

目录
plot.bar(“指定为x轴的columns”,[“指定为y轴的columns1″,”指定为y轴的columns2”,···])
e.g.对比每层楼的每月销量情况
Dataframe的一列\Series.plot.bar()
plot.bar(“指定为x轴的columns”,[“指定为y轴的columns1″,”指定为y轴的columns2”,···],stacked=True)
plt.subplot(子图的行数,子图的列数,子图的序号)
绘制图像(叠加图)
matplotlib.pyplot模块+pandas模块
1. 百分比堆积柱状图(叠加图)
2. 簇形柱状图(叠加图)
3. 并列子图(叠加图)
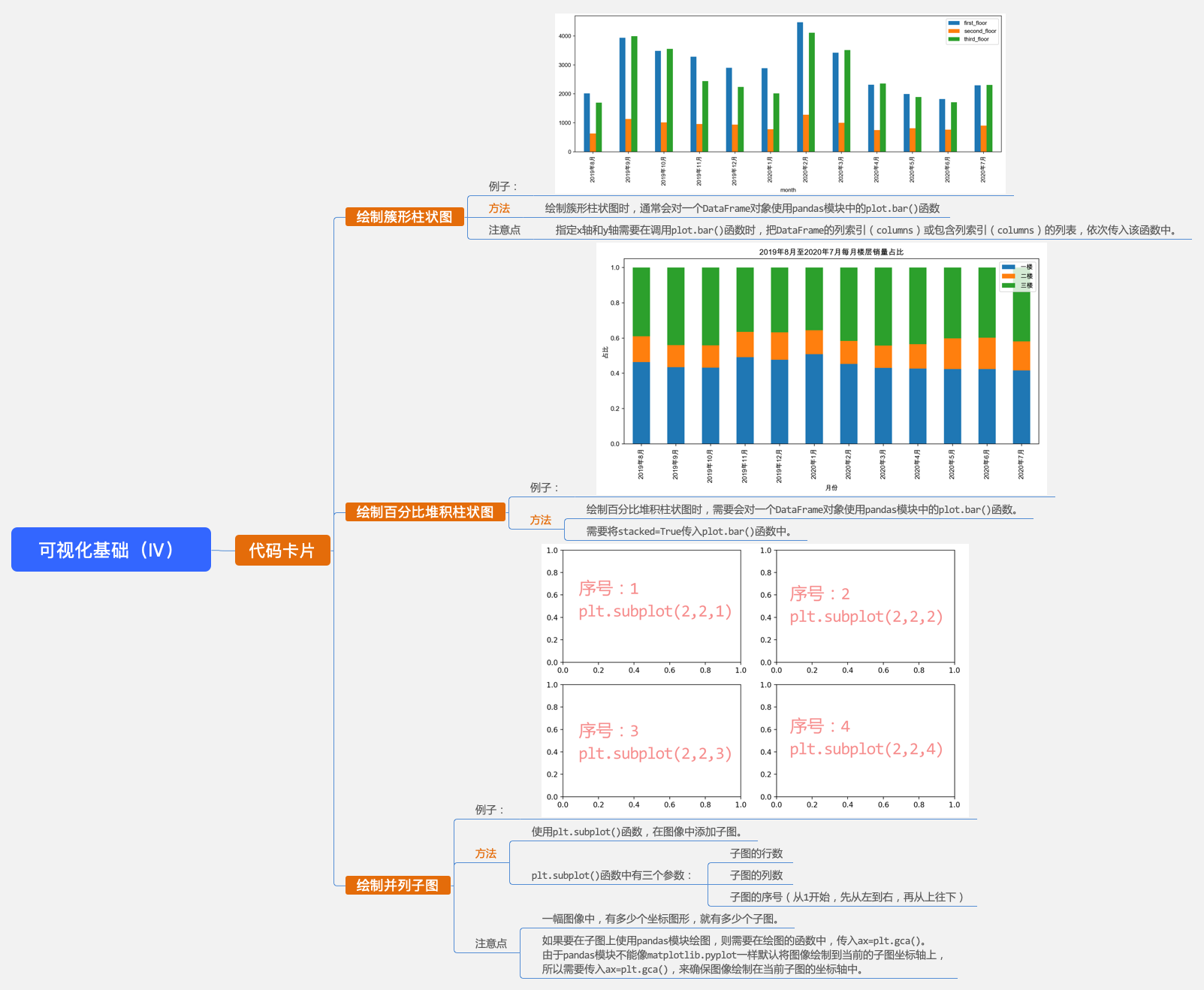

一般情况下, 簇形柱状图和 百分比堆积柱状图这两种图像需要展示的数据往往是由多个分类组成,也就是要用到一个DataFrame或多个Series中的数据。
在使用matplotlib.pyplot绘制图像的同时,搭配pandas模块。
pandas模块本身具有绘图功能,此功能依赖于matplotlib模块,可简化从DataFrame和Series生成可视化的过程。
簇形柱状图
用来比较某一维度上的多个数据。
e.g.每一层楼的每月销量,i.e.同一维度上的多个数据。
对一个DataFrame对象,使用 pandas模块中的 plot.bar()函数。
「不指定x轴和y轴数据」
plot.bar()
