

2、偏差图
偏差图是单个特征中所有值与特定值之间的关系图,它反映的是所有值偏离特定值的距离。典型的偏差图有:发散型条形图,面积图,…

我们什么时候需要偏差图呢?
1.数据探索&数据解读
探索某一特征的分布,探索该特征偏离某个特定值(均值,方差等)的程度。
2.结果展示&报告呈现:
直观地展示某个特征的分布特征,快速得出结论。
; 2.1 发散条形图(Diverging Bars)
如果你想根据单个指标查看项目的变化情况,并可视化此差异的顺序和数量,那么发散条形图是一个很好的工具。它有助于快速区分数据中的组的性能,并且非常直观,可以立即传达这一点。
- 横坐标:里程
- 纵坐标:各品牌汽车
- 颜色:
我们的目标就是绘制出这张图,并且利用现有数据解读图内信息。
1、导入需要的绘图库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
2、先来认识一下绘制发散性条形图的函数
plt.hlines()
plt.hlines()表示水平的条形图,类似的还有垂直的条形图plt.vlines()
参数说明:
y:y轴索引
xmin:每行的开头
xmax:每行的结尾
colors:颜色,默认为”k”(黑色)
linestyles:线的类型,可选择{‘solid’,’dashed’,’dashot’,’dotted’}
label:标签,默认为空
*linewidth:线的宽度
*alpha:色彩饱和度
绘制一个超级简单的条形图
x = np.random.rand(10)
x
plt.hlines(y=range(10),xmin=0,xmax=x);

与我们的目标图像相比,有什么区别吗?
- 目标图像时从大到小顺序排序的
- 目标图像的线比较宽
- 目标图像是基于某个特定值将数据分成两部分,并用不同的颜色表示
(1)让图像顺序排列
使用sorted()函数,或者使用.sort()方法
a = sorted(x,reverse=True)
x.sort()
(2)设置plt.hlines(linewidth=5)用于将图像的线变宽点。
(3)让图像基于均值分成两部分
方法:使用 x = x-x.mean()即可让图像的均值变为0
(4)让两部分显示不同的颜色
直接使用color=[‘green’,’red]可以吗?答案是不可以。
我们需要根据数据建立与数据长度相同的颜色列表(使用for循环/列表推导式)
colors = []
for i in x:
if i<0:
colors.append('red')
else:
colors.append('green')
colors = ['red' if i<0 else 'green' for i in x]
(5)让颜色变浅一点
参数alpha是颜色饱和度,默认为1,alpha的取值范围是[0,1],越接近1颜色越饱和,也就是颜色越鲜艳。
所以我们可以让alpha=0.5
到此为止,绘制发散型条形图的基本知识就差不多全部讲完了,下面我们使用完整的数据来实现我们的目标图像。
df = pd.read_csv("E:\old_computer\考研资料\项目准备\画图\菜菜和菊安酱的Python可视化50图{逆人行}\第一部分\第1章 课程介绍 + 可视化模块安装\课时 2 数据集\data\data\mtcars.csv")
df.head()
df.shape
df.info()
sum(df.cars!=df.carname)
df.columns
x= df.loc[:,'mpg']
x.shape
df['mpg_z'] = (x-x.mean())/x.std()
df['mpg_z'].values
colors=[]
for i in df["mpg_z"]:
if i <0:
colors.append("red")
else:
colors.append("green")
df["colors"] = ["red" if i <0 else "green" for i in df["mpg_z"]]
df.sort_values('mpg_z',inplace=True)
df.reset_index(drop=True,inplace=True)
plt.figure(figsize=(14,10),dpi=80)
plt.hlines(y=df.cars,xmin=0,xmax=df.mpg_z,color=df.colors,alpha=0.4,linewidth=5);
plt.ylabel('$model$',fontsize=15)
plt.xlabel('$mileage$',fontsize=15)
plt.yticks(fontsize=12)
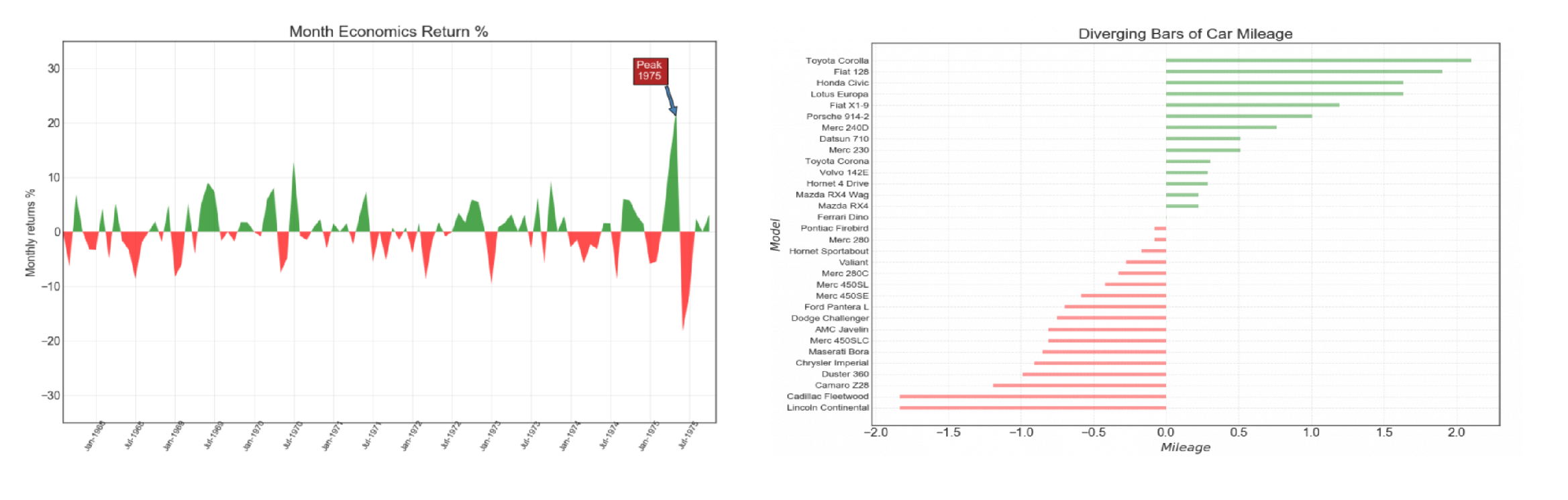
plt.title('Diverging Bars of Car Mileage',fontdict={'size':20,'color':'k'})
plt.grid(linestyle='-.',alpha=0.5)

