print('close')
self.f.close()
def process_item(self, item, spider):
self.f.write('标题:%s,作者:%s\n' % (item['title'], item['author']))
return item
import pymysql
class CnblogsMysqlPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(user='root',
password="密码",
host='127.0.0.1',
port=3306,
database='cnblogs')
self.cursor = self.conn.cursor()
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
def process_item(self, item, spider):
sql = 'insert into article (title,desc,url,pub_time,author,content) values (%s,%s,%s,%s,%s,%s)'
self.cursor.execute(sql, args=[item['title'], item['desc'], item['url'], item['pub_time'], item['author'],
item['content']])
self.conn.commit()
return item
六、爬虫和下载中间件
在settings.py中可看到以下配置
SPIDER_MIDDLEWARES 爬虫中间件 (了解即可,用的少)
SPIDER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsSpiderMiddleware': 543,
}
DOWNLOADER_MIDDLEWARES 下载中间件(用的多)
DOWNLOADER_MIDDLEWARES = {
'cnblogs.middlewares.CnblogsDownloaderMiddleware': 543,
}
最重要的是下载中间件,里面的两个方法
middlewares.py
class CnblogsDownloaderMiddleware:
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
1.加代理
在下载中间件中重写process_request
def process_request(self, request, spider):
request.meta['proxy'] = 'http://221.6.215.202:9091'
return None
在中间件中重写process_request
def process_request(self, request, spider):
request.cookies['name']='bbc'
return None
3.header
在中间件中重写process_request
def process_request(self, request, spider):
request.headers['Auth']='asdfasdfasdfasdf'
request.headers['USER-AGENT']='ssss'
八、集成selenium
scrapy框架的下载器,是无法触发js的,当我们需要的内容时通过js获取到的,可以在scrapy框架中对下载器进行selenium的集成,实质就是将一些需要触发js的请求交由selenium来处理,其他的请求照常走下载器。
第一步:
在爬虫类中为需要使用selenium的爬虫添加一个类属性以及一个类方法
import scrapy
from selenium import webdriver
class CnblogsSpider(scrapy.Spider):
name = 'cnblogs'
allowed_domains = ['cnblogs.com']
start_urls = ['http://cnblogs.com/']
driver = webdriver.Edge()
def close(spider, reason):
spider.driver.close()
第二步:
创建一个下载中间件,重写process_request
class CnblogsDownloaderMiddlewareProxy:
def process_request(self, request, spider):
url=request.url
if 'sitehome' in url:
spider.driver.get(url)
response=HtmlResponse(url=url,body=spider.driver.page_source.encode('utf-8'))
return response
else:
return None
九、去重规则源码分析
scrapy 实现了去重,爬过的网址不会再爬了
scrapy使用了集合进行去重
第一步:
找到scrapy的配置文件
scrapy.settings下的default_settings.py中
找到DUPEFILTER_CLASS = ‘scrapy.dupefilters.RFPDupeFilter’
第二步:
找到RFPDupeFilter,该类负责处理指纹判断是否爬取过
class RFPDupeFilter(BaseDupeFilter):
def request_seen(self, request: Request) -> bool:
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + '\n')
return False
第三步:
找到爬虫对象执行的入口
在scrapy.spiders下的_ init _.py中
class Spider(object_ref):
def start_requests(self):
if not self.start_urls and hasattr(self, 'start_url'):
raise AttributeError(
"Crawling could not start: 'start_urls' not found "
"or empty (but found 'start_url' attribute instead, "
"did you miss an 's'?)")
for url in self.start_urls:
yield Request(url, dont_filter=True)
第四步:
爬虫执行后在调度器中去重
在scrapy.core下的scheduler中
class Scheduler(BaseScheduler):
def enqueue_request(self, request: Request) -> bool:
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
dqok = self._dqpush(request)
if dqok:
self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider)
else:
self._mqpush(request)
self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider)
self.stats.inc_value('scheduler/enqueued', spider=self.spider)
return True
以上就是scrapy框架的去重解析
十、布隆过滤器使用
中小型的去重使用集合、字典等去重比较适合,并发量大了之后再使用这些方式进行就会极大的影响效率和内存。
这个时候可以使用布隆过滤器。
布隆过滤器是以bit为单位的数组,数组初始状态每一位都是0,当需要去重的数据经过哈希函数处理后,将数组对应位置的0变为1,一但哈希函数计算的位置都是1就表明该数据已存在,反之只要有一位不为1就表示该数据此前没有存在过。布隆过滤器,占用空间很小,但只能进行过滤对比,无法取出值,所以应用时需要考虑是否需要取出已存在的值。

; 安装
pip3 install pybloom_live
1.定长的布隆过滤器
from pybloom_live import BloomFilter
bf = BloomFilter(capacity=1000)
url='www.baidu.com'
bf.add(url)
print(url in bf)
print("www.liuqingzheng.top" in bf)
2.可自动扩容的布隆过滤器
from pybloom_live import ScalableBloomFilter
bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)
url = "www.cnblogs.com"
url2 = "www.liuqingzheng.top"
bloom.add(url)
print(url in bloom)
print(url2 in bloom)
3.布隆过滤器方法
add、madd
布隆过滤器对象.add {key} {item}
布隆过滤器对象.madd {key} {item} [item...]
往过滤器中添加元素。如果key不存在,过滤器会自动创建。
exists、 mexists
布隆过滤器对象.exists {key} {item}
布隆过滤器对象.mexists {key} {item} [item...]
判断过滤器中是否存在该元素,不存在返回0,存在返回1。
十一、redis实现分布式爬虫
第一步:
安装scrapy-redis
pip3 install scrapy-redis
第二步:
改造爬虫类
from scrapy_redis.spiders import RedisSpider
class CnblogSpider(RedisSpider):
name = 'cnblog_redis'
allowed_domains = ['cnblogs.com']
redis_key = 'myspider:start_urls'
def parse(self, response):
...
第三步:
配置文件配置
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
第四步:
在多台机器上启动scrapy项目
第五步:
向redis放入一个起始url,之后分布式项目才会开始爬取
可以在redis中添加、或者使用脚本添加
lpush myspider:start_urls value http://www.cnblogs.com/
Original: https://blog.csdn.net/kdq18486588014/article/details/126164451
Author: 山上有个车
Title: scrapy框架——架构介绍、安装、项目创建、目录介绍、使用、持久化方案、集成selenium、去重规则源码分析、布隆过滤器使用、redis实现分布式爬虫
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789059/
转载文章受原作者版权保护。转载请注明原作者出处!