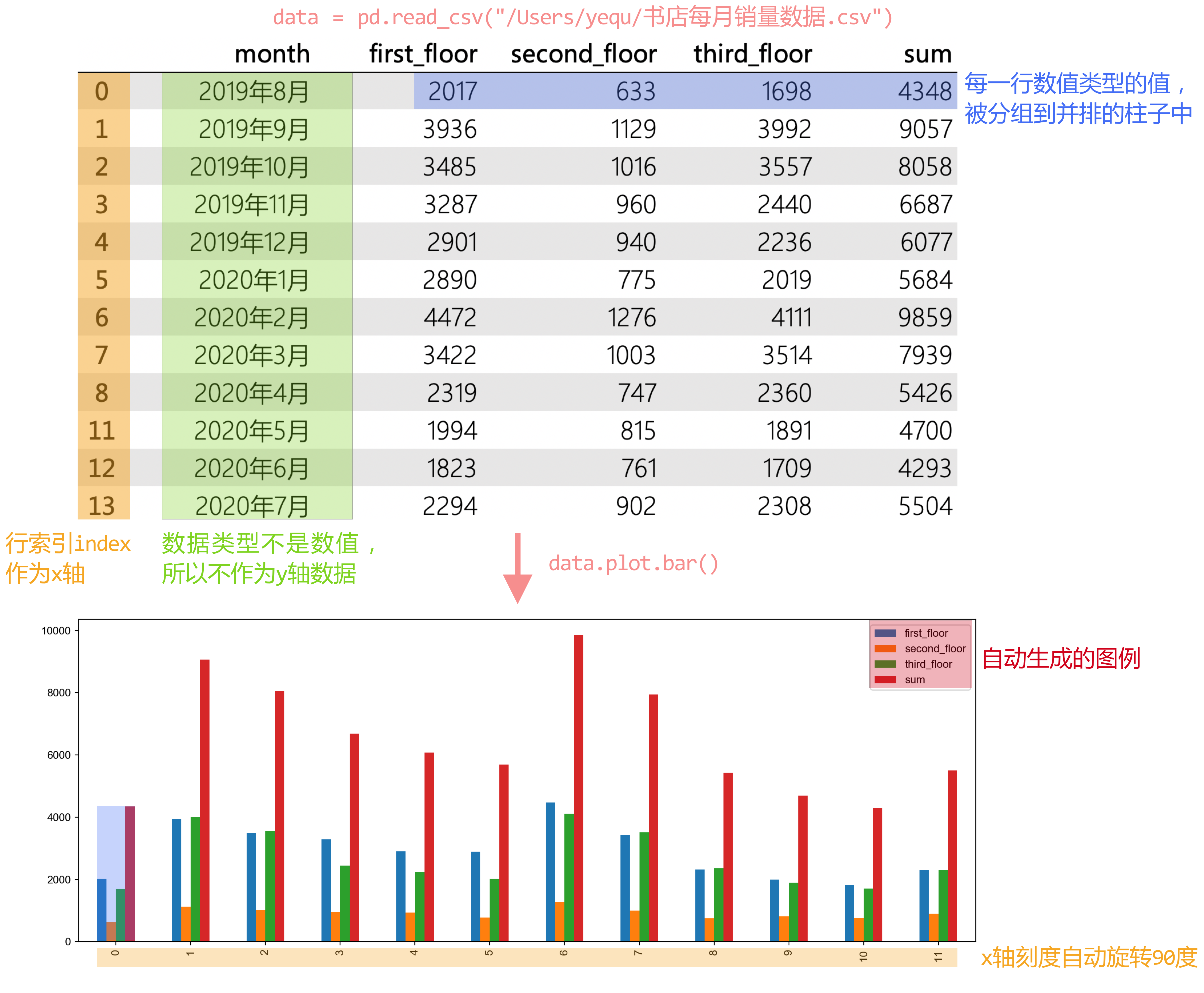
对一个 DataFrame对象使用函数时, 行索引index会作为 x轴, 每一行数值类型的值会被分组到并排的柱子中作为 y轴。
同时,会根据x轴和y轴的数据,自动生成x轴标题和图例,以及x轴刻度会自动旋转90度。
「不指定x轴和y轴数据」
plot.bar(" 指定为x轴的columns ",[" 指定为y轴的columns1 "," 指定为y轴的columns2 ", ··· ])
调用plot.bar()函数时,把DataFrame的列索引(columns)\包含列索引(columns)的列表,依次传入该函数中,指定x轴和y轴。
e.g.对比每层楼的每月销量情况
做完绘图准备工作后,对data变量使用 plot.bar()函数,并把列索引”month”和列索引列表[“first_floor”,”second_floor”,”third_floor”]依次传入到该函数中,指定x轴和y轴。
·列索引”month”被自动设置为x轴的标题
·用于指定y轴的列索引们会自动生成对应的图例
·x轴刻度会自动旋转90度
一个DataFrame对象
读取文件后,把生成的 DataFrame对象赋值给了 变量data。表示将对 data进行操作。

plot.bar()函数
x轴数据
传入 列索引”month”,指定 x轴数据。
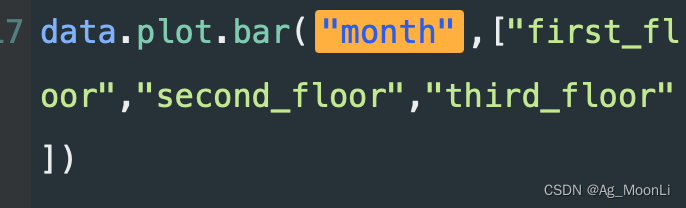
y轴数据