图像解读
(1)相同油耗内里程数最小的是林肯大陆 (Lincoln Continental)
这款车一开始是福特汽车公司总裁Edsel Ford的私人车辆
从1939年至今已经更新十代
林肯系列车走的是高端路线,油耗里程已经不再是它关注的重点
(2)位于均值线上的是法拉利迪诺(Ferrari Dino)
“Dino”品牌的诞生是为了推出一款价格较低,”价格合理”的跑车
“Dino”这个名字是为了纪念这位创始人已故的儿子Alfredo”Dino”Ferrari,他因设计用于汽车的V6发动机而受到赞誉
(3)油耗里程数最大的是丰田卡罗拉(Toyota Corolla)
这是丰田生产的一系列超小型和紧凑型轿车
从1966年至今,已经更新十二代
卡罗拉于1966年推出,是1974年全球最畅销的汽车,自那时起成为全球最畅销的汽车之一
(4)从图形上来看,这32款汽车根据相同油耗内的里程数被分成了两组
一组高于平均值,从图中可以看出基本上都是一些民用车(除了那款保时捷914之外)
一组低于平均值,基本上都是高端车,要不就是跑车,要不就是商用车
(5)大胆猜想:发散型条形图完成了聚类功能
用kmeans聚类验证发散型条形图聚类效果
df["label"]=[1 if i=="red" else 0 for i in df.colors]
df.shape
from sklearn.cluster import KMeans
df1 = pd.read_csv("E:\old_computer\考研资料\项目准备\画图\菜菜和菊安酱的Python可视化50图{逆人行}\第一部分\第1章 课程介绍 + 可视化模块安装\课时 2 数据集\data\data\mtcars.csv")
data_x = df1.mpg.values.reshape(-1,1)
data_x.shape
cluster = KMeans(n_clusters=2,random_state=420).fit(data_x)
cluster.labels_
