

scrapy中间件:
*
–
+ scrapy中间件介绍
+ 下载器中间件
+
* 添加ip代理
* UA中间件
* cookies中间件
+ 爬虫中间件
+
* 核心方法
scrapy中间件介绍
=
=
scrapy中间件是scrapy框架的重要组成部分
分为两大种类:下载器中间件( DownloaderMiddleware)和爬虫中间件( SpiderMiddleware)
图中4、5为下载器中间件
图中6、7为爬虫中间件
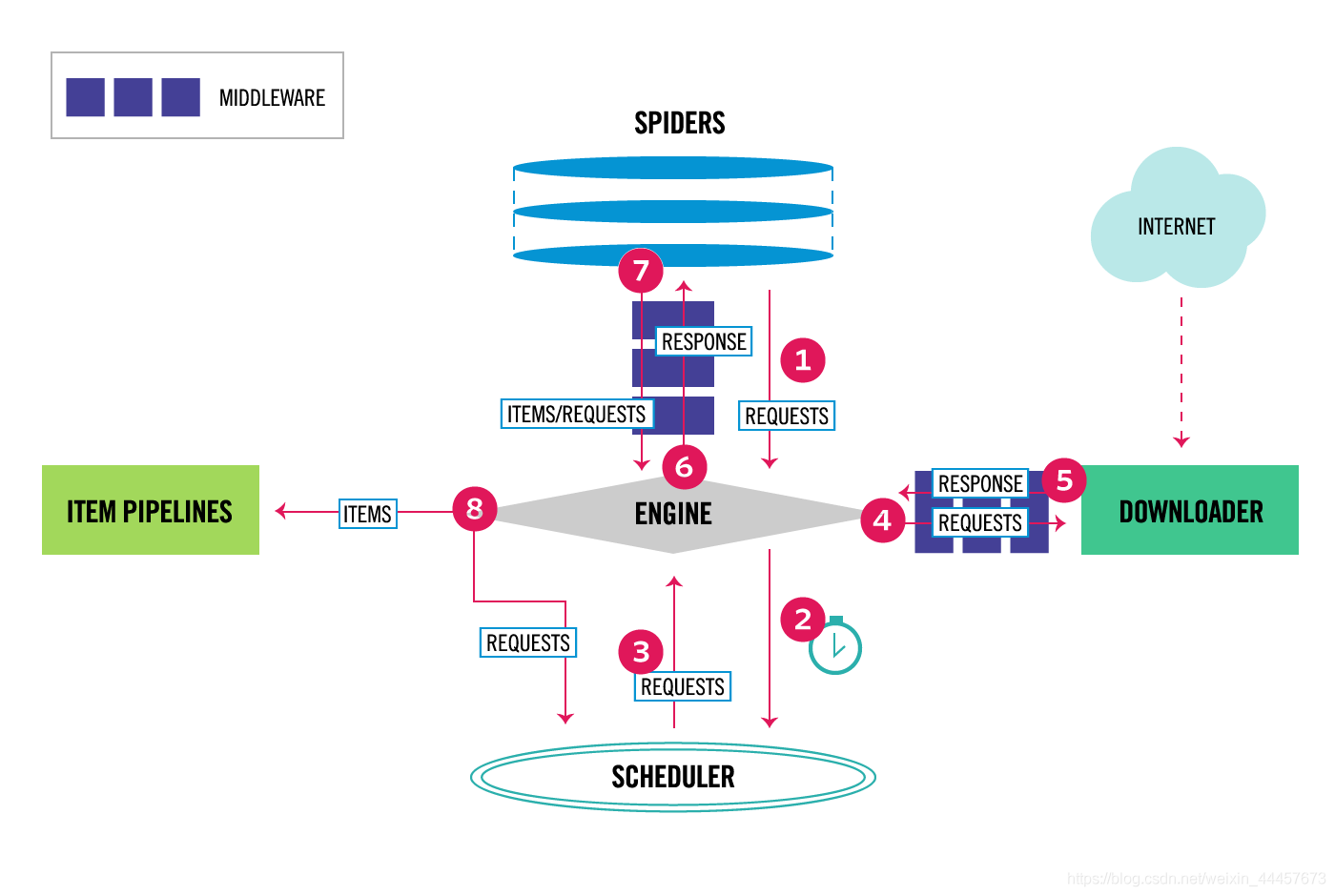

下载器中间件是Scrapy请求/响应处理的钩子框架。这是一个轻,低层次的系统,全球范围内改变斯拉皮的请求和响应。
下载器中间件主要功能:
1、添加ip代理
2、添加cookie
3、添加UA
4、请求重试
Spider中间件是一个钩子框架,可以钩住Scrapy的Spider处理机制,在该机制中,您可以插入自定义功能来处理发送到的响应。 蜘蛛 用于处理和处理由spider生成的请求和项目。
爬虫中间件主要功能:
1、处理引擎传递给爬虫的响应
2、处理爬虫传递给引擎的请求
3、处理爬虫传递给引擎的数据项
其中,爬虫中间件在以下情况中会被调用:
1.当运行到 yield scrapy.Request()或者 yield item 的时候,爬虫中间件的
2.process_spider_output()方法被调用。 当爬虫本身的代码出现了 Exception 的时候,爬虫中间件的
3.process_spider_exception()方法被调用。 当爬虫里面的某一个回调函数 parse_xxx()被调用之前,爬虫中间件的
4. process_spider_input()方法被调用。 当运行到 start_requests()的时候,爬虫中间件的
5. process_start_requests()方法被调用。
=
=
首先,先创建一个spider用于学习middleware
打开其中的middlewares.py
初始化样子:
from scrapy import signals
from itemadapter import is_item, ItemAdapter
class MiddlewareproSpiderMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
return None
def process_spider_output(self, response, result, spider):
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
pass
def process_start_requests(self, start_requests, spider):
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class MiddlewareproDownloaderMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
return response
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
可以看到分为两类:
class MiddlewareproDownloaderMiddleware:
class MiddlewareproSpiderMiddleware:
以下依次介绍
=
=
=
下载器中间件
添加ip代理
测试ip地址可访问网站 http://httpbin.org/ip
方法一:
不用中间件。重写start_ requests方法,在发送请求时传入ip—proxy
yield scrapy.Request(self.start_urls[0], meta={"proxy": proxy})
方法二:
使用中间件。
第一种:静态ip中间件
test:
import scrapy
class MiddlewaretestSpider(scrapy.Spider):
name = 'middlewareTest'
start_urls = ['http://httpbin.org/ip']
def parse(self, response):
print('IP地址--> ', response.text)
在middlewares中重写编写一个类:
class TestProxyMiddleware(object):
def process_request(self, request, spider):
proxy = "http://113.57.26.117"
request.meta["proxy"] = proxy
在settings中打开;
DOWNLOADER_MIDDLEWARES = {
'middlewarePro.middlewares.TestProxyMiddleware':543,
}
结果:
IP地址--> {
"origin": "113.57.26.117"
}
第二种:动态ip
动态ip的创建和静态ip创建原理相似,只是每次给request的meta赋予不同的proxy参数,这就要依靠代理池俩实现。
代理池就是有很多ip组成的字典,每次随机抽取一个ip,如果这个代理池足够大,就可以降低重复的概率
test不变
middlewares:
先导入两个类:
import random
from scrapy.utils.project import get_project_settings
