

这段时间要写一个爬虫项目, 但是目标网站ip阈值限制很低, 两下就被ban了, 于是计划引入免费ip代理解决这一情况.
在网上找了很多资料, 但是用起来都是各种奇怪的报错, 只好见步行步, 一个个坑趟过去, 因为坑太多,所以写下这个笔记, 防止下次再做的时候有修半天.
第一步: 部署proxypool, 这个部分分为三步下载proxypool与redis, 启动redis服务, 启动 proxypool.

(1). 下载ProxyPool与Redis(系统为Windows)
下载地址:
Releases · jhao104/proxy_pool · GitHub
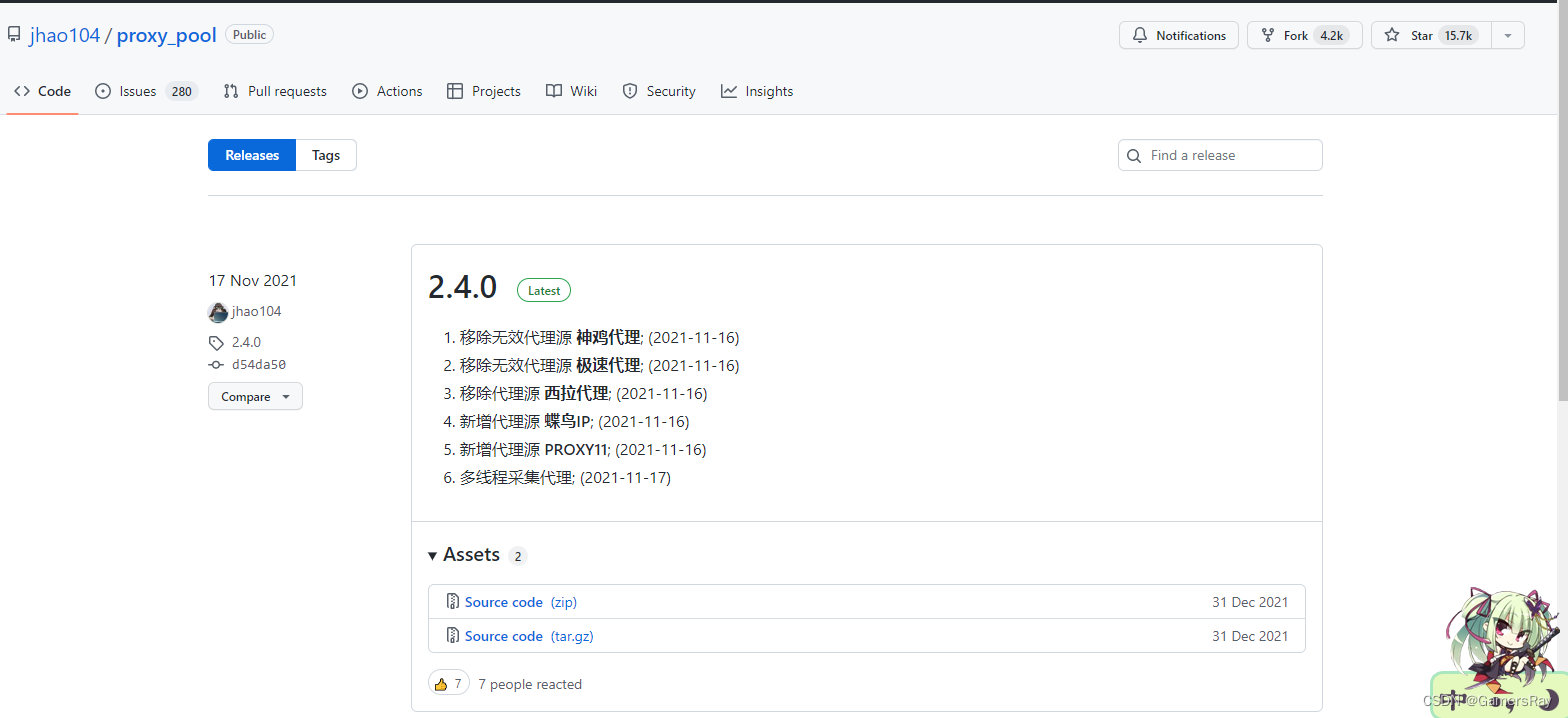
因为是使用windows系统, 这里使用的是
Releases · jhao104/proxy_pool · GitHub
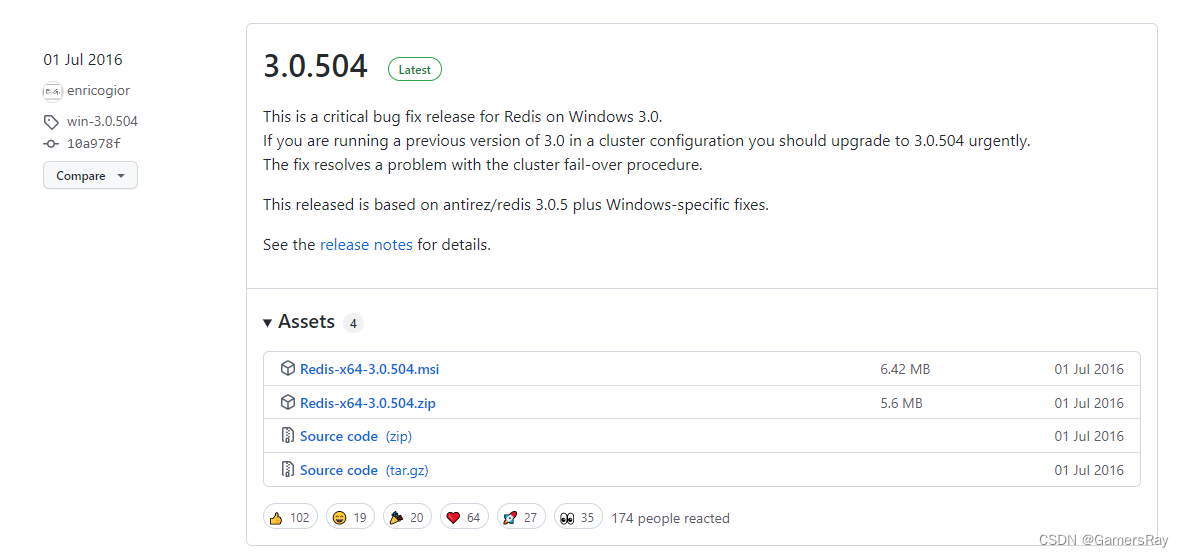
比较久远, 但是能用, 不纠结这些
两个压缩包都下载完以后, 随便解压到一个文件夹就行, 先去安装ProxyPool的依赖包
在ProxyPool解压文件夹输入cmd打开命令符
pip install -r requirements.txt

(2)安装redis
安装好包后, 先去吧redis启动一下
启动方式和ProxyPool一样, 都是在解压文件夹的位置使用cmd
先启动redis服务:
