

一、Scrapy框架介绍
”’Scrapy是适用于Python的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测以及自动化”’。


这个就是scrapy的介绍。
二、项目前安装
1、scrapy的安装。
这里的所有安装都一样,只要你的pip没损坏,那么pip install xxxx(scrapy)就可以,如果损坏了的话你需要写成这个格式python -m pip install -i 模块名 https://pypi.tuna.tsinghua.edu.cn/simple –upgrade pip 就可以了
2、pymysql的安装同上。
3、mysql.connector安装同上。
当然,这里的所有步骤是基于你有mysql,本机安装了mysql 的情况下,否则你怎么可能存储到人家里面呢,是吧。这里作者就不一一给大家找mysql的安装网站了,直接百度mysql就能找到官网了,另外说下,当你的mysql完全配备好了之后,你还要添加环境变量.环境变量配置好了之后如果你的sql是8.0级以上的你还需要这个操作。因为这些都是和我们后续的设置有很大关系的
三、案例执行
1、项目的创建
这次我们创建项目的方式与平常有很大的不同,于终端进行。如下
(打开pycharm,创建一个目录,点击下面的终端,随后进入到刚刚创建的目录下面cd xxx)进入后输入scrapy startproject (这里和上面的文件名可以不一样)xxx (Eg:scrapy startproject lieyun)
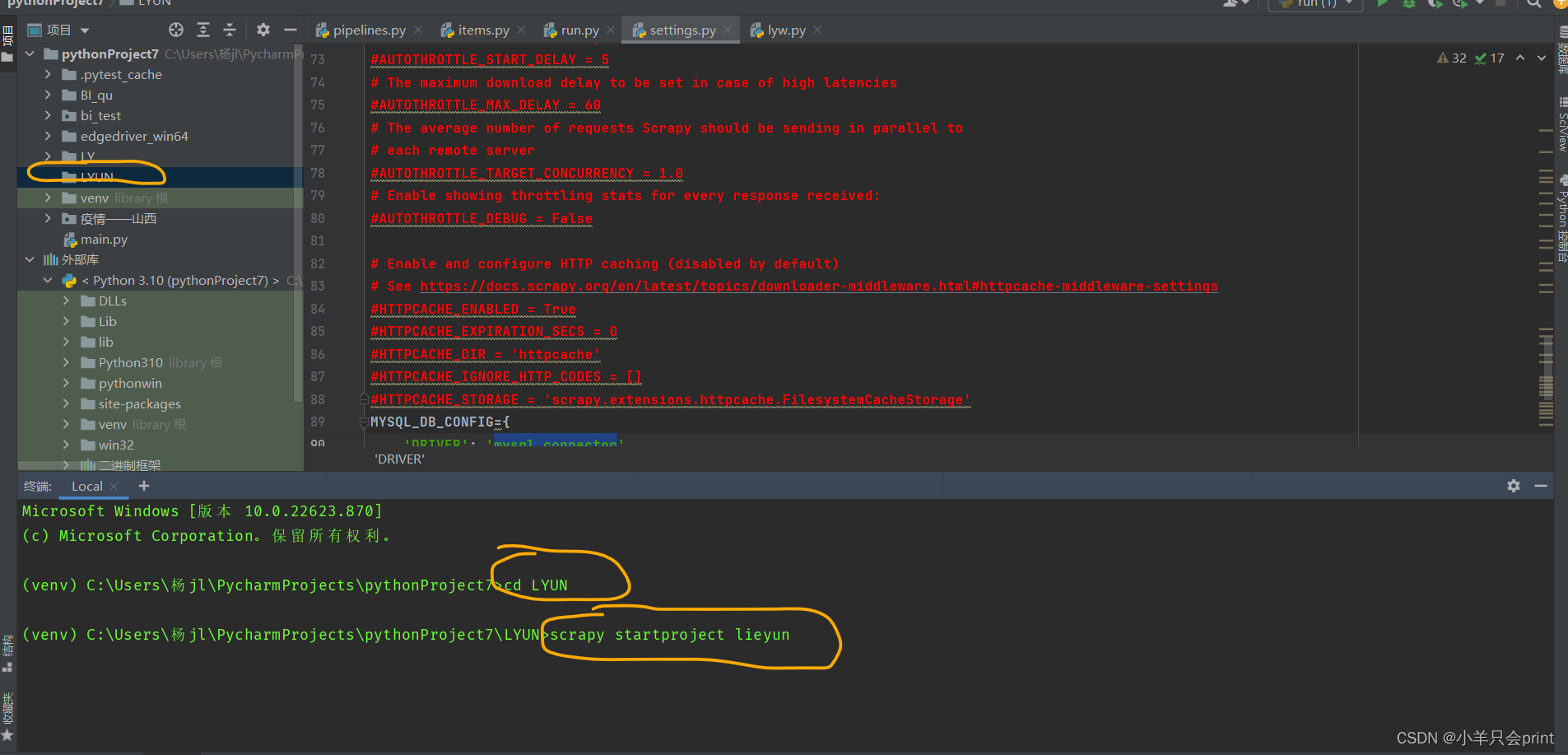
这里就已经创建好LYscrapy这个项目了,里面会生成很多打包的文件,足够我们使用
