

期末大作业做一个全程数据展示,数据来源就是要用爬虫,想来想去还是用scrapy框架好一点。
上课的时候老师说了句,拉勾网有难度,哎!!这我就不服了,嘎嘎嘎嘎嘎,我就爬它。
首先:
去拉勾网那里按F12,然后点击网络(注意蓝色下划线),只看Fetch/XHR,
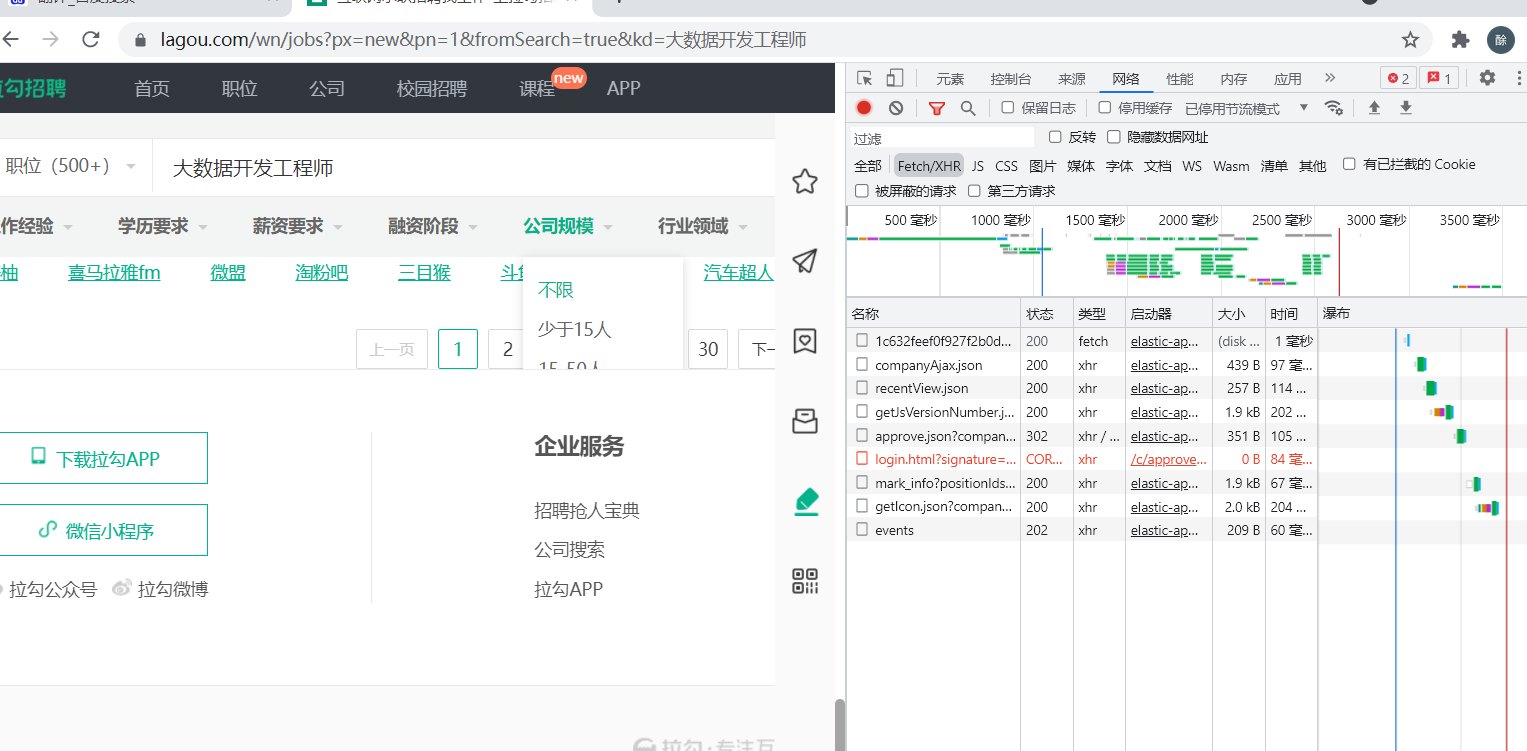

第二:重点:点2页,3页多试试看页面出现了什么不同之处:
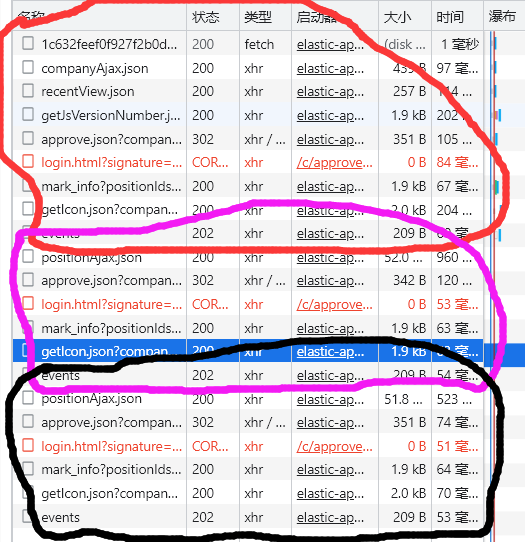
注:红色圈圈的是刚刚进页面的数据,蓝色圈圈的是点击第2页时候加载出来的数据,黑色圈圈则是点击第3页时候的数据。 然后要选大小最大的文件!!!!