df1["label"]=cluster.labels_
df1["label"].shape
df1.sort_values('mpg',inplace=True)
df1.reset_index(inplace=True)
sum(df1["label"]==df["label"])
score = sum(df1["label"]==df["label"])/df1["label"].shape[0]
score
df[df["label"]!=df1["label"]]
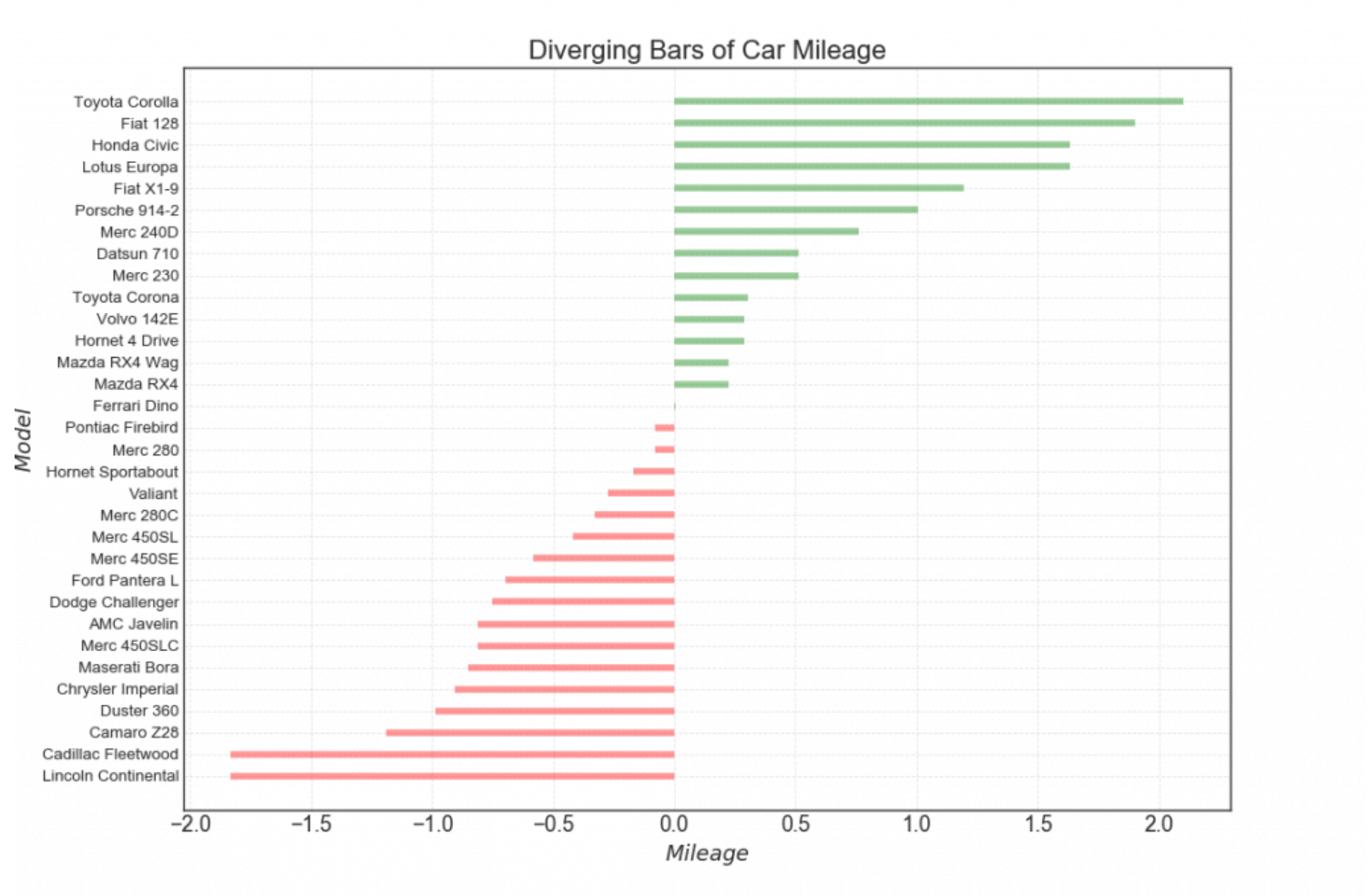
2.2 发散型文本(Diverging Texts)
分散的文本类似于发散型条形图,如果你想以一种漂亮和可呈现的方式来希纳是图表中每个项目的价值,那么它是一个比较合适的方式。
这和我们上面讲到的发散型条形图很相似,唯一不同的地方就是每个条形图上多了带颜色的文字
1、导入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
2、来认识一下绘制文本的函数
plt.text()
参数说明:
- x,y:放置文本的位置。默认情况下,就是数据坐标
- s:要显示的文本内容
- fontdict:用于覆盖默认文本属性的字典。fontdict的默认值是None,默认值由rc参数决定
x = np.random.rand(1)
y = np.random.rand(1)
plt.figure(figsize=(8,4))
plt.text(x=x,y=y,s="text"
,fontdict={'size':20,"color":"b"});
plt.figure(figsize=(8,4))
for i in range(10):
x = np.random.rand(1)
y = np.random.rand(1)
plt.text(x,y,"text",fontdict={'size':16,"color":"b"});