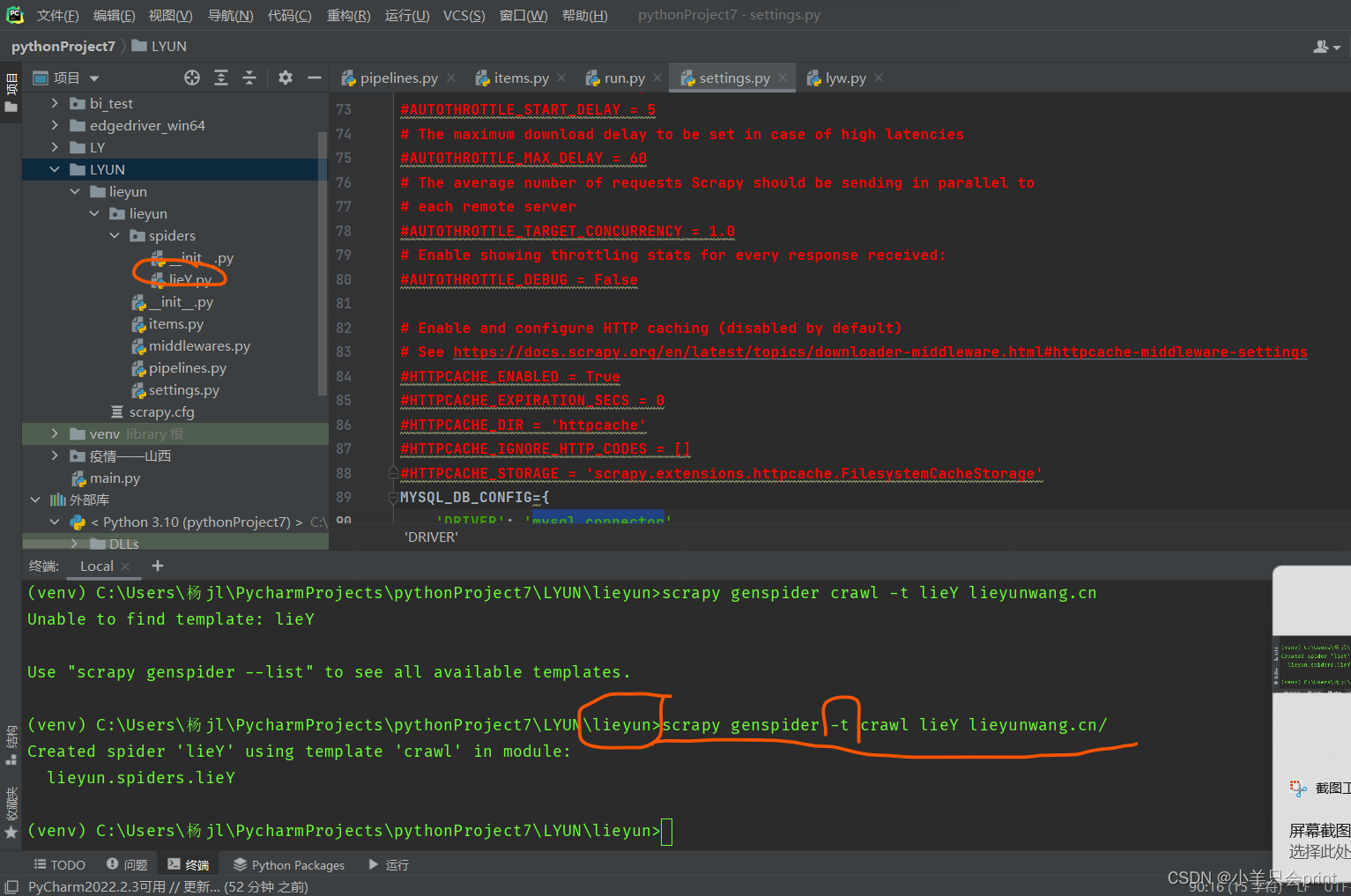
这里可以看到,生成了很多py文件,后续都会用到。scrapy genspider -t crawl 新文件名 域名(爬取的域名,www.后面的那一串) 。这里的genspider -t说的是指定运行文件格式 是crawl
2、案例部署设置
到这里我们的文件基本就已经创建完成,创建完成后第一步,进入到我们的最后一步创建的文件当中,在引擎spider里面。创建好文件之后里面会包含(spider文件夹,里面有你最后一步床的文件。itmes(用于传递给存储间用的,这里可以理解为定义表格字段(实例化爬取的字段))。pipeline(这个是用来存储用的,可以存储于表格,数据库等,可以理解为车站,有高铁,有火车,有班车),setting(这个是用于爬虫的时候需要设置的参数,一般就是UA和ip代理池而已))这里我们需要进入setting里设置,如下图

3、遵循robot(爬取)规则 这里我们当然不能遵循,否则我们什么都爬不出来

4、UA的设置,这里作者并没有取消注释经行设置,因为猎云网反能力不强,所以可以不添加

5、启动驱动的创建。将文件夹收起,那一大串消失后在这级创建一个启动的代码
from scrapy import cmdline
##注意,这里的lyw是作者在创建文件的时候最后一步的那个文件名,也就是spider中的py文件名
cmdline.execute('scrapy crawl lyw'.split(' '))
三、项目开启
这里由于代码量太多,作者就不一一解释,重要的解释都在代码块当中。
1、引擎间的描述:
spider的py文件中的代码。这个是引擎间
