

1.分布式部署:
得先安装scrapy_redis库
分布式的安装及讲解:https://editor.csdn.net/md/?articleId=124085978
需要下载redis
redis数据库的安装:https://blog.csdn.net/weixin_44826986/article/details/123700992
在Scrapy项目的 setting.py文件中加入:
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://192.168.1.102:6379'
SCHEDULER_PERSIST = True
即可
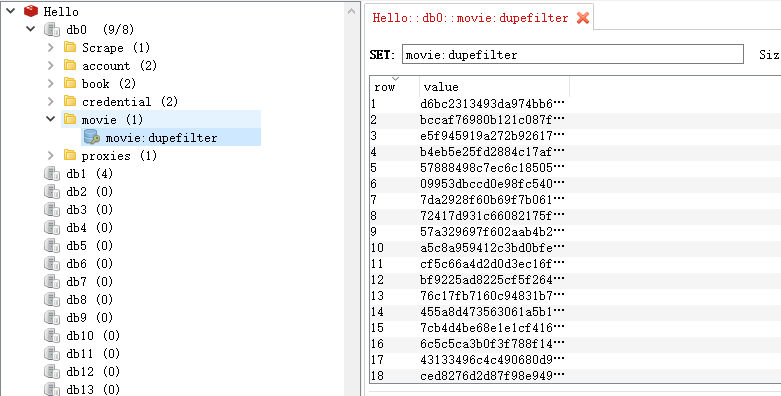
运行写好的Scrapy爬虫,可以在redis数据库中看到分布式

2.gerapy部署:
使用gerapy之前需要保证Scrapyd是可用的
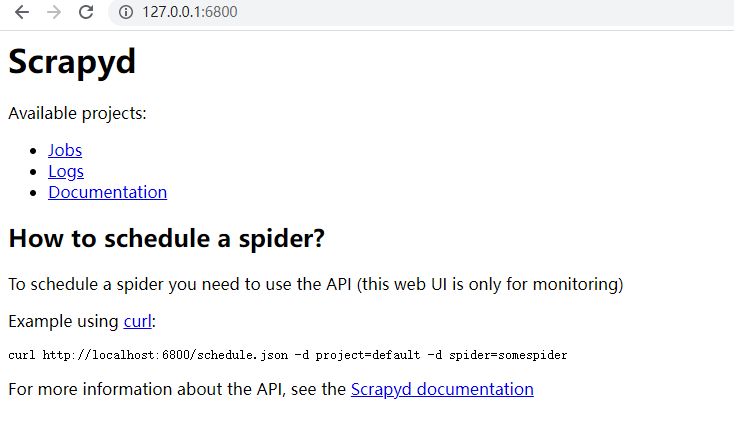
直接在终端 CMD中输入: scrapyd
检测是否启动scrapd:
在 浏览器中输入: http://127.0.0.1:6800/
显示如下,成功启动
Gerapy使用流程:
1.gerapy init 初始化,会在文件夹下创建一个gerapy文件夹
2.cd gerapy
3.gerapy migrate
4.gerapy runserver 默认是127.0.0.1:8000
5.gerapy createsuperuser 创建账号密码,默认情况下都是没有的
6.游览器输入127.0.0.1:8000 登录账号密码,进入主页
7.各种操作,比如添加主机,打包项目,定时任务等
在目标文件夹下输入 gerapy init

会生成一个gerapy文件夹,输入
cd gerapy进入文件夹再使用语句
gerapy migrate,生成gerapy数据库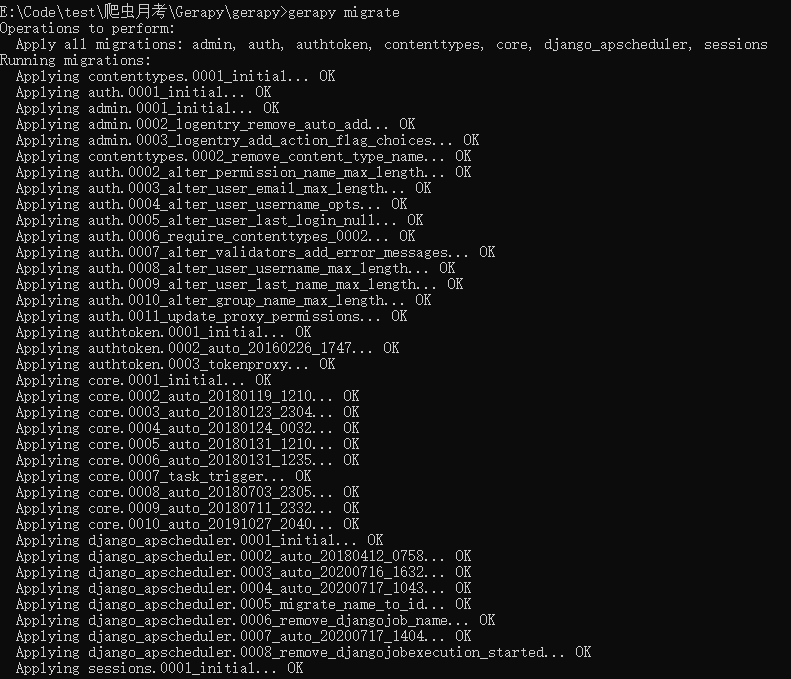
启动gerapy服务:
gerapy runserver
在浏览器中输入:http://127.0.0.1:8000/