绘制目标图像
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
x = df.loc[:, ['mpg']]
df['mpg_z'] = (x - x.mean())/x.std()
df['colors'] = ['red' if x < 0 else 'green' for x in df['mpg_z']]
df.sort_values('mpg_z', inplace=True)
df.reset_index(inplace=True,drop=True)
round(df.mpg_z.values[0],2)
plt.figure(figsize=(12,10),dpi=65)
plt.hlines(y=df.cars,xmin=0,xmax=df.mpg_z)
for i in range(df.shape[0]):
x = df.mpg_z[i]
y = df.index[i]
s = str(round(df.mpg_z[i],2))
plt.text(x,y,s,color=df.colors[i])

这个基础图形有3个问题:
- 文本信息都显示在线的上方,而我们需要的是显示在线条正对着的位置(中间)
- 红色文本显示在线条的右边,我们需要的是横坐标小于0的显示在左边,大于0的显示在右边
- 文本字体有点小
plt.figure(figsize=(14,10),dpi=65)
plt.hlines(y=df.cars,xmin=0,xmax=df.mpg_z)
for i in range(df.shape[0]):
x = df.mpg_z[i]
y = df.index[i]
s = str(round(df.mpg_z[i],2))
plt.text(x,y,s
,fontdict={'size':12,'color':df.colors[i]}
,horizontalalignment='right' if x<0 else 'left'
,verticalalignment='center'
)
plt.yticks(fontsize=12)
plt.title('Diverging text Bars of Car Mileage', fontdict={'size':20})
plt.xlim(-2.5,2.5)
plt.grid(linestyle='-.',alpha=0.5);