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
#..item的意思是从他的上一级查找item并导入itme的LieyunItem模块
from ..items import LieyunItem
class LywSpider(CrawlSpider):
#这是我们的引擎文件名
name = 'lyw'
##这是我们的网站域名
allowed_domains = ['lieyunwang.cn']
##这里需要填写你怕爬取的第一个网站的全部url,作为起点
start_urls = ['https://m.lieyunwang.cn/latest/p1.html']
rules = (
##这个是url,第一个是用于查找下一章节的url的,用正则表达式的方法选取我们下一张要爬取的的url
Rule(LinkExtractor(allow=r'/latest/p\d+.html'), follow=True),
##这个是每一篇文章的url,用正则方式选取,为了能够进入该网页爬取数据
Rule(LinkExtractor(allow=r'/archives/\d+'),callback='parse_item', follow=True)
)
def parse_item(self, response):
'标题'
title=response.xpath("//h1[@class='archives-title']/text()").getall()
title="".join(title).strip()
'发布公司'
company=response.xpath("//div[@class='tag']/span/text()").getall()
company = "".join(company).strip()
'今日爆言'
tell=response.xpath("//div[@class='archives-digest']/text()").get()
'作者'
scoure=response.xpath("//div[@class='main-text']/p/strong/text()").get()
'内容'
content=response.xpath("//div[@class='main-text']/p/text()").getall()
content="".join(content).strip()
'发布时间'
a_time=response.xpath("//div[@class='time pull-right']/text()").get()
a_time="".join(a_time).strip()
article_url=response.url
##创建猎运item对象,将输入传入
item=LieyunItem()
#兄弟们可以理解为键值对的的赋值
item['title']=title
item['a_time']=a_time
item['company']=company
item['tell']=tell
item['scoure']=scoure
item['content']=content
item['article_url']=article_url
##解析完成后,将推送到pipeline
yield item
2、itme激活器的描述
Define here the models for your scraped items
#
See documentation in:
https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class LieyunItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
##接受从lyw中传入的数据,实例化,并经行下一步传输,作用可以理解为激活,然后传给pipelines
title=scrapy.Field()
a_time=scrapy.Field()
company=scrapy.Field()
tell=scrapy.Field()
scoure=scrapy.Field()
content=scrapy.Field()
article_url=scrapy.Field()
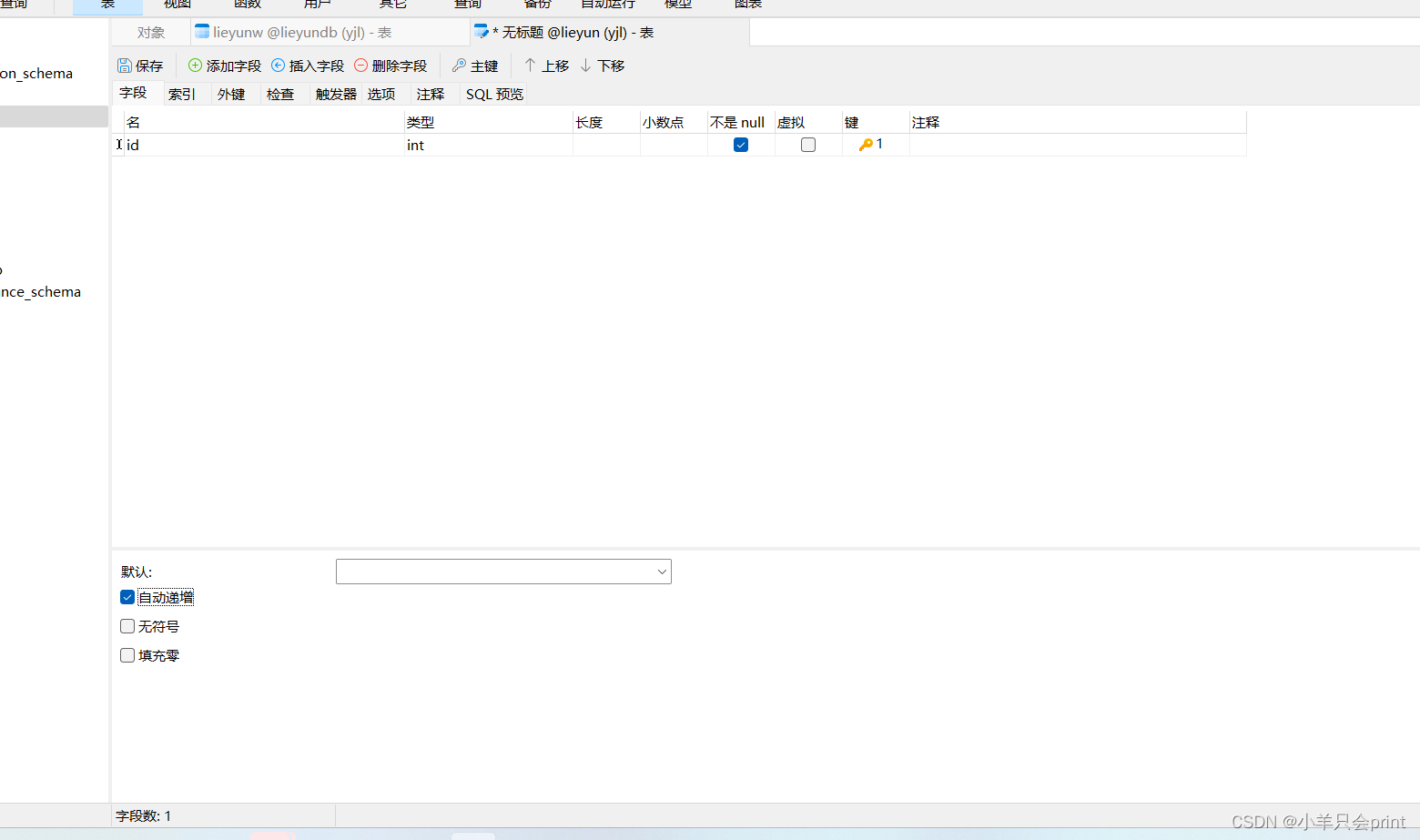
3、mysql创建表格
4、下载器的描述设置(这个是重点)
Define your item pipelines here
#
Don't forget to add your pipeline to the ITEM_PIPELINES setting
See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
useful for handling different item types with a single interface
from itemadapter import ItemAdapter
import pymysql
from twisted.enterprise import adbapi
class LieyunPipeline(object):
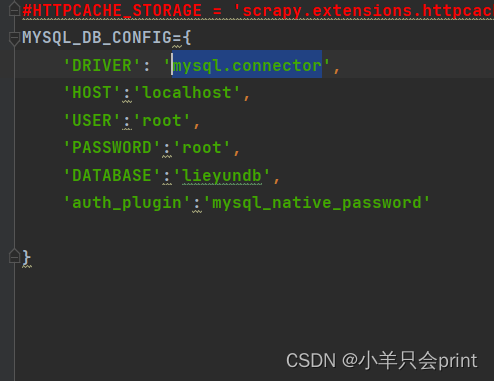
