

提示:所有代码已经开源到最大同性交友网站,有兴趣的朋友可以试试:Git地址
未经作者允许不得私自转发
请注明原作者:https://blog.csdn.net/qq_52420866/article/details/121915057
文章目录
- 项目背景
- 一、安装Scrapy框架
- 二、Scrapy使用步骤
* - 2.1 创建爬虫项目
– - 2.2配置
setting.py文件 - 2.3配置
items.py文件 - 2.4配置
pafangzi.py(爬虫)文件
– - 三 数据存储的
pipelines.py文件
* - 3.1 安装连接数据库的库
- 3.2 书写
pipelines.py文件 - 3.3
setting.py中配置启用mongodb - 四 使用下载器中间件
* - 4.1 设置请求头
- 4.2 设置代理IP(如果你有的话^ _ ^)
- 五 改写为scrapy-Redis模拟分布式
* - 5.1 下载安装redis
- 5.2 打开redis
- 5.3 配置python中的设置
– - 六 使用scrapyd+scrapydweb可视化管理
* - 6.1 安装scrapyd
- 6.2 配置scrapyd
- 6.3 安装scrapydweb
- 6.4 运行scrapydweb(保证scrapyd服务器处于运行状态)
- 七 数据分析+大屏可视化
- 最后
项目背景
提示:项目背景:
毕业将近,大部分学生出去实习或工作面临找租房的压力,据研究发现:75%的大学生认为压力主要来源于社会就业。50%的大学生对于自己毕业后的发展前途感到迷茫,没有目标;41.7%的大学生表示目前没考虑太多;只有8.3%的人对自己的未来有明确的目标并且充满信心。很明显,就业已经是每个大学生一进校门就要考虑的事情了。中国是个人口大国,大学生毕业人数逐年上升,而社会需求的岗位数量却变化不大。根据对中国未来新增劳动力人口的测算,未来数年中国青年新增劳动力人口每年仍保持在1500~2200万之间的高位,供大于求,大学毕业生初次就业率逐年下降,直接导致就业压力大。
并且,学业压力是作为学生永远需要面对的主题,因就业压力而造成的新的学业压力也逐渐增大。大学生为了适应社会的需求,把自己变成全能型人才,这就需要学习很多功课,去拿到各种证书 来应对就业。可是人的精力是有限的,往往顾此失彼,结果是学什么都不专。大学教材更新的滞后也给学生带来更多的学习负担。学生一方面要学习学校规定的早已经不实用的课程,一方面要寻找将来能用上的课程去学习,还有各种硬性的考级科目,使学生应对无暇。因为就业压力还使更多的大学生选择了继续读硕士博士课程,为了考研,很多学生是在毕业前一两年就开始准备了,各种考研培训班到处都是,大学生既要付出时间还要付出金钱。