redis-server.exe redis.windows.conf

我已经启动过了,如果第一次启动会类似这样:
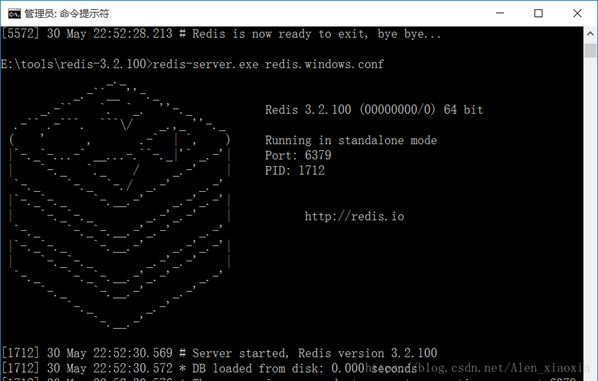
在redis根目录再打开一个cmd, 安装redis到 windows服务
redis-server --service-install redis.windows.conf
启动redis服务, 需要先把第一步打开的”启动服务”cmd窗口关闭, 再重新打开一个cmd窗口输入:
redis-server --service-start
启动完以后, 直接关闭cmd窗口即可
现在redis应该已经可以正常使用了, 在CMD输入一下代码检查redis状态
redis-cli.exe -h 127.0.0.1 -p 6379
(3)配置ProxyPool
打开ProxyPool所在根目录处的setting.py
############### server config ###############
HOST = "0.0.0.0"
PORT = 5010
############### database config ###################
db connection uri
example:
Redis: redis://:password@ip:port/db
Ssdb: ssdb://:password@ip:port
DB_CONN = 'redis://127.0.0.1:6379'