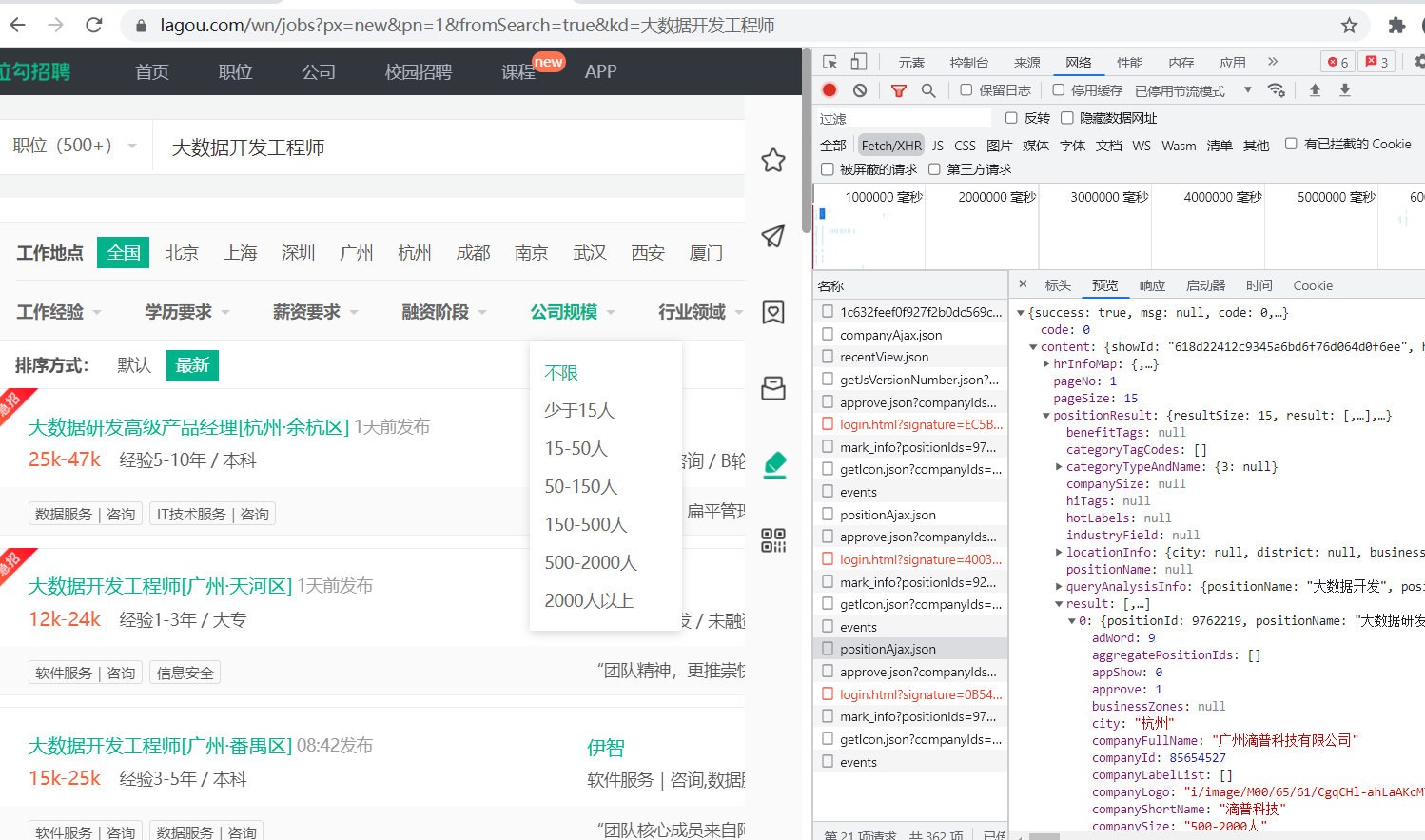
就是那些posittionAjax.json(),点击它们,点击预览,这时候你会出现如下图:

然后在点content,positionResult,result(依次进行),我们要的数据在0到14之内
吐槽一下:如果你好奇我为什么会找到这里,其实我就是看了很多次网站的结构,然后才发现数据在这里的,感觉自己对Ajax的知识了解好少哎。。。。
分析完数据位置之后,就是代码环节啦(开心-。-):
在项目位置的控制台敲创建命令:
scrapy startproject jobs_crwal_lagou
然后cd jobs_crwal_lagou(两次)
cd spider
然后
scrapy genspider lagou_spider www.baidu.com
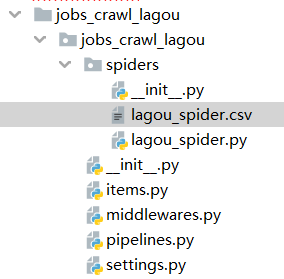
出现如下文件结构(csv是我已经运行好的结构):
写代码必须明确不用页面之间的网址规律:
但是再拉勾网网址是https://www.lagou.com/jobs/v2/positionAjax.json

所以咱们url这么写:
start_urls = 'https://www.lagou.com/jobs/v2/positionAjax.json'
在Ajax的网站中需要使用post请求,所以我们需要重写start_requests()方法:
def start_requests(self,):
for pn in range(1,301): #这里是爬取300页
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'referer': 'https://www.lagou.com/wn/jobs?px=new&pn=2&fromSearch=true&kd=%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88',
'cookie': 'user_trace_token=20211108091120-8b0afd09-e510-42ce-a04c-f23917df57a4; _ga=GA1.2.418688220.1636333882; LGUID=20211108091121-eaa74fc9-4fdf-4643-a0e2-115418dc5c7f; RECOMMEND_TIP=true; index_location_city=%E5%85%A8%E5%9B%BD; __lg_stoken__=33bc62cc28b671aedf0e11535f4cbff311ae530554395f66a58a3d64ca49c4c49bc0d3d26568c5d7a60d1e2de619166f2e7e321b42a4bc3a5207f2b9cfc5f3e1deb6421fcb8e; _gid=GA1.2.356362994.1636624612; SEARCH_ID=b2b4c1c76447482aac70fee163179cab; JSESSIONID=ABAAAECABIEACCA678016FE3945EC4E6C42B8A2CFC2D753; WEBTJ-ID=20211112230816-17d14b1310445b-0bc56c987c842e-57b1a33-1327104-17d14b13105545; X_HTTP_TOKEN=ed095ffe505ce6c5696927636173744ecc1824c2d7; _gat=1; privacyPolicyPopup=false; PRE_UTM=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; sensorsdata2015session=%7B%7D; LGSID=20211112230816-1fb915d8-980f-4df0-807f-4db720dfe0cf; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Doy4wudHBJeFCLVmRef7GwCu%5FM5uL2pbjTdWtXzorEpy%26wd%3D%26eqid%3D87562fb90002ea7e00000006618e835d; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1636624612,1636625176,1636642907,1636729697; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1636729697; TG-TRACK-CODE=index_search; LGRID=20211112230821-9c4a26bd-2a4c-453f-be6a-f2e1bb964c86; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2217cfd198b39e27-07e0cb7bb065aa-57b1a33-1327104-17cfd198b3aa6d%22%2C%22%24device_id%22%3A%2217cfd198b39e27-07e0cb7bb065aa-57b1a33-1327104-17cfd198b3aa6d%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2295.0.4638.69%22%7D%7D'