为了使大学生更好的在外面租到房子,避坑,并且对新房子和二手房有更加好的了解,我们从网上爬取下一定数据,并且做可视化分析,解决毕业大学生的租房子问题。
一、安装Scrapy框架
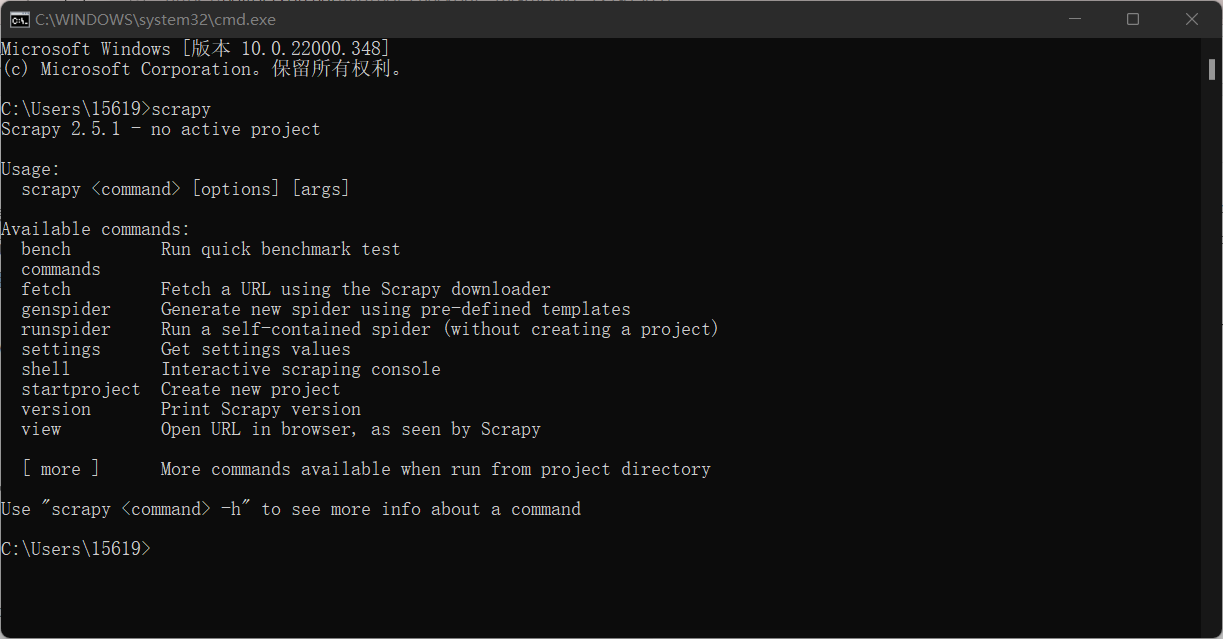
cmd中输入: pip install scrapy
如果出现下面的情况,说明已经成功
PS:windows安装scrapy有非常多的坑,有问题自己百度,可以参考:scrapy安装

; 二、Scrapy使用步骤
如果你要系统学习:scrapy官网
2.1 创建爬虫项目
进入cmd,找到想要建立工程的地方:
输入命令: scrapy startproject myspider
输入: cd myspider
建立爬虫: scrapy genspider [爬虫名] [域名]
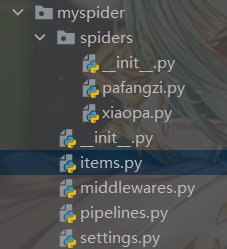
2.1.1 建立好后的爬虫目录
; 2.2配置 setting.py 文件
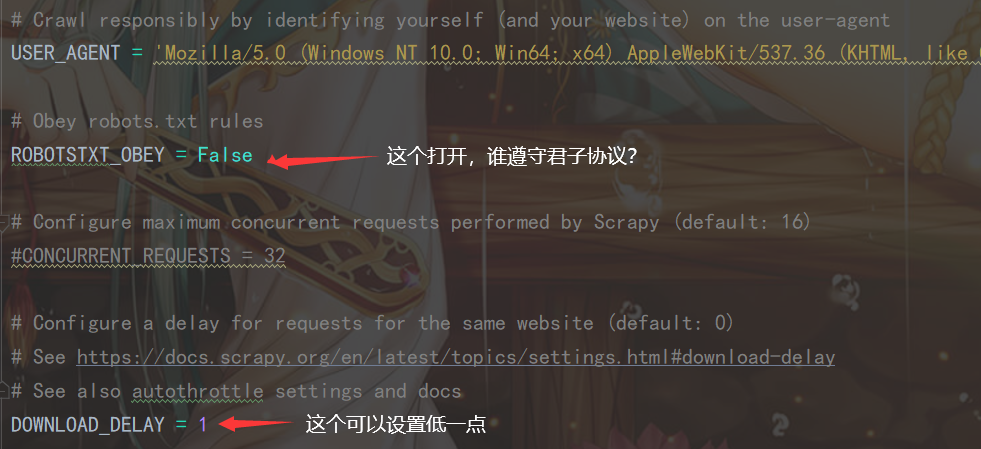
然后把下面代码打开:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en'
}
2.3配置 items.py 文件
这个文件中是要创建的爬取实列化对象
import scrapy
class New_houseItem(scrapy.Item):
province=scrapy.Field()
city=scrapy.Field()
name=scrapy.Field()
price=scrapy.Field()
rooms=scrapy.Field()
area=scrapy.Field()
district=scrapy.Field()
sale=scrapy.Field()
new_url=scrapy.Field()
class Old_houseItem(scrapy.Item):
province = scrapy.Field()
city = scrapy.Field()
name = scrapy.Field()
address = scrapy.Field()
price = scrapy.Field()
unit = scrapy.Field()
old_url = scrapy.Field()
infos = scrapy.Field()
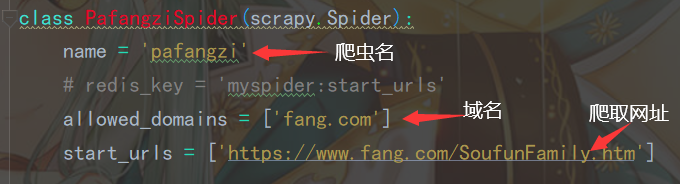
2.4配置 pafangzi.py(爬虫) 文件
2.4.1配置(爬虫)
; 2.4.2 网站抓包
按F12打开调试工具
建议使用Xpath Helper,简单好用:
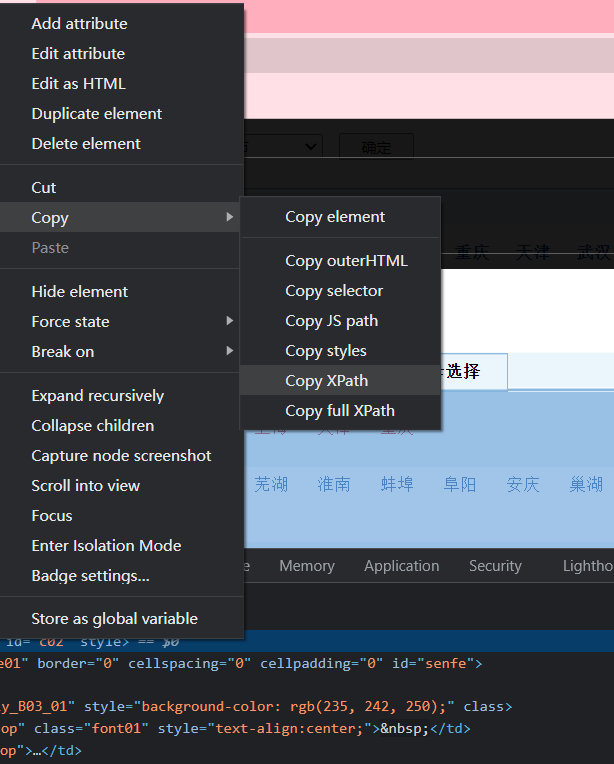
获取你要的内容:

2.4.3 编写函数
进一步解析(上代码)安排!