def __init__(self,mysql_config):
##这里的方法和之前我们的setting中的内容很象,主要是用来参数的连接,并实例化
self.dbpool=adbapi.ConnectionPool(
mysql_config['DRIVER'],
host=mysql_config['HOST'],
user=mysql_config['USER'],
password=mysql_config['PASSWORD'],
database=mysql_config['DATABASE'],
auth_plugin=mysql_config['auth_plugin'],
charset='utf8'
)
@classmethod
def from_crawler(cls,crawler):
#编写类方法,这是核心,主要是调用setting配置的mysql,用于连接sql数据库
mysql_config=crawler.settings['MYSQL_DB_CONFIG']
return cls(mysql_config)
def process_item(self, item, spider):
##这里的方法是用来执行sql语句传输数据
result=self.dbpool.runInteraction(self.insert_into,item)
##这里是用来如果报错,则交给insert_erro处理,解释原因
result.addErrback(self.insert_erro)
return item
##执行sql语句插入方法
def insert_into(self,cursor,item):
##编写mysql插入语句,注意,这里的id为null,代表不填入,倘若你之前创建的时候没勾选自增,那么需要到mysql中去改一下
sql='insert into lieyunw (id,title,a_time,company,tell,scoure,content,article_url) values (null ,%s,%s,%s,%s,%s,%s,%s)'
args=(item['title'],item['a_time'],item['company'],item['tell'],item['scoure'],item['content'], item['article_url'])
cursor.execute(sql,args)
##添加这一方法是为了我们能够得知如果报错是什么错误
def insert_erro(self,failure):
print('========================================')
print(failure)
print('============================================================')
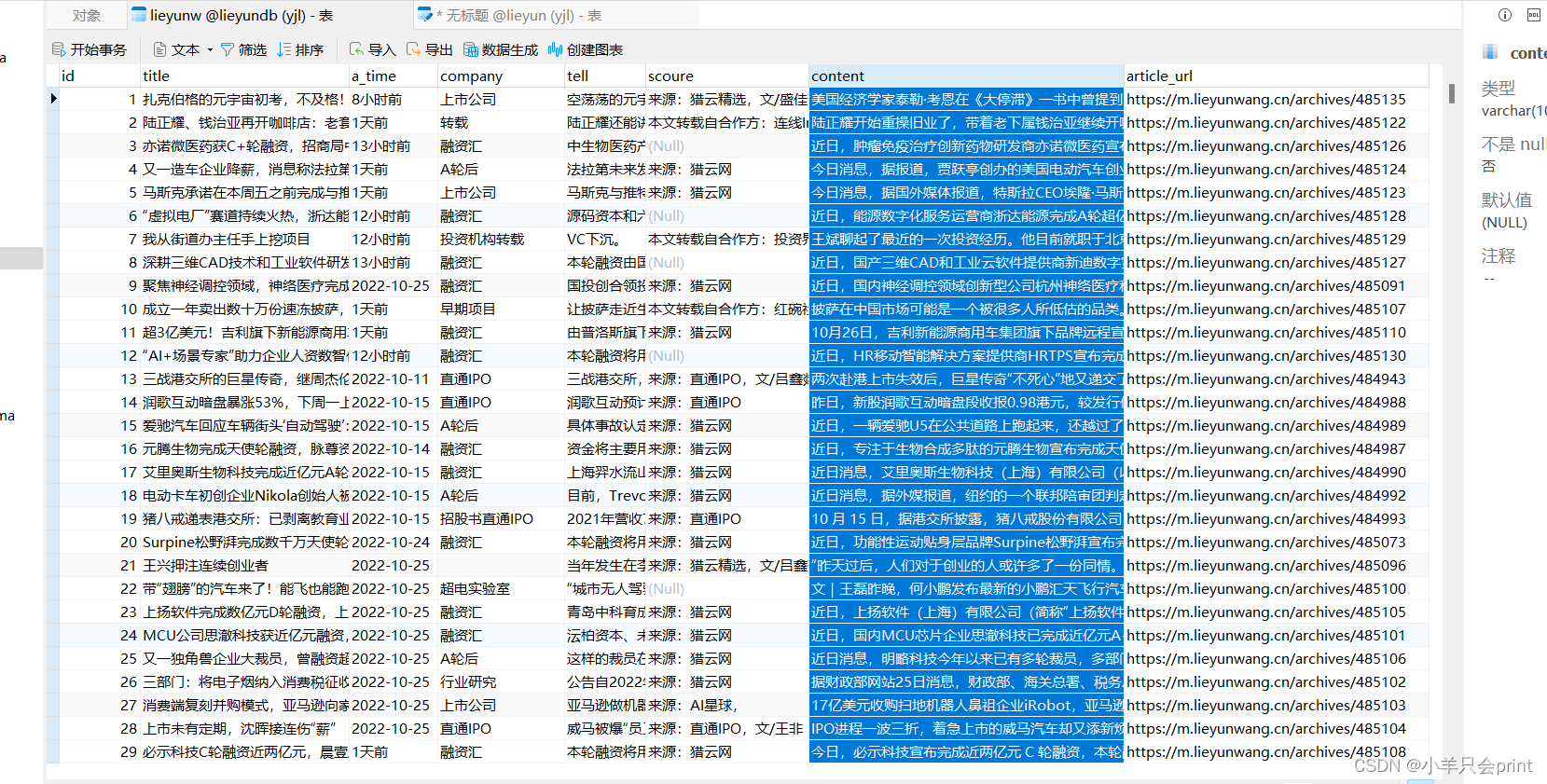
四、成果展示
到此为之项目基本结束,这就是 我们对应的每篇章节,每个新闻的内容的保存
五、报错指南
相信大家都不会一番风顺的完成这个案例,不过我依旧希望最好能够一次性完成,以下是作者总结的报错
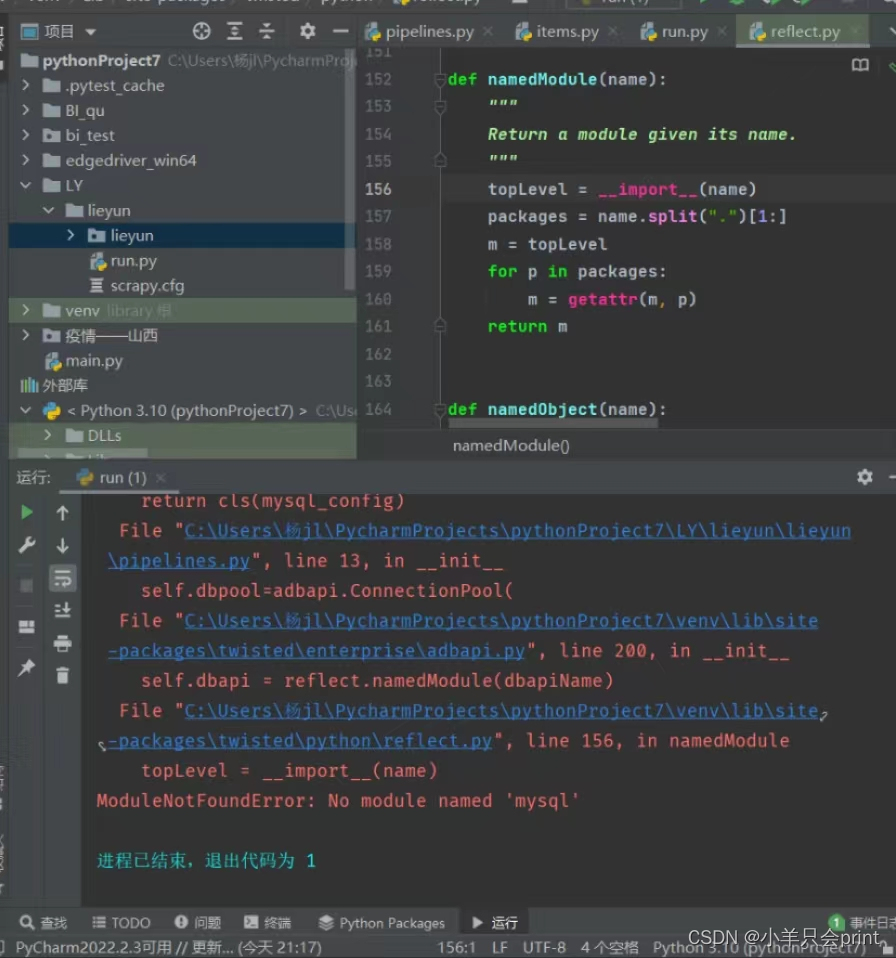
1、 ‘mysql.connector.errors.NotSupportedError’>: Authentication plugin ‘caching_sha2_password’ is not supported。(没下载mysql.connector,需要pip一下)