Ctrl+c终止刚才运行的gerapy runserver
创建超级用户,用来管理gerapy
输入语句
gerapy createsuperuser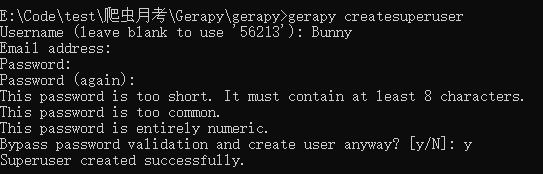
之后再次启动 gerapy:
gerapy runserver用刚才设定的超级用户 用户名和密码输入登录:
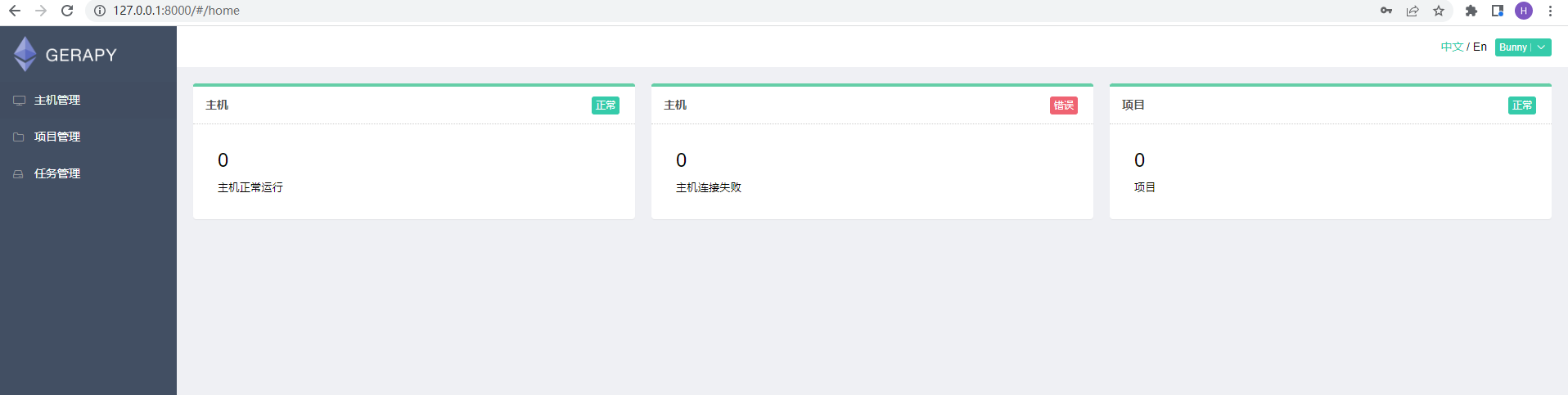
; 2.1更改Scrapy的gerapy连接文件:
在书写完毕的scrapy文件中,找到 scrapy.cfg文件
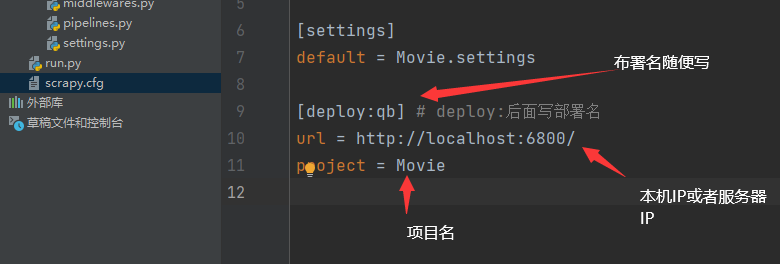
2.2登录后的项目部署:
点击主机管理:
创建:
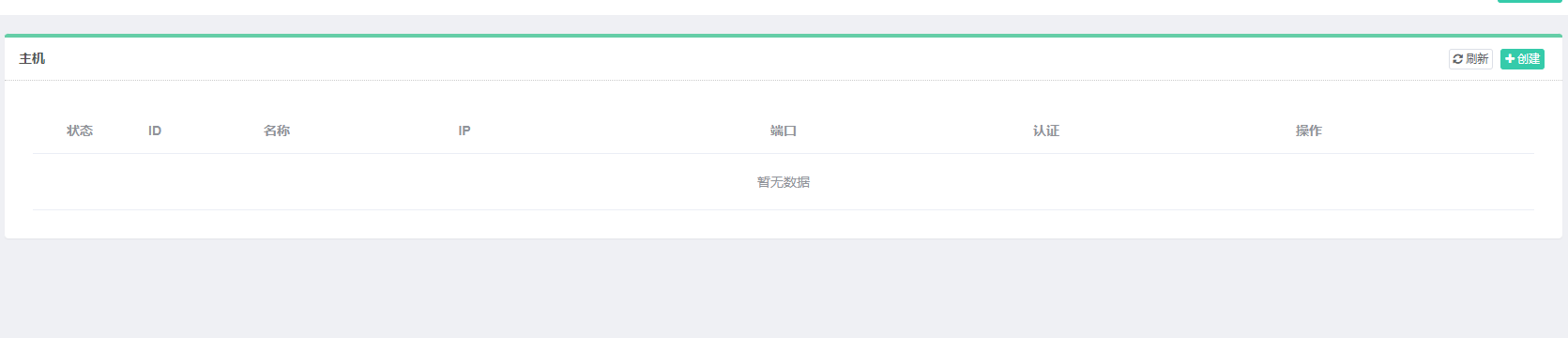
IP:本机IP,在CMD使用ipconfig查看
端口:scrapyd的端口号
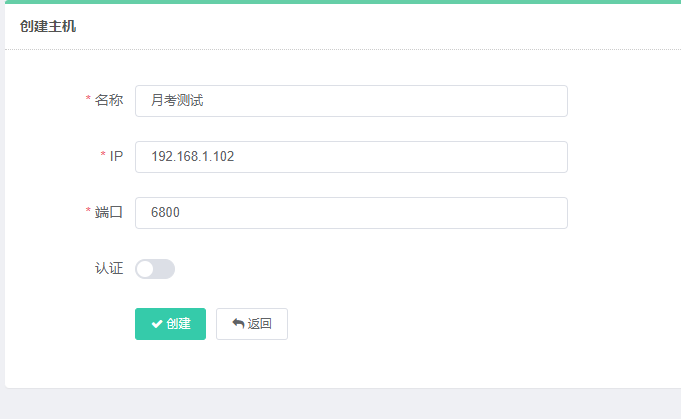
若出现无法连接的情况,则是Scrapyd配置中的问题需要更改:
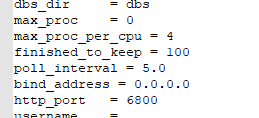
文件路径:E:\software\python\python3.8.6\Lib\site-packages\scrapyd
找到default_scrapyd.conf文件
把bind_address改为 0.0.0.0 这样所有IP都可以连接

