

Diffusion Models:生成扩散模型
当前的内容是梳理《Transformer视觉系列遨游》系列过程中引申出来的。目前最近在AI作画这个领域 Transformer 火的一塌糊涂,AI画画效果从18年的 DeepDream[1] 噩梦中惊醒过来,开始从2022年 OpenAI 的 DALL·E 2[2] 引来插画效果和联想效果都达到惊人效果。虽然不懂,但是这个话题很吸引ZOMI,于是就着这个领域内容来看看有什么好玩的技术点。


但是要了解: Transformer 带来AI+艺术,从语言开始遇到多模态,碰撞艺术火花 这个主题,需要引申很多额外的知识点,可能跟 CV、NLP 等领域大力出奇迹的方式不同,AI+艺术会除了遇到 Transformer 结构以外,还会涉及到 VAE、ELBO、Diffusion Model等一系列跟数学相关的知识。
Transformer + Art系列中,今天新挖一个 Diffusion Models 的坑,跟 VAE 一样原理很复杂,实现很粗暴。据说生成扩散模型以数学复杂闻名,似乎比 VAE、GAN 要难理解得多,是否真的如此?扩散模型能少来点数学吗?扩散模型真的做不到一个简单点的理解吗?
在本文中,我们将研究扩散模型的理论基础,然后演示如何在 PyTorch 中使用扩散模型生成图像。Let’s dive in!
Diffusion Model 基本介绍
扩散模型(Diffusion Models)发表以来其实并没有收到太多的关注,因为他不像 GAN 那样简单粗暴好理解。不过最近这几年正在生成模型领域异军突起,当前最先进的两个文本生成图像——OpenAI 的 DALL·E 2和 Google 的 Imagen,都是基于扩散模型来完成的。
如今生成扩散模型的大火,则是始于2020年所提出的 DDPM(Denoising Diffusion Probabilistic Model),仅在 2020 年发布的开创性论文 DDPM 就向世界展示了扩散模型的能力,在图像合成方面击败了 GAN[6],所以后续很多图像生成领域开始转向 DDPM 领域的研究。
看了下网上很多文章在介绍 DDPM 时,上来就引入概率转移分布,接着就是变分推断,然后极大值似然求解和引入证据下界(Evidence Lower Bound)。一堆数学记号下来,先吓跑了前几周的我(当然,从这种介绍我们可以再次看出,DDPM 实际上与 VAE 的理论关系是非常紧密),再加之人们对传统扩散模型的固有印象,所以就形成了”需要很高深的数学知识”的错觉。
生成模型对比
还是先横向对一下最近比较火的几个生成模型 GAN、VAE、Flow-based Models、Diffusion Models。
GAN 由一个生成器(generator)和判别器(discriminator)组成,generator 负责生成逼真数据以”骗”过 discriminator,而 discriminator 负责判断一个样本是真实的还是”造”出来的。GAN 的训练其实就是两个模型在相互学习,能不能不叫”对抗”,和谐一点。
VAE 同样希望训练一个生成模型 x=g(z),这个模型能够将采样后的概率分布映射到训练集的概率分布。生成隐变量 z,并且 z 是及含有数据信息又含有噪声,除了还原输入的样本数据以外,还可以用于生成新的数据。
Diffusion Models 的灵感来自 non-equilibrium thermodynamics (非平衡热力学)。理论首先定义扩散步骤的马尔可夫链,以缓慢地将随机噪声添加到数据中,然后学习逆向扩散过程以从噪声中构造所需的数据样本。与 VAE 或流模型不同,扩散模型是通过固定过程学习,并且隐空间 z 具有比较高的维度。
总的来看,Diffusion Models 领域正处于一个百花齐放的状态,这个领域有一点像 GAN 刚提出来的时候,目前的训练技术让 Diffusion Models 直接跨越了 GAN 领域调模型的阶段,直接可以用来做下游任务。
基本介绍
Diffusion Models 既然叫生成模型,这意味着 Diffusion Models 用于生成与训练数据相似的数据。从根本上说,Diffusion Models 的工作原理,是通过连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过程,来学习恢复数据。
训练后,可以使用 Diffusion Models 将随机采样的噪声传入模型中,通过学习去噪过程来生成数据。也就是下面图中所对应的基本原理,不过这里面的图仍然有点粗。