2、’mysql.connector.errors.InterityError ‘>1048(23000):column ‘id’ cannot be null(这一类错误是属于mysql内的错误,也就是说你上传数据库的时候,你的id是主键约束不能为空的,但是您在上传的时候选择了null,这时候你可以去mysql中重新修改下id字段,将自增约束勾选上) 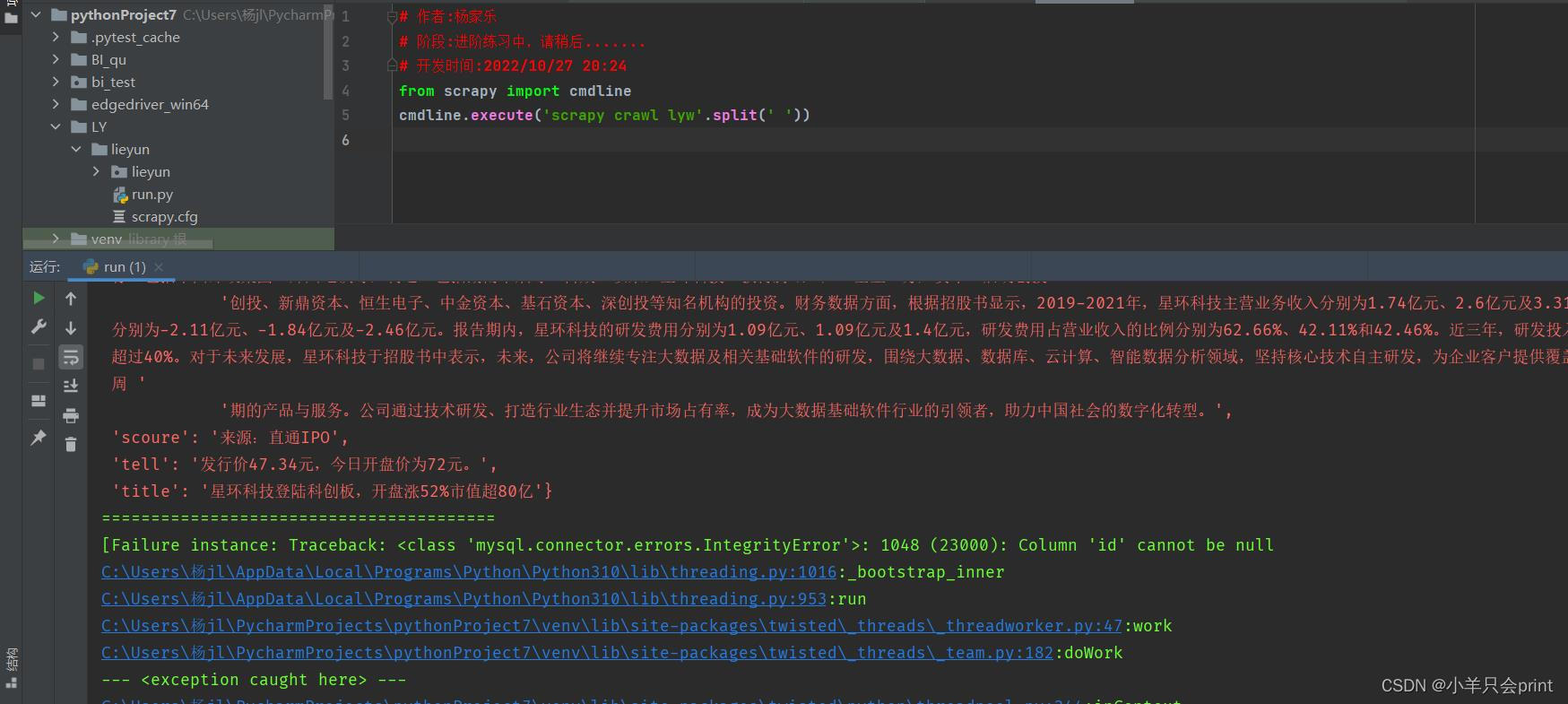
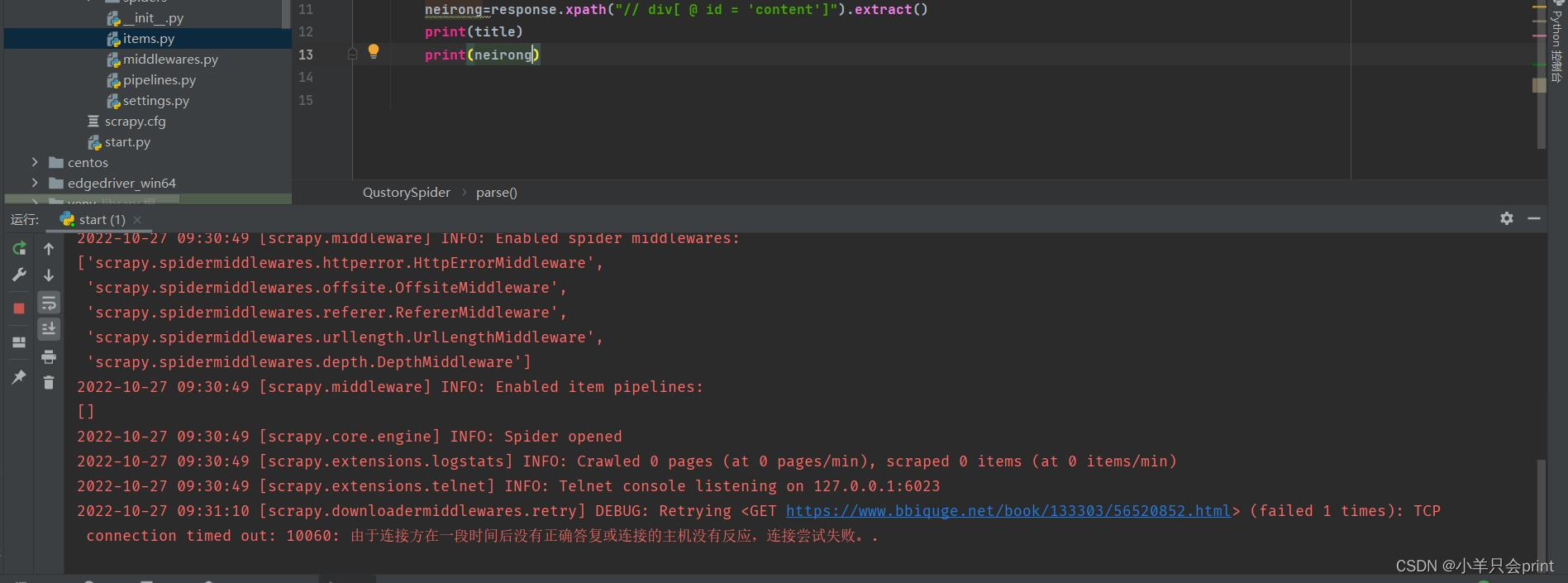
3、”由于链接方在一段时间内没有正确的答复或连接反应,连接尝试失败”(
反爬,或者网络状态不加,要么加请求头UA,要么ip代理池 )
这是今天一位老师送给我的话,感受良多:技术建立在基础上你要一步一步打牢基础,而不是为了追求速度去学习。基础牢固后你的问题也会越来越少。如果有一天及发现你在学习这方面进展不行了,不妨提升下自己的技术。
听到这句话瞬间我并不明白到底是什么意思,难道学习不就是在提升技术吗。过后才了解其意,到底是为了get什么
Original: https://blog.csdn.net/m0_66044243/article/details/127562946
Author: 小羊只会print
Title: python框架之Scrapy&&自动存储mysql数据库
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/788502/
转载文章受原作者版权保护。转载请注明原作者出处!