}
data = {
'first': 'true',
'needAddtionalResult': 'false',
'city': '全国',
'px': 'new',
'pn': str(pn),
'fromSearch': 'true',
'kd': '大数据开发工程师',
}
yield scrapy.FormRequest(url=self.start_urls,formdata=data,headers=headers, callback=self.parse)
请大家注意!!!headers中的User-Agent、referer、cookie不要复制本菜鸟的,请自己从下图拿。
表单数据也要自己拿到!!!pn代表的是页数。

接下来就是解析数据啦:
def parse(self, response):
# res = response.post(url=self.start_urls, headers=headers, data=data)
text = response.json()["content"]["positionResult"]["result"]
print(text)
for i in text:
item = JobsCrawlLagouItem()
# 公司全名
item["companyFullName"] = i["companyFullName"]
# 公司规模
item["companySize"] = i["companySize"]
# 招聘领域
item["industryField"] = i["industryField"]
# 融资状况
item["financeStage"] = i["financeStage"]
# 职位名称
item["positionName"] = i["positionName"]
# 工作经验
item["workYear"] = i["workYear"]
# 工作薪酬
item["salary"] = i["salary"]
# 学历要求
item["education"] = i["education"]
yield item
以上代码都是lagou_spider.py的
接下来是setting的:
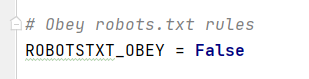
将ROBOTSTXT_OBEY改为False
ROBOTSTXT_OBEY = False
启用管道:
ITEM_PIPELINES = {
'jobs_crawl_lagou.pipelines.JobsCrawlLagouPipeline': 300,
'jobs_crawl_lagou.pipelines.savecsvPipeline': 300,
}
管道pipelines.py(我保存为csv格式):
import csv
class JobsCrawlLagouPipeline:
def process_item(self, item, spider):
return item
class savecsvPipeline(object):
def __init__(self):
self.file = open('lagou_spider.csv','w',newline='')
self.csvwriter = csv.writer(self.file)
self.csvwriter.writerow(['公司全名','公司规模','招聘领域','融资状况','职位名称','工作经验','工作薪酬','学历要求'])
def process_item(self,item,spider):
self.csvwriter.writerow([item["companyFullName"],item["companySize"],item["industryField"],item["financeStage"],item["positionName"],item["workYear"],item["salary"],item["education"]])
return item
def close_spider(self,spider):
self.file.close()
items.py:
companyFullName = scrapy.Field()
companySize = scrapy.Field()
industryField = scrapy.Field()
financeStage = scrapy.Field()