def parse(self, response):
trs = response.xpath("//div[@class = 'outCont']//tr")
province = None
for tr in trs:
tds = tr.xpath(".//td[not(@class)]")
province_text = tds[0]
city_info = tds[1]
province_text = province_text.xpath(".//text()").get()
province_text = re.sub(r"\s", "", province_text)
if province_text:
province = province_text
if province == "其它":
continue
city_links = city_info.xpath(".//a")
for city_link in city_links:
city = city_link.xpath(".//text()").get()
city_url = city_link.xpath(".//@href").get()
url_split = city_url.split("fang")
url_former = url_split[0]
url_backer = url_split[1]
newhouse_url = url_former + "newhouse.fang.com/house/s/"
old_url = url_former + "esf.fang.com/"
yield scrapy.Request(url=newhouse_url, callback=self.parse_newhouse, meta={"info": (province, city)})
yield scrapy.Request(url=old_url, callback=self.parse_oldhouse, meta={"info": (province, city)})
2.4.4 回调函数二次解析
def parse_newhouse(self, response):
province, city = response.meta.get("info")
lis = response.xpath("//div[contains(@class, 'nl_con')]/ul/li[not(@style)]")
for li in lis:
name = li.xpath(".//div[@class='nlcd_name']/a/text()").get().strip()
rooms = li.xpath(".//div[contains(@class, 'house_type')]/a//text()").getall()
area = li.xpath(".//div[contains(@class, 'house_type')]/text()").getall()
area = "".join(area).strip()
area = re.sub(r"/|-|/s| |\n", "", area)
district = li.xpath(".//div[@class = 'address']/a//text()").getall()
district = "".join(district)
district = re.search(r".*\[(.+)\].*", district).group(1)
sale = li.xpath(".//div[contains(@class, 'fangyuan')]/span/text()").get().strip()
price = li.xpath(".//div[@class = 'nhouse_price']//text()").getall()
price = "".join(price).strip()
new_url = li.xpath(".//div[@class = 'nlcd_name']/a/@href").get()
item = New_houseItem(province=province, city=city, name=name, rooms=rooms, area=area,
district=district, sale=sale, price=price, new_url=new_url)
yield item
next_url = response.xpath("//div[@class = 'page']//a[@class = 'next']/@href").get()
if next_url:
yield scrapy.Request(url=response.urljoin(next_url), callback=self.parse_newhouse,
meta={"info": (province, city)})
def parse_oldhouse(self, response):
province, city = response.meta.get("info")
dls = response.xpath("//div[contains(@class, 'shop_list')]/dl[@dataflag = 'bg']")
for dl in dls:
item = Old_houseItem(province=province, city=city)
name = dl.xpath(".//p[@class = 'add_shop']/a/@title").get()
item["name"] = name
infos = dl.xpath(".//p[@class = 'tel_shop']/text()").get().strip()
infos = "".join(infos).strip()
infos = re.sub(r"'|\|\r|\n|/s| ", "", infos)
item['infos'] = infos
address = dl.xpath(".//p[@class = 'add_shop']/span/text()").get()
item['address'] = address
price = dl.xpath(".//dd[@class = 'price_right']/span[1]//text()").getall()
price = "".join(price).strip()
item['price'] = price
unit = dl.xpath(".//dd[@class = 'price_right']/span[2]/text()").get()
item['unit'] = unit
old_url = dl.xpath(".//h4[@class = 'clearfix']/a/@href").getall()
old_url = "".join(old_url)
old_url = response.urljoin(old_url)
item['old_url'] = old_url
yield item
next_url = response.xpath("//div[@class = 'page_al']/p[last()-1]/a/@href").get()
if next_url:
yield scrapy.Request(url=response.urljoin(next_url), callback=self.parse_oldhouse,
meta={"info": (province, city)})
整体代码块:
import scrapy
import re
from ..items import New_houseItem, Old_houseItem
class PafangziSpider(scrapy.Spider):
name = 'pafangzi'
allowed_domains = ['fang.com']
start_urls = ['https://www.fang.com/SoufunFamily.htm']
def parse(self, response):
trs = response.xpath("//div[@class = 'outCont']//tr")
province = None
for tr in trs:
tds = tr.xpath(".//td[not(@class)]")
province_text = tds[0]
city_info = tds[1]
province_text = province_text.xpath(".//text()").get()
province_text = re.sub(r"\s", "", province_text)
if province_text:
province = province_text
if province == "其它":
continue