proxy table name
TABLE_NAME = 'use_proxy'
###### config the proxy fetch function ######
PROXY_FETCHER = [
"freeProxy01",
"freeProxy02",
"freeProxy03",
"freeProxy04",
"freeProxy05",
"freeProxy06",
"freeProxy07",
"freeProxy08",
"freeProxy09",
"freeProxy10"
]
DB_CONN:Redis数据库位置,注意ip和端口,127.0.0.1:6379, 如果redis有秘密啊就加在地址前并在后面加@
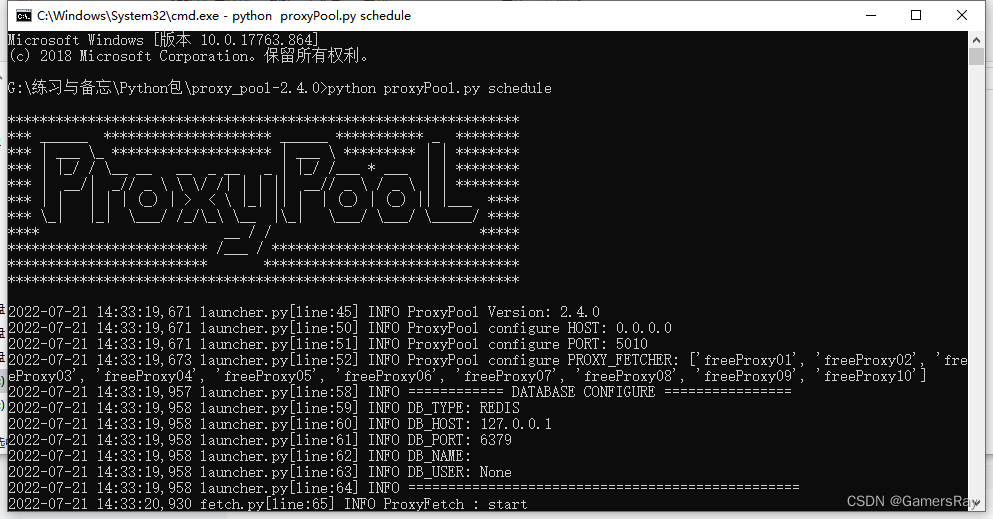
启动ProxyPool代理池(1) 启动调度程序:
python proxyPool.py schedule
(2) 启动webApi服务:
python proxyPool.py server 
这个可能会出现Api服务启动失败, 出现:ImportError: cannot import name ‘Markup’ from ‘jinja2’ Error
解决办法是安装l Flask==2.0.3 和 Jinja2==3.1.1
pip install Flask==2.0.3
pip install Jinja2==3.1.1.