positionName = scrapy.Field()
workYear = scrapy.Field()
salary = scrapy.Field()
education= scrapy.Field()
以下是所有代码:
1.lagou_spider.py:
import scrapy
from ..items import JobsCrawlLagouItem
class LagouSpiderSpider(scrapy.Spider):
name = 'lagou_spider'
# allowed_domains = ['www.baidu.com']
start_urls = 'https://www.lagou.com/jobs/v2/positionAjax.json'
def start_requests(self,):
for pn in range(1,301): #这里是爬取300页
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'referer': 'https://www.lagou.com/wn/jobs?px=new&pn=2&fromSearch=true&kd=%E5%A4%A7%E6%95%B0%E6%8D%AE%E5%BC%80%E5%8F%91%E5%B7%A5%E7%A8%8B%E5%B8%88',
'cookie': 'user_trace_token=20211108091120-8b0afd09-e510-42ce-a04c-f23917df57a4; _ga=GA1.2.418688220.1636333882; LGUID=20211108091121-eaa74fc9-4fdf-4643-a0e2-115418dc5c7f; RECOMMEND_TIP=true; index_location_city=%E5%85%A8%E5%9B%BD; __lg_stoken__=33bc62cc28b671aedf0e11535f4cbff311ae530554395f66a58a3d64ca49c4c49bc0d3d26568c5d7a60d1e2de619166f2e7e321b42a4bc3a5207f2b9cfc5f3e1deb6421fcb8e; _gid=GA1.2.356362994.1636624612; SEARCH_ID=b2b4c1c76447482aac70fee163179cab; JSESSIONID=ABAAAECABIEACCA678016FE3945EC4E6C42B8A2CFC2D753; WEBTJ-ID=20211112230816-17d14b1310445b-0bc56c987c842e-57b1a33-1327104-17d14b13105545; X_HTTP_TOKEN=ed095ffe505ce6c5696927636173744ecc1824c2d7; _gat=1; privacyPolicyPopup=false; PRE_UTM=; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2F; sensorsdata2015session=%7B%7D; LGSID=20211112230816-1fb915d8-980f-4df0-807f-4db720dfe0cf; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3Doy4wudHBJeFCLVmRef7GwCu%5FM5uL2pbjTdWtXzorEpy%26wd%3D%26eqid%3D87562fb90002ea7e00000006618e835d; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1636624612,1636625176,1636642907,1636729697; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1636729697; TG-TRACK-CODE=index_search; LGRID=20211112230821-9c4a26bd-2a4c-453f-be6a-f2e1bb964c86; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2217cfd198b39e27-07e0cb7bb065aa-57b1a33-1327104-17cfd198b3aa6d%22%2C%22%24device_id%22%3A%2217cfd198b39e27-07e0cb7bb065aa-57b1a33-1327104-17cfd198b3aa6d%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E8%87%AA%E7%84%B6%E6%90%9C%E7%B4%A2%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.baidu.com%2Flink%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24os%22%3A%22Windows%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2295.0.4638.69%22%7D%7D'