city_links = city_info.xpath(".//a")
for city_link in city_links:
city = city_link.xpath(".//text()").get()
city_url = city_link.xpath(".//@href").get()
url_split = city_url.split("fang")
url_former = url_split[0]
url_backer = url_split[1]
newhouse_url = url_former + "newhouse.fang.com/house/s/"
old_url = url_former + "esf.fang.com/"
yield scrapy.Request(url=newhouse_url, callback=self.parse_newhouse, meta={"info": (province, city)})
yield scrapy.Request(url=old_url, callback=self.parse_oldhouse, meta={"info": (province, city)})
def parse_newhouse(self, response):
province, city = response.meta.get("info")
lis = response.xpath("//div[contains(@class, 'nl_con')]/ul/li[not(@style)]")
for li in lis:
name = li.xpath(".//div[@class='nlcd_name']/a/text()").get().strip()
rooms = li.xpath(".//div[contains(@class, 'house_type')]/a//text()").getall()
area = li.xpath(".//div[contains(@class, 'house_type')]/text()").getall()
area = "".join(area).strip()
area = re.sub(r"/|-|/s| |\n", "", area)
district = li.xpath(".//div[@class = 'address']/a//text()").getall()
district = "".join(district)
district = re.search(r".*\[(.+)\].*", district).group(1)
sale = li.xpath(".//div[contains(@class, 'fangyuan')]/span/text()").get().strip()
price = li.xpath(".//div[@class = 'nhouse_price']//text()").getall()
price = "".join(price).strip()
new_url = li.xpath(".//div[@class = 'nlcd_name']/a/@href").get()
item = New_houseItem(province=province, city=city, name=name, rooms=rooms, area=area,
district=district, sale=sale, price=price, new_url=new_url)
yield item
next_url = response.xpath("//div[@class = 'page']//a[@class = 'next']/@href").get()
if next_url:
yield scrapy.Request(url=response.urljoin(next_url), callback=self.parse_newhouse,
meta={"info": (province, city)})
def parse_oldhouse(self, response):
province, city = response.meta.get("info")
dls = response.xpath("//div[contains(@class, 'shop_list')]/dl[@dataflag = 'bg']")
for dl in dls:
item = Old_houseItem(province=province, city=city)
name = dl.xpath(".//p[@class = 'add_shop']/a/@title").get()
item["name"] = name
infos = dl.xpath(".//p[@class = 'tel_shop']/text()").get().strip()
infos = "".join(infos).strip()
infos = re.sub(r"'|\|\r|\n|/s| ", "", infos)
item['infos'] = infos
address = dl.xpath(".//p[@class = 'add_shop']/span/text()").get()
item['address'] = address
price = dl.xpath(".//dd[@class = 'price_right']/span[1]//text()").getall()
price = "".join(price).strip()
item['price'] = price
unit = dl.xpath(".//dd[@class = 'price_right']/span[2]/text()").get()
item['unit'] = unit
old_url = dl.xpath(".//h4[@class = 'clearfix']/a/@href").getall()
old_url = "".join(old_url)
old_url = response.urljoin(old_url)
item['old_url'] = old_url
yield item
next_url = response.xpath("//div[@class = 'page_al']/p[last()-1]/a/@href").get()
if next_url:
yield scrapy.Request(url=response.urljoin(next_url), callback=self.parse_oldhouse,
meta={"info": (province, city)})
三 数据存储的 pipelines.py 文件
我们习惯性存到mongodb数据库,想要详细了解mongodb,请你参考:windosw操作mongodb
3.1 安装连接数据库的库
打开cmd
输入: pip install pymongo
3.2 书写 pipelines.py 文件
from itemadapter import ItemAdapter
import pymongo
from .items import New_houseItem, Old_houseItem
class MongodbPipline(object):
def __init__(self):
client = pymongo.MongoClient('127.0.0.1', 27017)
db = client['fangzi']
self.post_newhouse = db['newhouse3']
self.post_oldhouse = db['oldhouse3']
def process_item(self, item, spider):
if isinstance(item, New_houseItem):
postItem = dict(item)
print(postItem)
self.post_newhouse.insert_one(postItem)
if isinstance(item, Old_houseItem):
postItem = dict(item)
print(postItem)
self.post_oldhouse.insert_one(postItem)
3.3 setting.py 中配置启用mongodb
添加:
# 数据库配置信息 MONGODB_HOST = '127.0.0.1' MONGODB_PORT = 27017 MONGODB_DBNAME = 'fangzi' MONGODB_DOCNAME1 = 'newhouse3' MONGODB_DOCNAME2 = 'oldhouse3'
打开:
ITEM_PIPELINES = {
'myspider.pipelines.MongodbPipline': 300,
}
到此,第一步操作,我们的爬虫就完成了!