这里需要说明的是:
- 1、水平对其参数,用来类似列表推导式的代码,不同的是这里只需要单个值不需要最后形成列表(所以在最外层没有套上列表符号[])
- 2、另外:left和right这两个对其方式也很容易混淆
- 3、以右对齐为例来说明:
首先我们需要知道的是文本放置的位置其实就是线条的末端,所谓的右对齐就是要求文本的最右端要与这个位置对其。
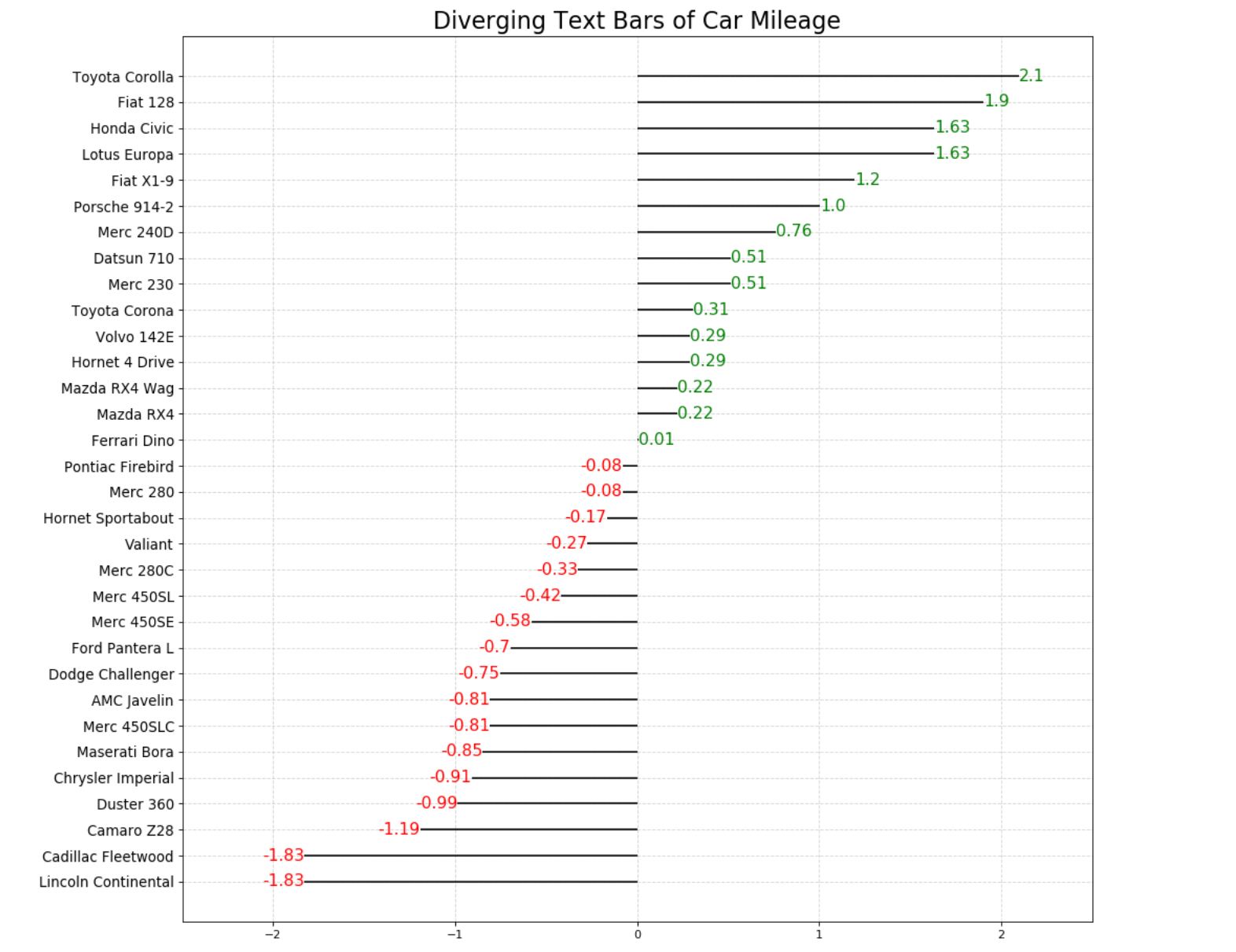
发散型包点图
发散型包点图与发散型条形图,发散型文本都非常相似,可以说这个发散型包点图包含了条形图和文本图的两部分信息。
- 横坐标:里程
- 纵坐标:汽车名称
- 颜色:大于0显示绿色,小于0显示红色
1、导入需要的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
2、认识绘制包点图的函数
前面我们有说过,包点图其实与发散条形图和发散文本图非常相似,此外包点图也是散点图的一种变形。
从我们需要绘制的目标函数可以看出来,包点图中包含了散点和文本,所以,我们绘制的包点图就是由散点图和文本图两部分组成的。
plt.scatter
重要参数:
x,y:绘制散点图的数据
s:散点的大小
c:散点的颜色
marker:散点的形状(默认是圆形)
plt.text()
重要参数:
x,y:文本放置的位置坐标
s:文本的内容
horizontalalignment:水平对齐控制参数(center/left/right三种可选)
verticalalignment:垂直对齐控制参数(’top’, ‘bottom’, ‘center’, ‘baseline’, ‘center_baseline’五种可选)
import numpy as np
data = np.random.randn(10)
data
import matplotlib.pyplot as plt
plt.scatter(range(10),data,s=500,c='r',alpha=0.3);

plt.figure(figsize=(8,5))
plt.scatter(range(10),data,s=500,c="b",alpha=0.5)
for x, y in zip(range(10),data):
plt.text(x,y,round(y,1),fontdict={'color':'w','size':10},
horizontalalignment='center',
verticalalignment='center'
);