}
data = {
'first': 'true',
'needAddtionalResult': 'false',
'city': '全国',
'px': 'new',
'pn': str(pn),
'fromSearch': 'true',
'kd': '大数据开发工程师',
}
yield scrapy.FormRequest(url=self.start_urls,formdata=data,headers=headers, callback=self.parse)
def parse(self, response):
# res = response.post(url=self.start_urls, headers=headers, data=data)
text = response.json()["content"]["positionResult"]["result"]
print(text)
for i in text:
item = JobsCrawlLagouItem()
# 公司全名
item["companyFullName"] = i["companyFullName"]
# 公司规模
item["companySize"] = i["companySize"]
# 招聘领域
item["industryField"] = i["industryField"]
# 融资状况
item["financeStage"] = i["financeStage"]
# 职位名称
item["positionName"] = i["positionName"]
# 工作经验
item["workYear"] = i["workYear"]
# 工作薪酬
item["salary"] = i["salary"]
# 学历要求
item["education"] = i["education"]
yield item
2.pipelines.py:
import csv
class JobsCrawlLagouPipeline:
def process_item(self, item, spider):
return item
class savecsvPipeline(object):
def __init__(self):
self.file = open('lagou_spider.csv','w',newline='')
self.csvwriter = csv.writer(self.file)
self.csvwriter.writerow(['公司全名','公司规模','招聘领域','融资状况','职位名称','工作经验','工作薪酬','学历要求'])
def process_item(self,item,spider):
self.csvwriter.writerow([item["companyFullName"],item["companySize"],item["industryField"],item["financeStage"],item["positionName"],item["workYear"],item["salary"],item["education"]])
return item
def close_spider(self,spider):
self.file.close()
3.items.py:
name = scrapy.Field()
companyFullName = scrapy.Field()
companySize = scrapy.Field()
industryField = scrapy.Field()
financeStage = scrapy.Field()
positionName = scrapy.Field()
workYear = scrapy.Field()
salary = scrapy.Field()
education= scrapy.Field()
4.settings.py

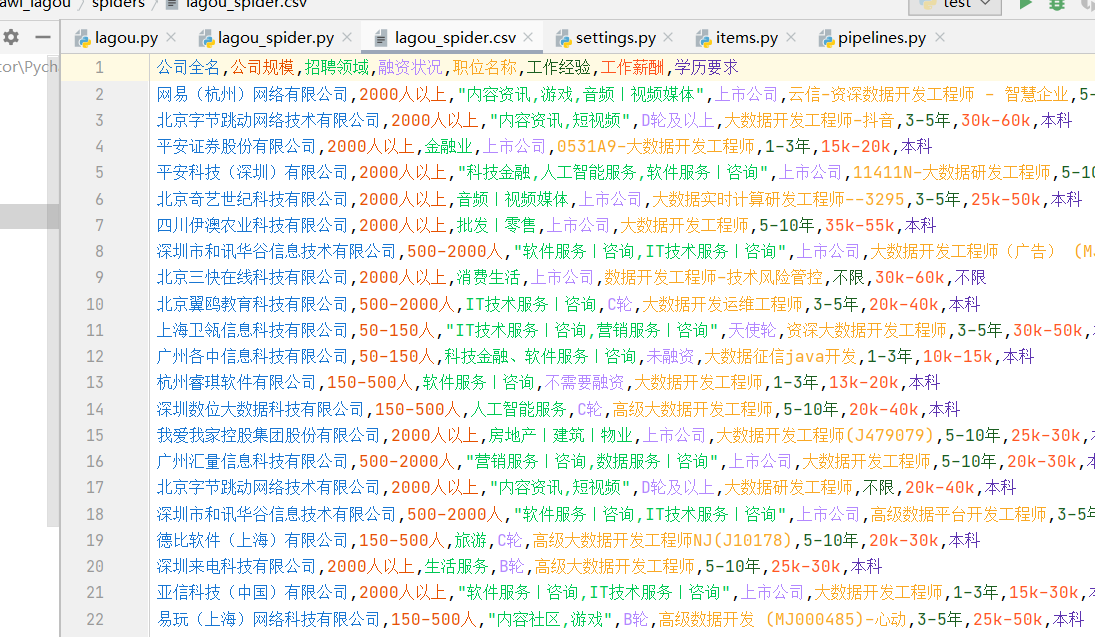
结果数据就是这样的:
Original: https://blog.csdn.net/weixin_47524964/article/details/121300747
Author: 路酴
Title: scrapy—拉勾网Ajax爬虫
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788754/
转载文章受原作者版权保护。转载请注明原作者出处!