到爬虫文件中,转到终端
输入: scrapy crawl [爬虫名]
等待运行结束,你的数据库中就有
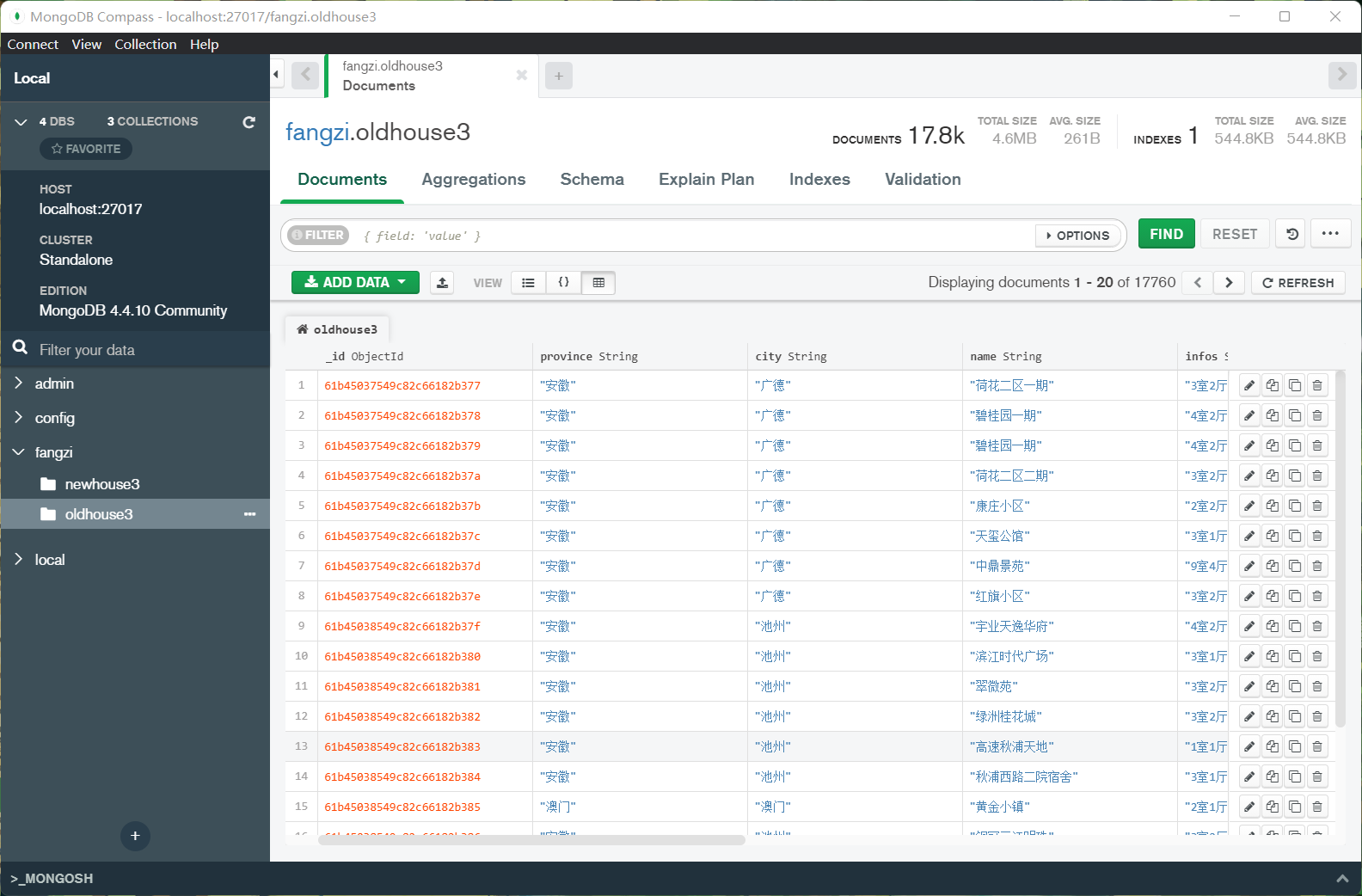
四 使用下载器中间件
打开 middlewares.py文件
4.1 设置请求头
from scrapy import signals
import random
from itemadapter import is_item, ItemAdapter
class UserAgentDownloadMiddleware(object):
User_Agents = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999"
]
def process_request(self, request, spider):
user_agent = random.choice(self.User_Agents)
request.headers['User-Agent'] = user_agent
4.2 设置代理IP(如果你有的话^ _ ^)
import base64
class DuXiangIPProxyDownloadMiddleware(object):
def process_request(self, request, spider):
proxy = "代理ip地址 : 端口号"
user_password = "账号 : 密码"
request.meta["proxy"] = proxy
b64_user_password = base64.b64encode(user_password.encode('utf-8'))
request.headers["Proxy-Authorization"] = "Basic " + b64_user_password.decode('utf-8')
不要忘了打开setting
DOWNLOADER_MIDDLEWARES = {
'myspider.middlewares.UserAgentDownloadMiddleware':543,
}
有没有感觉一切都非常简单!
为了提高爬虫性能,现在我们玩一点好玩的?