更具体地说,扩散模型是一种隐变量模型(latent variable model),使用马尔可夫链(Markov Chain, MC)映射到 latent space。通过马尔科夫链,在每一个时间步 t 中逐渐将噪声添加到数据 xi 中以获得后验概率 q(x1:T∣x0) ,其中 x1,…,xT 代表输入的数据同时也是 latent space。也就是说 Diffusion Models 的 latent space 与输入数据具有相同维度。
马尔可夫链(Markov Chain, MC)是概率论和数理统计中具有马尔可夫性质(Markov property)且存在于离散的指数集(index set)和状态空间(state space)内的随机过程(stochastic process)。
Diffusion Models 分为正向的扩散过程和反向的逆扩散过程。下图为扩散过程,从 x0 到最后的 xT 就是一个马尔科夫链,表示状态空间中经过从一个状态到另一个状态的转换的随机过程。而下标则是 Diffusion Models 对应的图像扩散过程。
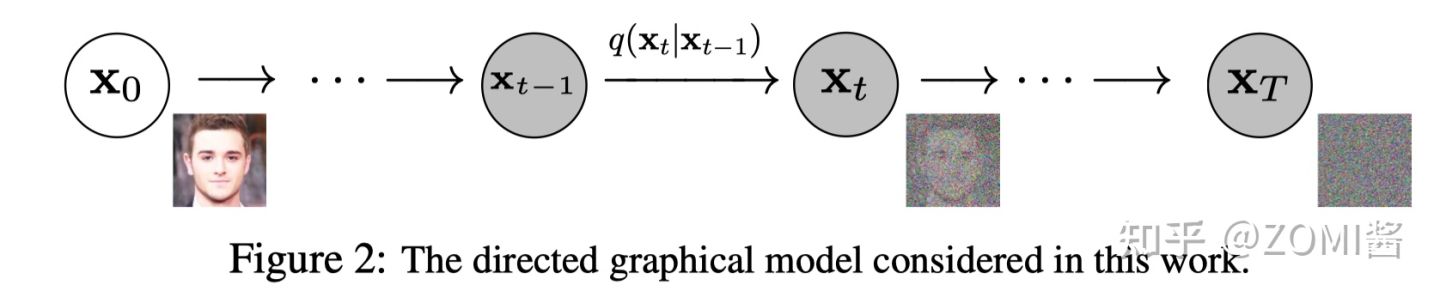
最终,从 x0 输入的真实图像,经过 Diffusion Models 后被渐近变换为纯高斯噪声的图片 xT 。
模型训练主要集中在逆扩散过程。训练扩散模型的目标是,学习正向的反过程:即训练概率分布 pθ(xt−1∣xt) 。通过沿着马尔科夫链向后遍历,可以重新生成新的数据 x0 。读到这里就有点意思啦,Diffusion Models 跟 GAN 或者 VAE 的最大区别在于不是通过一个模型来进行生成的,而是基于马尔科夫链,通过学习噪声来生成数据。
除了生成很好玩的高质量图片之外呢,Diffusion Models 还具有许多其他好处,其中最重要的是训练过程中不需要再对抗了,整个世界都感觉和平了。因为对于 GAN 网络模型来说,对抗性训练其实是很不好调试的,因为对抗训练过程互相博弈的两个模型,对我们来说是个黑盒子。另外在训练效率方面,扩散模型还具有可扩展性和可并行性,那这里面如何加速训练过程,如何添加更多数学规则和约束,扩展到语音、文本、三维领域就很好玩了,可以出很多新文章。
详解 Diffusion Model
上面已经清晰表示了 Diffusion Models 由正向过程(或扩散过程)和反向过程(或逆扩散过程)组成,其中输入数据逐渐被噪声化,然后噪声被转换回源目标分布的样本。
如果不想深入了解数学原理的可以直接跳过到代码实现部分。如果还是想了解一些基础的数学原理,那么可以接着继续看,其实没比 GAN 难多少,就是个马尔科夫链 + 条件概率分布。 核心在于如何使用神经网络模型,来求解马尔科夫过程的概率分布。
扩散和逆扩散过程
前向过程由于每个时刻 t 只与 t-1 时刻有关,所以可以看做马尔科夫过程,在马尔科夫链的前向采样过程中,也就是扩散过程中可以将数据转换为高斯分布。即扩散过程通过 T 次累积对输入数据 xi 添加高斯噪声,将这个跟马尔可夫假设相结合,于是可以对扩散过程表达成:
(1)q(x1:T∣x0):=∏t=1Tq(xt∣xt−1):=∏t=1TN(xt;1−βtxt−1,βtI)
其中 β1,…,βT 是高斯分布方差的超参数。在扩散过程中,随着 t 的增大, xt 越来越接近纯噪声。当 T 足够大的时候, xT 可以收敛为标准高斯噪声 N(0,I) 。
不过呢,扩散模型的神奇”魔力”来自逆扩散过程。如果说扩散过程是加噪的过程,那么逆扩散过程就是去噪推断过程。如果我们能够逐步得到逆转后的分布 pθ(xt−1∣xt) ,就可以从标准高斯分布 N(0,I) 还原出样本数据的分布 x0 。
也就是在训练时候,模型学习逆扩散过程的概率分布,以生成新数据。如下图所示,从纯高斯噪声 p(xT):=N(xT;0,I) 开始,模型将学习联合概率分布 pθ(xT:0) :
(2)pθ(xT:0):=p(xT)∏t=1Tpθ(xt−1∣xt):=p(xT)∏t=1TN(xt−1;μθ(xt,t),Σθ(xt,t))
根据马尔可夫规则表示,逆扩散过程当前时间步 t 只取决于上一个时间步 t-1,所以有:
(3)pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))
现在我们其实已经简单搞清楚了 Diffusion Models 的扩散过程和逆扩散过程,也就是扩散过程中,人工添加一点点噪声直到数据为纯高斯噪声;逆扩散过程学习逆转后的分布,逐步地恢复样本数据。
不过,马尔科夫过程最麻烦的就是求解了,一般会用蒙特卡洛法进行采样,然后再去评估采样的结果好坏。上面的 Diffusion Models 会不会太理想啦?