class TestProxyMiddleware(object):
def __init__(self):
self.settings = get_project_settings()
def process_request(self, request, spider):
proxy = random.choice(self.settings['PROXIES'])
request.meta["proxy"] = proxy
settings中接入一个代理池:
PROXIES = [
'http://114.217.243.25:8118',
'http://125.37.175.233:8118',
'http://1.85.116.218:8118'
]
=
=
UA中间件
UA中间件的设置和代理的设置基本相同
middlewares中新建一个类 UAMiddleware
class UAMiddleware(object):
def process_request(self, request, spider):
ua = random.choice(settings['USER_AGENT_LIST'])
request.headers['User-Agent'] = ua
在settings中添加一个含UA数据的字典即可。
USER_AGENT_LIST = [
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36",
"Dalvik/1.6.0 (Linux; U; Android 4.2.1; 2013022 MIUI/JHACNBL30.0)",
"Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; HUAWEI MT7-TL00 Build/HuaweiMT7-TL00) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"AndroidDownloadManager",
"Apache-HttpClient/UNAVAILABLE (java 1.4)",
"Dalvik/1.6.0 (Linux; U; Android 4.3; SM-N7508V Build/JLS36C)",
"Android50-AndroidPhone-8000-76-0-Statistics-wifi",
"Dalvik/1.6.0 (Linux; U; Android 4.4.4; MI 3 MIUI/V7.2.1.0.KXCCNDA)",
"Dalvik/1.6.0 (Linux; U; Android 4.4.2; Lenovo A3800-d Build/LenovoA3800-d)",
"Lite 1.0 ( http://litesuits.com )",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 Safari/537.36 SE 2.X MetaSr 1.0",
"Mozilla/5.0 (Linux; U; Android 4.1.1; zh-cn; HTC T528t Build/JRO03H) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30; 360browser(securitypay,securityinstalled); 360(android,uppayplugin); 360 Aphone Browser (2.0.4)",
]
记得在settings中开启该通道;
DOWNLOADER_MIDDLEWARES = {
'middlewarePro.middlewares.TestProxyMiddleware':543,
'middlewarePro.middlewares.UAMiddleware' : 544,
}
=
=
cookies值主要用于爬取一些需要登录的网站,保持登录状态。
设置cookies中间件首先要有若干cookies值,获取cookies可以用selenium登录要爬取的网址,然后下载cookies,多重复几遍就可得到多个cookies值
具体操作和上述类似
=
=
爬虫中间件
Spider middleware主要有三个作用:
1、在downloader生成request发送给spider之前,对request进行处理
2、在spider生成request发送给scheduler之前,对request进行处理
3、在spider生成request发送给item pipeline之前,对item进行处理
核心方法
process_ spider _input(response, spider)
process_spider_output(response, result, spider)
process_spider_exception(response, exception, spider)
process_start_requests(start_requests, spider)
上述只需要其中一个方法就可以定义一个spider middleware。
Original: https://blog.csdn.net/weixin_44457673/article/details/118858892
Author: 独角兽小马
Title: scrapy中间件详解
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/789045/
转载文章受原作者版权保护。转载请注明原作者出处!