将爬虫改写为分布式爬虫
五 改写为scrapy-Redis模拟分布式
5.1 下载安装redis
地址:Redis
详细教程:Redis手册
5.2 打开redis
- 打开
cmd命令行 - 进入Redis文件目录
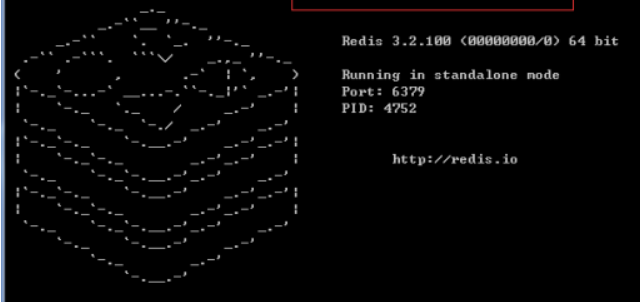
- 输入:
redis-server.exe redis.windows.conf
出现这个说明成功
- 新开一个cmd,输入:redis-cli
; 5.3 配置python中的设置
5.3.1 安装scrapy-redis
输入 pip install scrapy-redis
5.3.2 配置
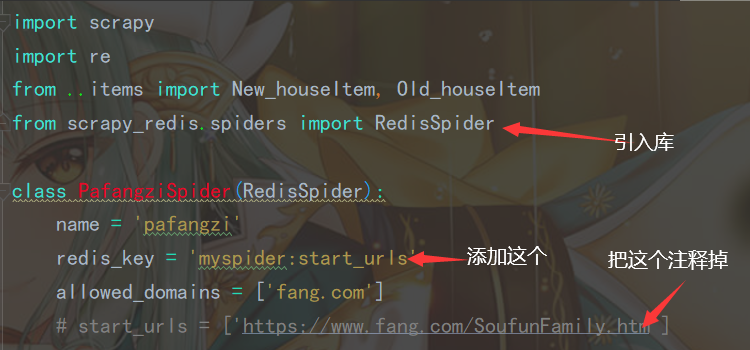
然后在
setting.py中设置(因为我们存数据库就不存redis服务器了)
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER_PERSIST = True
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
5.3.3 启动分布式
最最最Z13时刻
多开几个端口,爬虫进入监听,然后redis-cli窗口输入: lpush myspider:start_urls [爬取网址]
回车开始爬取
; 六 使用scrapyd+scrapydweb可视化管理
