

什么是scrapy
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
scrapy五大部件
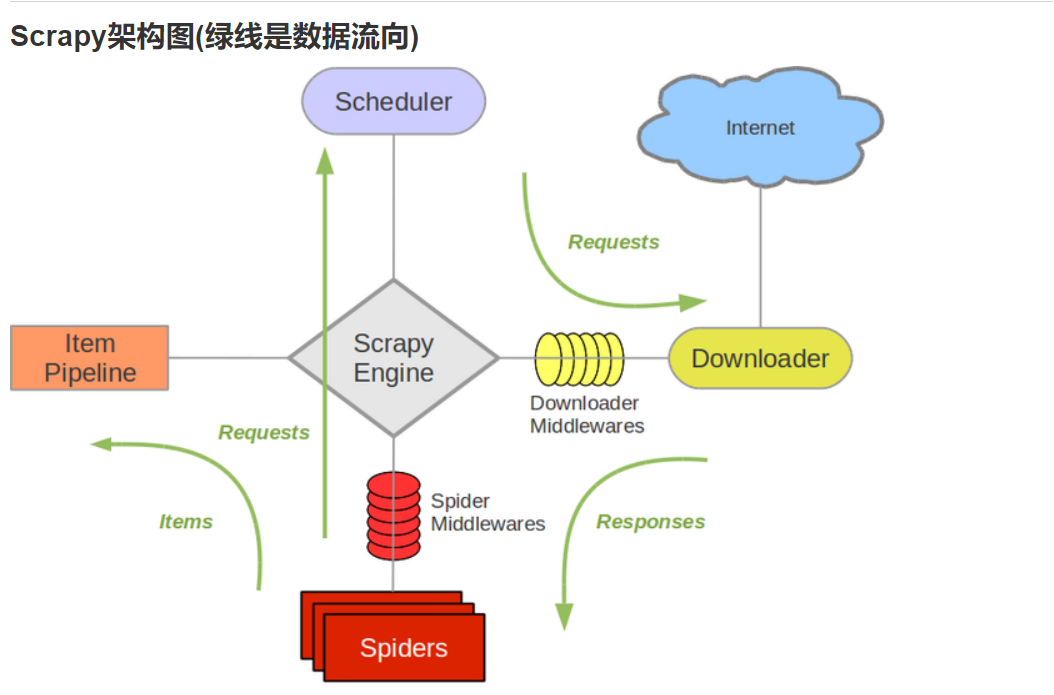

Scrapy Engine(引擎):
用来处理整个系统不同模块之间的数据,信号传递。(框架核心)
Scheduler(调度器):
用来接收引擎发过来的request请求,压入队列中,并在引擎再次请求的时候返回,同时去掉重复的url。
Downloader(下载器):
用于接收引擎发送过来的request请求,然后下载网页内容,并将网页内容返回给爬虫。
Spider(爬虫):
接收处理所有的网页内容,提取解析所需要的数据,并将需要跟进的url交给引擎。
Item Pipeline(管道):
处理爬虫中的item,主要功能是持久化存储,清理不需要的数据。
还有两个 middlewares 中间件。
Downloader Middlewares(下载中间件):位于引擎和下载器之间,主要用来包装 request 请求头,比如 UersAgent、Cookies 和代理 IP 等
Spider Middlewares(Spider中间件):位于引擎和爬虫之间,它主要用来修改响应对象的属性。
scrapy的工作流程
1、引擎在爬虫哪里拿到url交给调度器处理,调度器把处理好的request请求返回给引擎。
2、引擎把request请求交给下载器处理,下载器按照下载中间件的方法把下载好的内容交给引擎(如果下载失败,引擎会把request请求返回给调度器,之后在重新下载)。
3、引擎把下载好的内容交给爬虫,爬虫按照爬虫中间件的方法把解析好的数据提交给管道,同时把需要跟进的url返回给引擎。
4、管道对数据进行存储。
直到调度器队列中为空,也就是没有request请求了,整个程序才算运行完成。
下载scrapy
按照下面这个顺序在pycharm中下载
1、zope.interface
2、pyOpenSSL
3、Twisted
4、libxml2dom
5、lxml
6、Scrapy

里面有两个文件夹,打开Scripts,找找有没有scrapy.exe,有就把这个文件夹的路径复制,然后添加到系统的环境变量中。
创建工程
1、打开pycharm的终端(terminal)输入命令符 scrapy startproject testpro 回车(testpro是scrapy项目名),如果报错 无法将”scrapy”识别什么什么的,就试试py -m scrapy startproject testpro。(第一次用scrapy startproject就报错了,py -m scrapy startproject就没事,但是很奇怪的是之后用scrapy startproject又不报错了,如果输入命令报错了,可以在每个命令前面都加上py -m)

2、输入cd testpro 回车后输入scrapy genspider test www.xxx.com。(test是爬虫文件名,www.xxx.com是域名)

这样就建好了一个scrapy工程了。

下面是我在别的博主哪里看到的scrapy常用指令
常用指令 命令格式说明startprojectscrapy startproject
参考网址:http://c.biancheng.net/python_spider/scrapy.html
Original: https://blog.csdn.net/qq_53221728/article/details/123008441
Author: start field
Title: python爬虫之scrapy框架
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788566/
转载文章受原作者版权保护。转载请注明原作者出处!