之后在./gerpay/projects中将完善好的Scrapy爬虫文件夹fangru


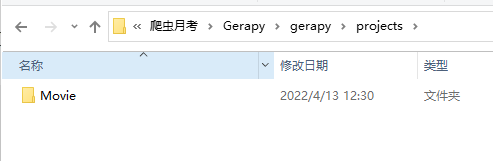
即可在gerapy网页项目管理中查看到,点击部署

文件需要进行打包才可以进行部署
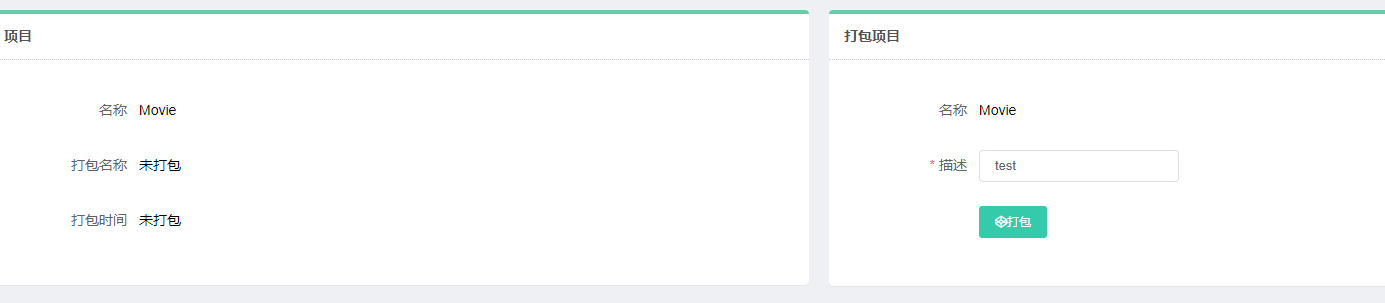
部署到刚才创建的主机中:
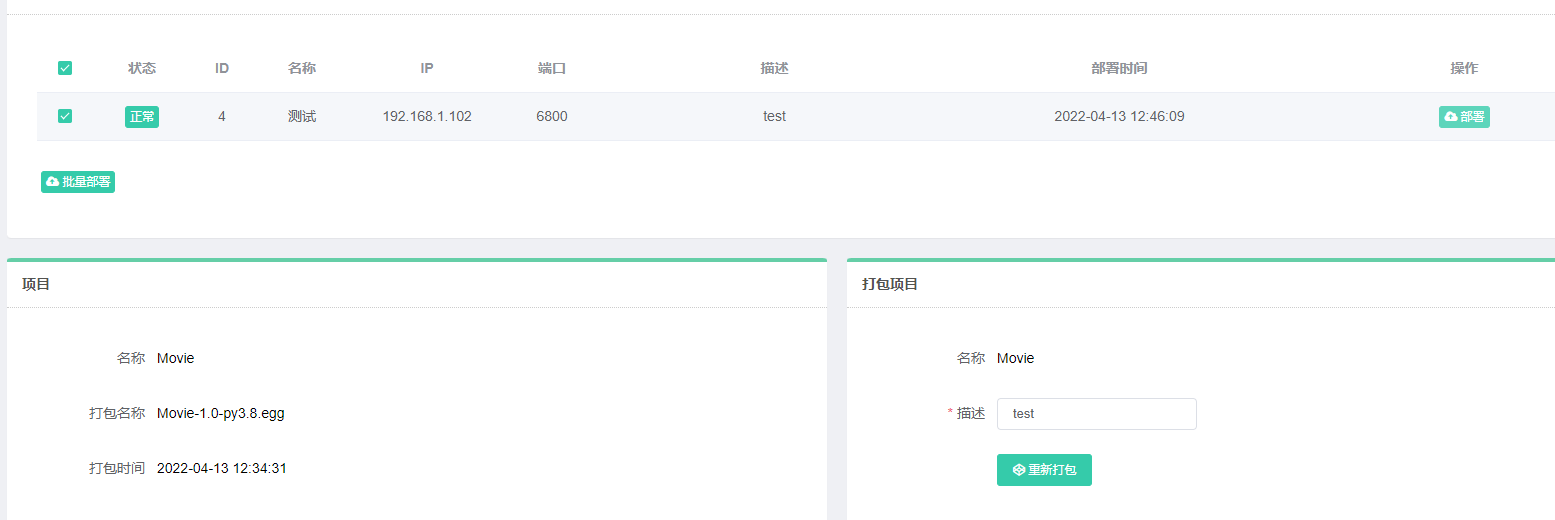
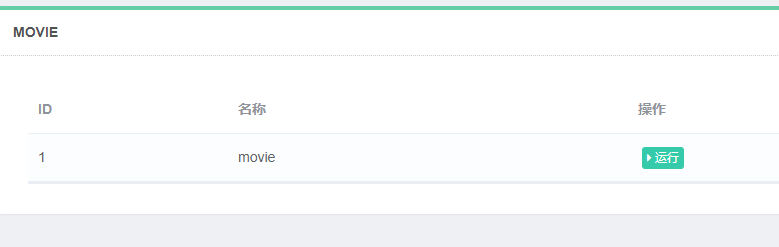
再看到主机项目中:使用调度

点击运行即可
注意:
启动一次gerapy之后,可能会有无法再爬取数据的情况,这是因为分布式的原因,代码为这行:
SCHEDULER_PERSIST = True
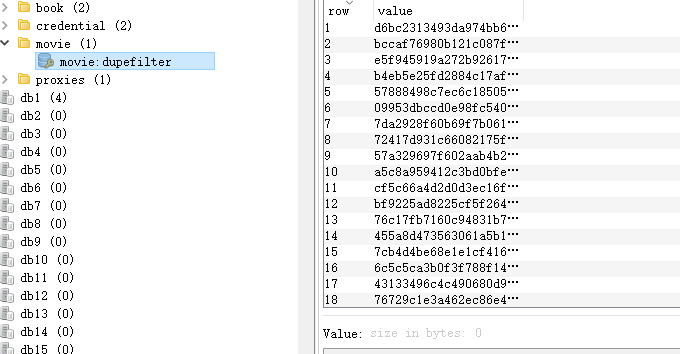
启动过一次之后,Redis数据库中的数据存满若再次执行会有指纹重复导致无法运行程序
若要多次运行爬虫,则有两种方法:
1.将 SCHEDULER_PERSIST = False设为False;
2.每次运行清空redis数据库中关于指纹的数据;
Original: https://blog.csdn.net/weixin_44826986/article/details/124144258
Author: BunnyDuudu
Title: Scrapy爬取4-项目分布式和gerapy部署
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788901/
转载文章受原作者版权保护。转载请注明原作者出处!