是不是感觉命令行操作有点恼火?我也觉得
你想要深入学习?scrapyd手册
6.1 安装scrapyd
输入: pip install scrapyd
输入: pip install scrapyd-client
命令行中输入
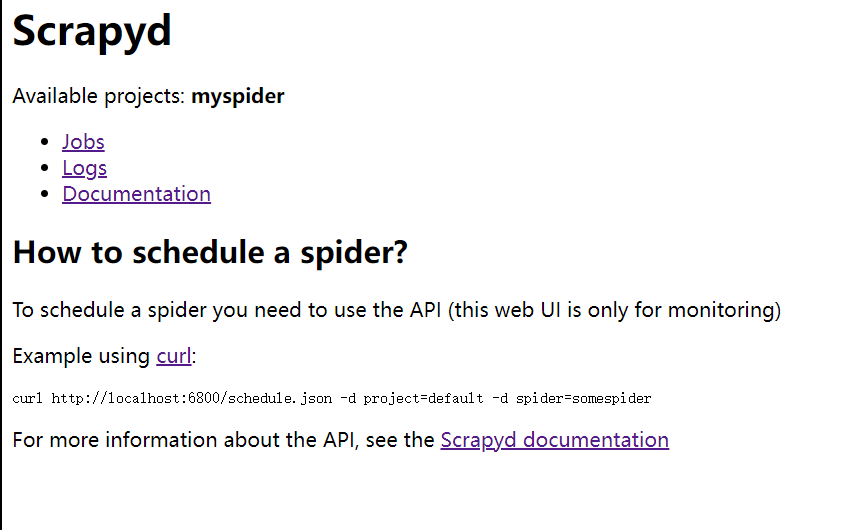
scrapyd
在浏览器中输入:http://localhost:6800/,如果出现下面界面则表示启动成功(不要关闭cmd,后面步骤还需要)
; 6.2 配置scrapyd
打开scrapy项目,有个scrapy.cfg文件,按如下进行配置
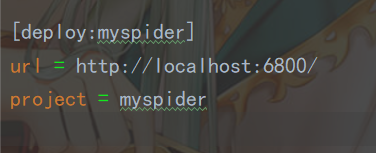
进入项目文件夹输入:
scrapyd-deploy -l
已经扫描到项目,然后编译 scrapyd-deploy myspider -p myspider

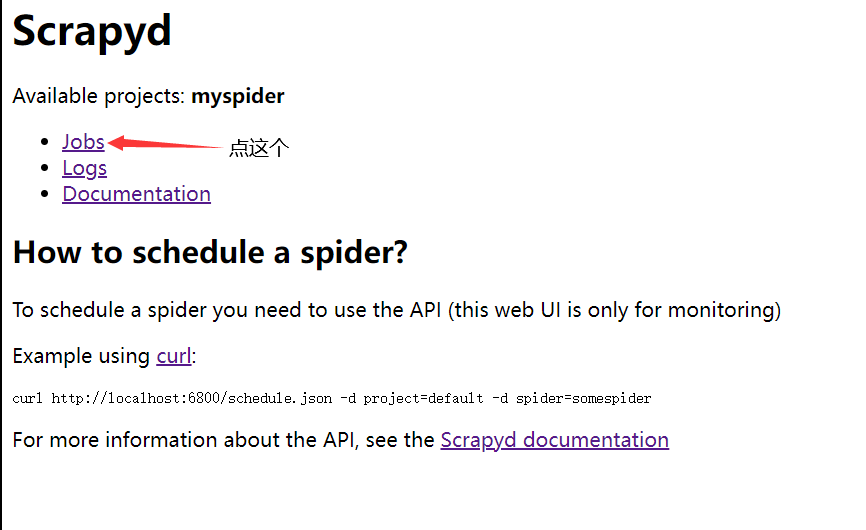
6.3 安装scrapydweb
输入 pip install scrapydweb
会出现一个配置文件

; 6.4 运行scrapydweb(保证scrapyd服务器处于运行状态)
终端: scrapydweb
出现可视化界面
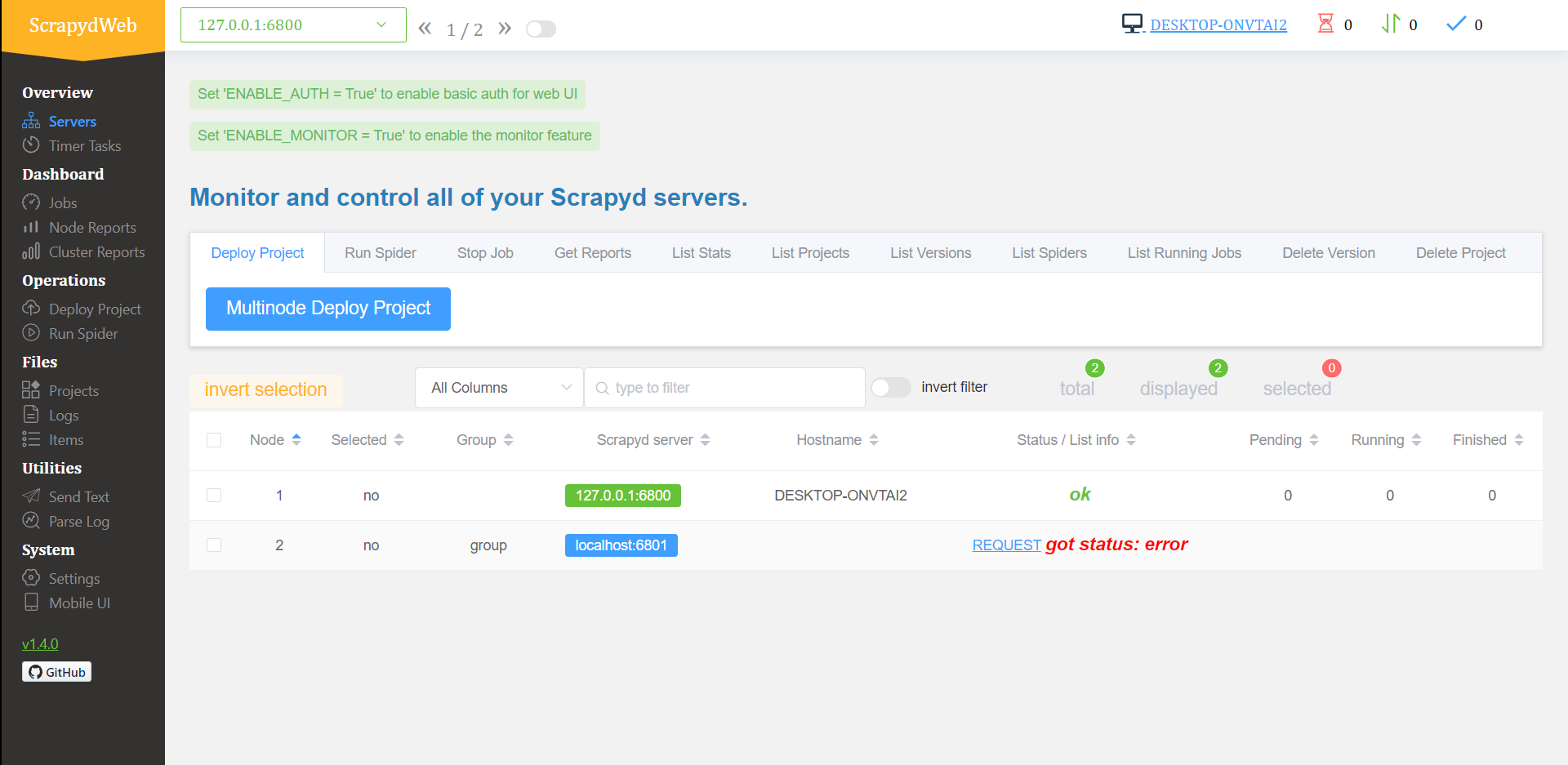
之后就可以愉快的玩耍了!

