

系列文章目录
在本系列文章中笔者将手把手带领大家实现基于强化学习的通关类小游戏,笔者将考虑多种方案,让角色顺利通关。本文将讲述如何使用 Q-Learning算法实现AI通关。
完整代码已上传至github:https://github.com/TommyGong08/RL_shoot_game
【强化学习】手把手教你实现游戏通关AI(1)——游戏界面实现
【强化学习】手把手教你实现游戏通关AI(2)——Q-Learning
文章目录
Q-Learning算法
QL的思想是:为每个状态-动作对学习动作函数Q(s,a)
Q(s,a)的值是在状态s中执行动作a之后获得的累计返回值。agent直接从历史经验中学习,不需要完全了解环境模型。当agent做出决策时,只需要比较 s状态下每个动作对应的Q(s,a)值,就可以确定s状态下的最优策略,而 不考虑状态s的后续状态。
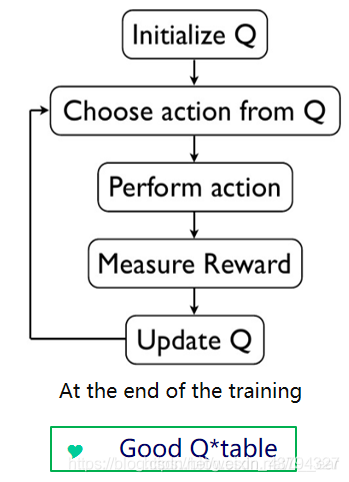
Q_learning算法流程如图所示:


在主函数中我们按照如下步骤进行:
- 随机初始化Q表
- 对于每一个游戏情节:
- 从Q表中选择当前状态对应的action
- 实施这个action(这时候物体已经移动到下一个状态s_了)
- 对于状态s_,观察奖励reward
- 更新Q表
即如下流程图所示:
; 主程序
"""
游戏的主程序,调用q_learning和env
"""
from game import Mygame
from q_learning import QLearning
import pygame
def update():
for episode in range(100):
state = env.reset()
print(state)
step_count = 0
while True:
clock = pygame.time.Clock()
clock.tick(10)
action = RL.choose_action(str(state))
state_, reward, done = env.step(action)
step_count += 1
RL.learn(str(state), action, reward, str(state_))
state = state_
env.person = state
env.draw_map()
if done:
print("回合 {} 结束. 总步数 : {}\n".format(episode + 1, step_count))
break
print('游戏结束')
pygame.quit()
if __name__ == "__main__":
pygame.init()
env = Mygame()
RL = QLearning(actions=list(range(env.n_actions)))
update()
print('\nQ table:')
print(RL.q_table)
Q-Learning代码
注:为了避免角色陷入局部解,我们在动作选择函数choose_action中采用Epsilon Greedy 贪婪方法。
"""
Q Learning Algorithm
"""
import numpy as np
import pandas as pd
class QLearning:
def __init__(self, actions, learning_rate=0.01, discount_factor=0.9, e_greedy=0.1):
self.actions = actions
self.lr = learning_rate
self.gamma = discount_factor
self.epsilon = e_greedy
self.q_table = pd.DataFrame(columns=self.actions, dtype=np.float32)
def check_state_exist(self, state):
if state not in self.q_table.index:
self.q_table = self.q_table.append(
pd.Series(
[0] * len(self.actions),
index=self.q_table.columns,
name=state,
)
)
def choose_action(self, state):
self.check_state_exist(state)
if np.random.uniform() < self.epsilon:
action = np.random.choice(self.actions)
else:
state_action = self.q_table.loc[state, :]
state_action = state_action.reindex(np.random.permutation(state_action.index))
action = state_action.idxmax()
return action
def learn(self, s, a, r, s_):
self.check_state_exist(s_)
q_predict = self.q_table.loc[s, a]
if s_ != 'terminal':
q_target = r + self.gamma * self.q_table.loc[s_, :].max()
else:
q_target = r
self.q_table.loc[s, a] += self.lr * (q_target - q_predict)
效果展示
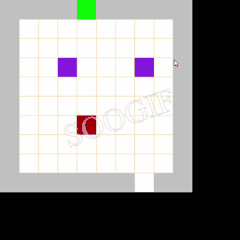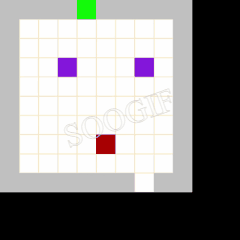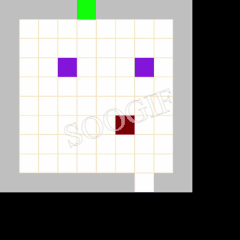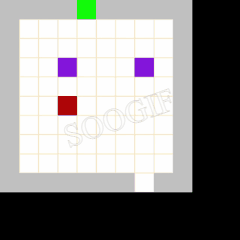
; 总结
结合上一篇游戏界面制作,我们就介绍完了Q_learning算法制作通关类游戏AI的基本过程。将上一篇中的game.py以及本文中的main.py和q_learning.py相结合,能完整实现整个项目。各位读者可以实操一下,完整代码我已上传至github:https://github.com/TommyGong08/RL_shoot_game。
下文我将带领大家用DQN算法是继续完善我们的小游戏。
参考资料
强化学习学习总结(二)——QLearning算法更新和思维决策
Original: https://blog.csdn.net/weixin_43794327/article/details/119551338
Author: TommyGong08
Title: 【强化学习】手把手教你实现游戏通关AI(2)——Q-Learning
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/782699/
转载文章受原作者版权保护。转载请注明原作者出处!