Api服务启动成功:
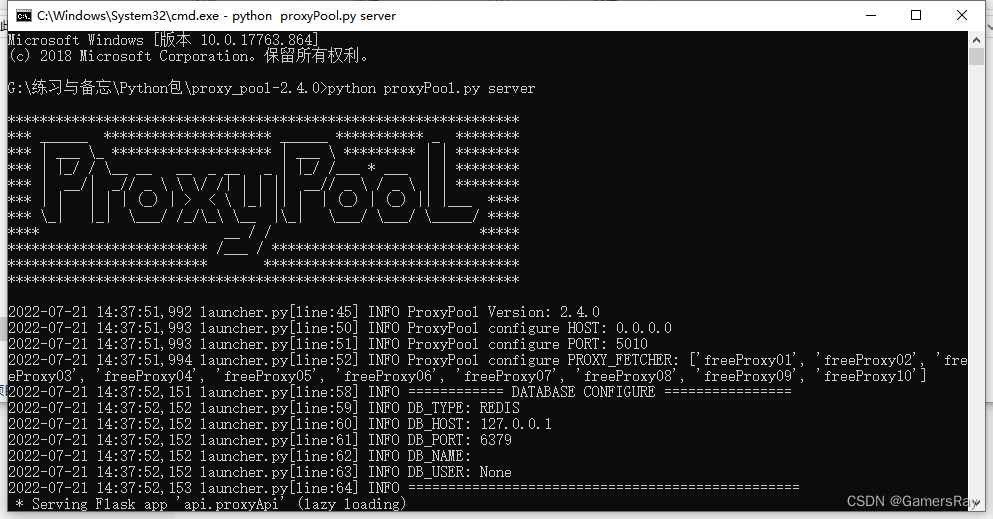
打开浏览器, 输入127.0.0.1:5010/count/可以查看现在可用的代理数量
输入127.0.0.1:5010/get/可以随机获得一条代理

第二步: 编写Scrapy中间件
(1).打开Scrapy项目所在根目录的middlewares.py, 添加代码:
from scrapy import signals
import json
import requests
import logging
import json, random
PROXY_URL = 'http://127.0.0.1:5010/get'
####################代理池接口###############################
class ProxyMiddleware(object):
def __init__(self, proxy_url):
self.logger = logging.getLogger(__name__)
self.proxy_url = proxy_url
# self.method = SSL.SSLv23_METHOD
def get_random_proxy(self):
try:
response = requests.get(self.proxy_url)
print(str(response))
road = 0
asd = 0
if response.status_code == 200:
global proxy
if road == asd :
p = json.loads(response.text)
print("P的值为" + str(p))
proxy = "{}".format(p.get('proxy'))
proxy = "http://" + proxy
print("代理地址:" + proxy)
print('get proxy ...')
ip = {"http": proxy, "https": proxy}
print("ip: " + str(ip))
r = requests.get("http://www.baidu.com", proxies=ip, timeout=60)
print("代理返回值为:" + str(r))
print("r的网页返回值:" + str(r.status_code))
if str(r.status_code) == 200:
return proxy
except:
print('get proxy again ...')
return self.get_random_proxy()
def process_request(self, request, spider):
proxy = self.get_random_proxy()
if proxy:
self.logger.debug('======' + '使用代理 ' + str(proxy) + "======")
request.meta['proxy'] = proxy
def process_response(self, request, response, spider):
if response.status != 200:
print("again response ip:")
request.meta['proxy'] = proxy
return request
return response
@classmethod
def from_crawler(cls, crawler):
settings = crawler.settings
return cls(
proxy_url=settings.get('PROXY_URL')
)
在这里因为出过很多问题在一直反复修改, 所以添加很多print展示状态, 有强迫症可以直接删掉.