训练方式
搞清楚逆扩散过程之后,现在算是搞清楚去噪推断过程。但是如何训练 Diffusion Models 以求得公式 (3) 中的均值 μθ(xt,t) 和方差 Σθ(xt,t) 呢?
在 VAE 中我们学过极大似然估计的作用: 对于真实的训练样本数据已知,要求模型的参数,可以使用极大似然估计。Diffusion Models 通过极大似然估计,来找到逆扩散过程中马尔科夫链转换的概率分布,这就是 Diffusion Models 的训练目的。即最大化模型预测分布的对数似然:
(4)L=Eq[−logpθ(x0)]
对于神经网络模型来说,一般优化的方式是通过损失函数求解网络模型的最小值,求最大化期望不太好使。于是换个思路,求模型的极大似然估计,等同于求解最小化负对数似然的变分上限 Lvlb (Variational Upper Bound):
(5)E[−logpθ(x0)]≤Eq[−logpθ(x0:T)q(x1:T∣x0)]=:Lvlb
因为变分上界比较难求,但是 VAE 的推导中介绍过其实可以通过 KL散度来表示上界。那到这里为止, 最小化Lvlb 即可最小化 Diffusion Models 的目标损失。
看到公式 (5) 会不会觉很熟悉,下面讲讲两个小概念,再引入如何求解最小化变分上限 Lvlb。
什么是KL散度呢?
我们回顾一下, KL 散度是一种不对称统计距离度量,用于衡量一个概率分布 P 与另外一个概率分布 Q 的差异程度。之所以想根据 KL 散度来求解 Lvlb,是因为根据 Diffusion Models 的定义马尔可夫链中的转移分布属于高斯分布,而 KL 散度则可以用来计算2个高斯分布之间的差异距离。
连续分布的 KL 散度的数学形式是:
(6)DKL(P‖Q)=∫−∞∞p(x)log(p(x)q(x))dx
用 KL 散度来表示变分上界
根据 Diffusion Models 最早提出的一篇文章[1],进一步对 Lvlb 推导,可以得到变分上限为熵与多个KL散度的累加,根据 KL 散度重写变分上限有:
(7)Lvlb=L0+L1+…+LT−1+LT
其中有:
(8)L0=−logpθ(x0∣x1)
(9)Lt−1=DKL(q(xt−1∣xt,x0)‖pθ(xt−1∣xt))
(10)LT=DKL(q(xT∣x0)‖p(xT))
x0 都会出现在扩散过程中的 Lt−1 ,现在所有 KL 散度都是在高斯概率分布之间进行比较。 这意味着可以使用闭包表达式,而不是采样的蒙特卡洛估计方式来精确计算变分上界。
到这里看不懂没关系,想表达的是最小化 Lvlb 即可最小化 Diffusion Models 的目标损失,而求解 Lvlb 则可以通过计算 KL 散度来代替。
有了目标函数的数学基础后,现在需要就如何实现扩散模型训练过程有几个细节:
- 对于正向扩散过程,唯一需要的选择是概率相关的向量(均值和方差),其值在扩散过程中在隐变量 xt 中直接添加高斯参数 βt 。
- 对于逆扩散过程,需要选择能够表达高斯分布的模型结构,神经网络模型的拟合能力很强,于是就可以引入神经网络模型啦。
- 最后就是对于神经网络模型有一个简单的要求,模型的输入、输出、中间隐变量必须要有相同的维度 dims。
损失函数和 LT
既然有神经网络模型,那自然离不开损失函数,有了损失函数就有了优化的方向和目标,下面来展开损失函数的定义。
在扩散过程公式(1)中,其中 β1,…,βT 是高斯分布方差的超参数。且实际中 βt 随着 t 增大是递增的,即 β1
Original: https://blog.csdn.net/m0_37046057/article/details/126151446
Author: ZOMI酱
Title: Diffusion Models:生成扩散模型
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/786282/
转载文章受原作者版权保护。转载请注明原作者出处!