七 数据分析+大屏可视化
因为没有JavaScript大佬教我,所以选择BI工具,安排!
输入: pip install pandas
import pymongo
import pandas as pd
client = pymongo.MongoClient('127.0.0.1', 27017)
db = client['fangzi']
old_table = db['oldhouse3']
new_table=db['newhouse3']
data = pd.DataFrame(list(old_table.find()))
筛选自己要的数据,分组存表,导入BI工具,
剩下的就交给你们发挥洛^ _ ^
奉上大图
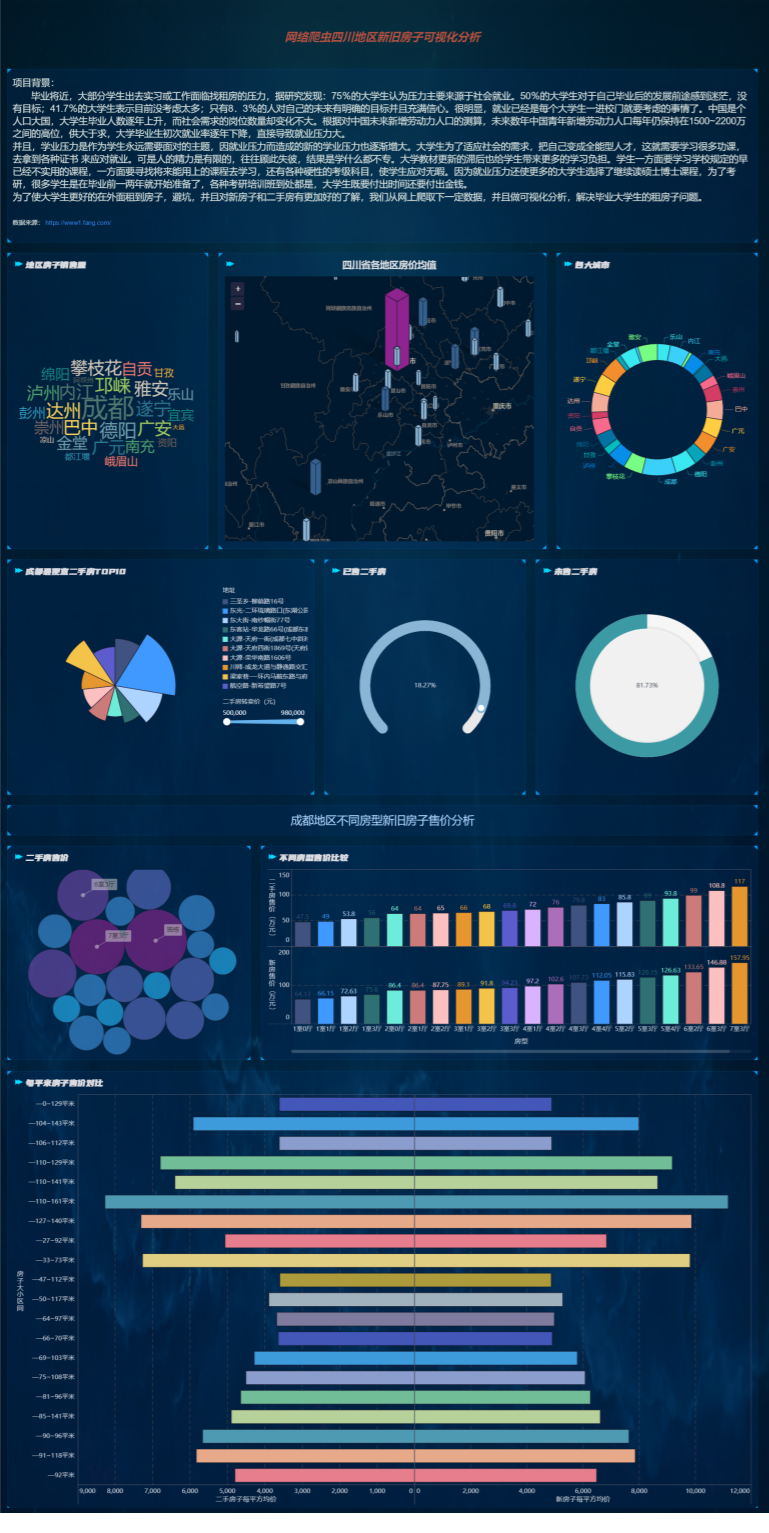
最后
记得给一个一键三连哦!
未经作者允许不得私自转发
请注明原作者:https://blog.csdn.net/qq_52420866/article/details/121915057
Original: https://blog.csdn.net/qq_52420866/article/details/121915057
Author: _不咬闰土的猹丶
Title: 基于Scrapy+redis+mongodb+scrapyd+scrapydweb+Pandas+BI的可视化操作分布式网络爬虫数据可视化分析
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788824/
转载文章受原作者版权保护。转载请注明原作者出处!