(2).打开Scrapy项目所在根目录的settings.py, 添加以下代码:
###################################启用代理池################################
PROXY_URL = 'http://127.0.0.1:5010/get'
DOWNLOADER_MIDDLEWARES = {
'你项目的名字.middlewares.ProxyMiddleware': 543,
'scrapy.downloadermiddleware.httpproxy.HttpProxyMiddleware': None#关闭scrapy自带代理服务
}
DOWNLOADER_CLIENTCONTEXTFACTORY = 'imgsPro.context.CustomContextFactory'
现在已经和代理池连接完毕了
(3).进入到爬虫所在位置, 打开cmd, 启动爬虫:
scrapy crawl 你的爬虫名
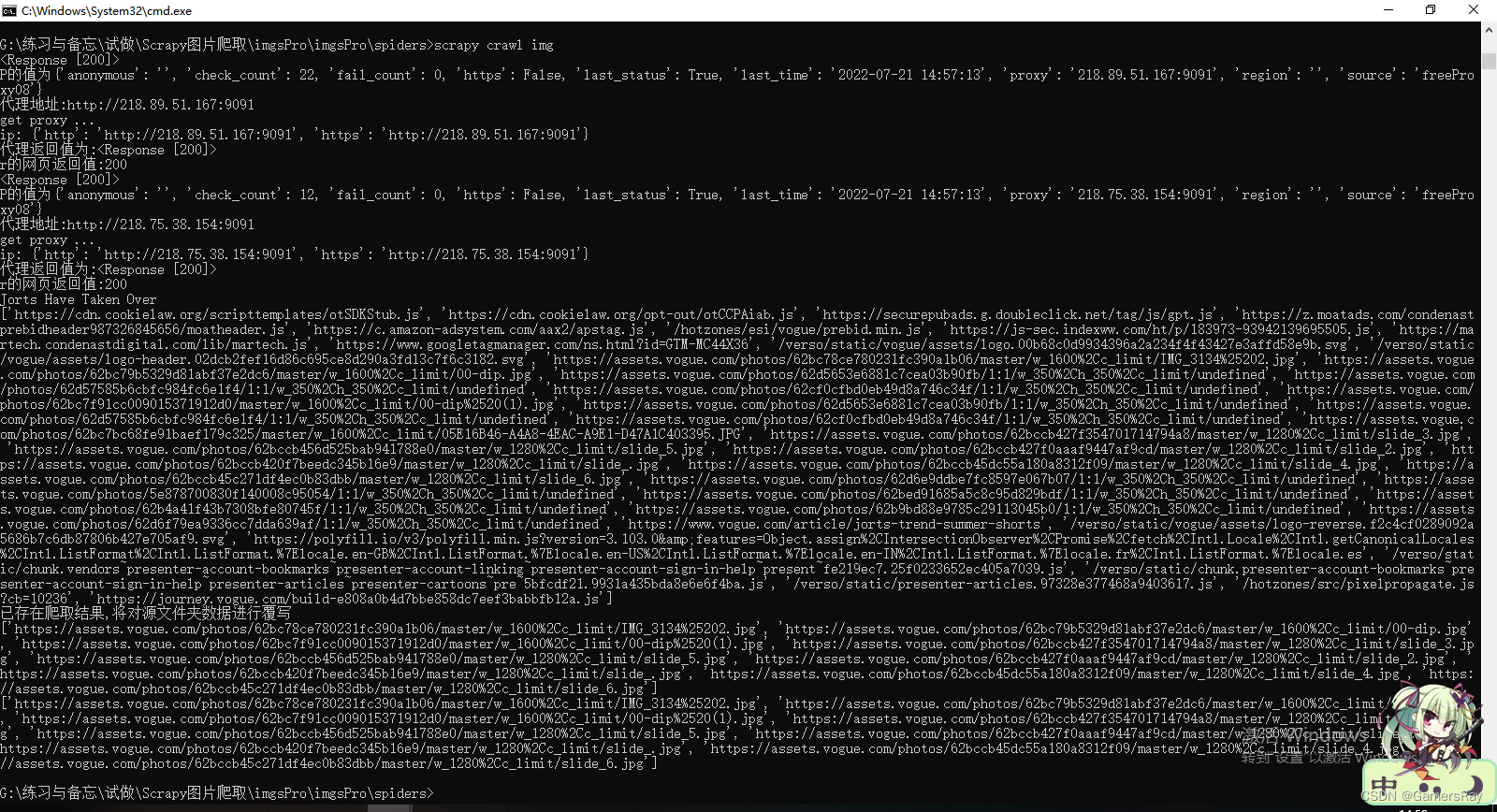
已经可以正常运行
Original: https://blog.csdn.net/GamersRay/article/details/125909288
Author: GamersRay
Title: Scrapy调用proxypool代理
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788562/
转载文章受原作者版权保护。转载请注明原作者出处!