#认识绘图数据
import pandas as pd
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv")
#提取出目标特征
x = df.loc[:,['mpg']] #对于提取单列数据,如果在列名外加[]就会生成dataframe格式的数据,如果不加则生成series
#对数据进行z-score标准化处理,将生成的标准化数据增加到df中
df['mpg_z'] = (x - x.mean())/x.std()
#生成颜色标签
df['colors'] = ['green' if x>0 else 'red' for x in df['mpg_z']]
#根据标准化之后的数据,对整个数据集进行排序
df.sort_values('mpg_z',inplace=True)
#重置整个数据集的索引
#df.reset_index(inplace=True)
df.index = range(df.shape[0])
#绘制发散型包点图
plt.figure(figsize=(12,15),dpi=60)
#绘制基础散点图
plt.scatter(df.mpg_z,df.index,s=500,alpha=0.6,color=df.colors)
#添加文本
for x, y, text in zip(df.mpg_z,df.index,df.mpg_z):
plt.text(x,y,round(text,1),
fontdict={"color":'w',"size":10}
,horizontalalignment='center'
,verticalalignment='center')
#添加装饰
plt.title('Diverging Dotplot of Car Mileage',fontsize=20)
plt.xlabel('$mileage$',fontsize=12)
plt.yticks(df.index,df.cars,fontsize=12)
plt.xlim(-2.5,2.5)
plt.grid(linestyle='-.',alpha=0.3)
发散型包点图到这里基本上就已经完成了!
面积图
面积图就是通过轴和线之间的区域进行着色形成的一种图形,它不仅可以强调峰值和低谷,还可以强调高点和低点的持续时间,持续时间越长,面积就越大。

- 横坐标:时间(月份)
- 纵坐标:月度收益率
- 颜色:>0显示绿色,
1、导入需要的绘图库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
2、认识绘制面积图的函数
plt.fill_between
函数功能:填充两条水平曲线之间的区域
重要参数说明:
x:定义曲线的x坐标
y1:定义第一条曲线的y坐标
y2:定义第二条曲线的y坐标
where:定义被填充的区域
interpolate:控制交叉点位置的填充(仅在设定where并且两条曲线相交时起作用)
3、简单绘图
x = np.random.randn(1000)
x.sort()
y1 = np.sin(x)
y2 = np.cos(x)
plt.figure(figsize=(8,5),dpi=80)
plt.plot(x,y1)
plt.plot(x,y2);
plt.figure(figsize=(8,5),dpi=80)
plt.fill_between(x,y1,y2,color="g",alpha=0.5);


从图中可以发现:两条曲线之间的区域全部被填充为一种颜色。我们需要在增加一定的难度:在y1>y2时,填充为红色,否则,填充为蓝色。
plt.fill_between(x,y1,y2,where=y1>y2,color='r',alpha=0.5,interpolate=True)
plt.fill_between(x,y1,y2,where=y1<y2,color='b',alpha=0.5,interpolate=True);

4、绘制目标图像
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv",parse_dates=['date'])
df1 = pd.read_csv("https://github.com/selva86/datasets/raw/master/economics.csv")
df1["date1"] = pd.to_datetime(df1.date)
import datetime
df1["date2"]= df1["date"].apply(lambda x:datetime.datetime.strptime(x,"%Y-%m-%d"))
准备绘图所需数据集:绘制目标图像,我们需要的是月度收益率,纵观所有特征,与月度收益率相关的特征是个人储蓄率(psavert),而且数据比较对,因此在这里选取前100来绘图。
df.psavert.values
plt.plot(df.psavert.values);

df.psavert.diff()
income = df.psavert.diff().fillna(0)
re = (income/df.psavert.shift(1)).fillna(0)*100
plt.figure(figsize=(14,8),dpi=60)
plt.fill_between(range(df.shape[0]),re,0,where=re>0,color='g',interpolate=True, alpha=0.7)
plt.fill_between(range(df.shape[0]),re,0,where=re0,color='r',interpolate=True, alpha=0.7);

y = df.date.dt.year
m = df.date.dt.month_name()
[*zip(y,m)]
str(m[1])[:3].upper()
[str(m)[:3].upper()+'-'+str(y) for y,m in zip(y,m)][::6]
plt.figure(figsize=(14,8),dpi=60)
plt.fill_between(range(df.shape[0]),re,0,where=re>0,color='g',interpolate=True, alpha=0.7)
plt.fill_between(range(df.shape[0]),re,0,where=re0,color='r',interpolate=True, alpha=0.7)
xtickslabel = [str(m)[:3].upper()+'-'+str(y) for y,m in zip(y,m)][::6]
plt.xticks(range(df.shape[0])[::6],xtickslabel,rotation=90,fontsize=12)
plt.title('Month Economics Return %',fontsize=20)
plt.ylabel('Monthly returns %',fontsize=15)
plt.ylim(-35,35)
plt.xlim(1,100)
plt.grid(alpha=.3);

Original: https://blog.csdn.net/qq_48314528/article/details/120578777
Author: Litra LIN
Title: matplotlib绘制偏差图
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/768159/
转载文章受原作者版权保护。转载请注明原作者出处!