一个 列表,包含对应的多列索引(columns) “first_floor”,”second_floor”,”third_floor”指定这三列为 y轴数据。
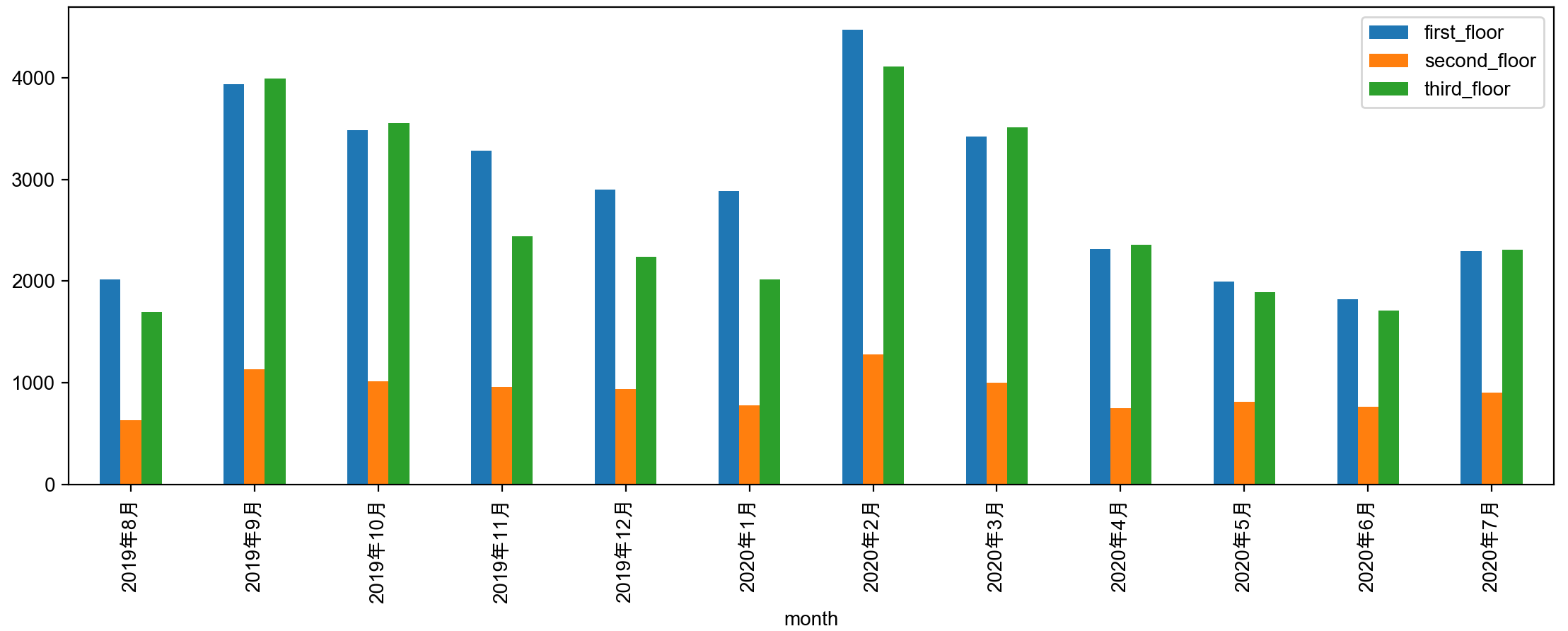
根据下图的数据,以”month”为x轴,绘制对比”first_floor”、”second_floor”和”third_floor”销量的簇形柱状图。

导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
使用pd.read_csv()函数 读取路径为 "/Users/yequ/书店每月销量数据.csv" 的CSV文件,并赋值给变量data
data = pd.read_csv("/Users/yequ/书店每月销量数据.csv")
通过给 plt.rcParams["font.sans-serif"] 赋值 将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
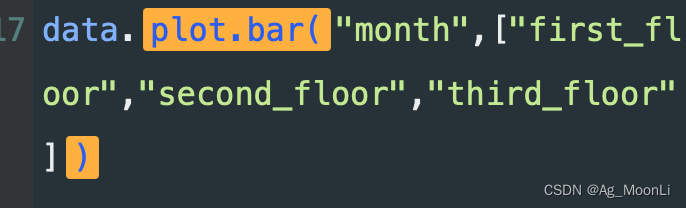
使用plot.bar()函数,以"month"为x轴
["first_floor","second_floor","third_floor"]为y轴
绘制簇形柱状图
data.plot.bar("month",["first_floor","second_floor","third_floor"])
使用plt.show()函数显示图像
plt.show()
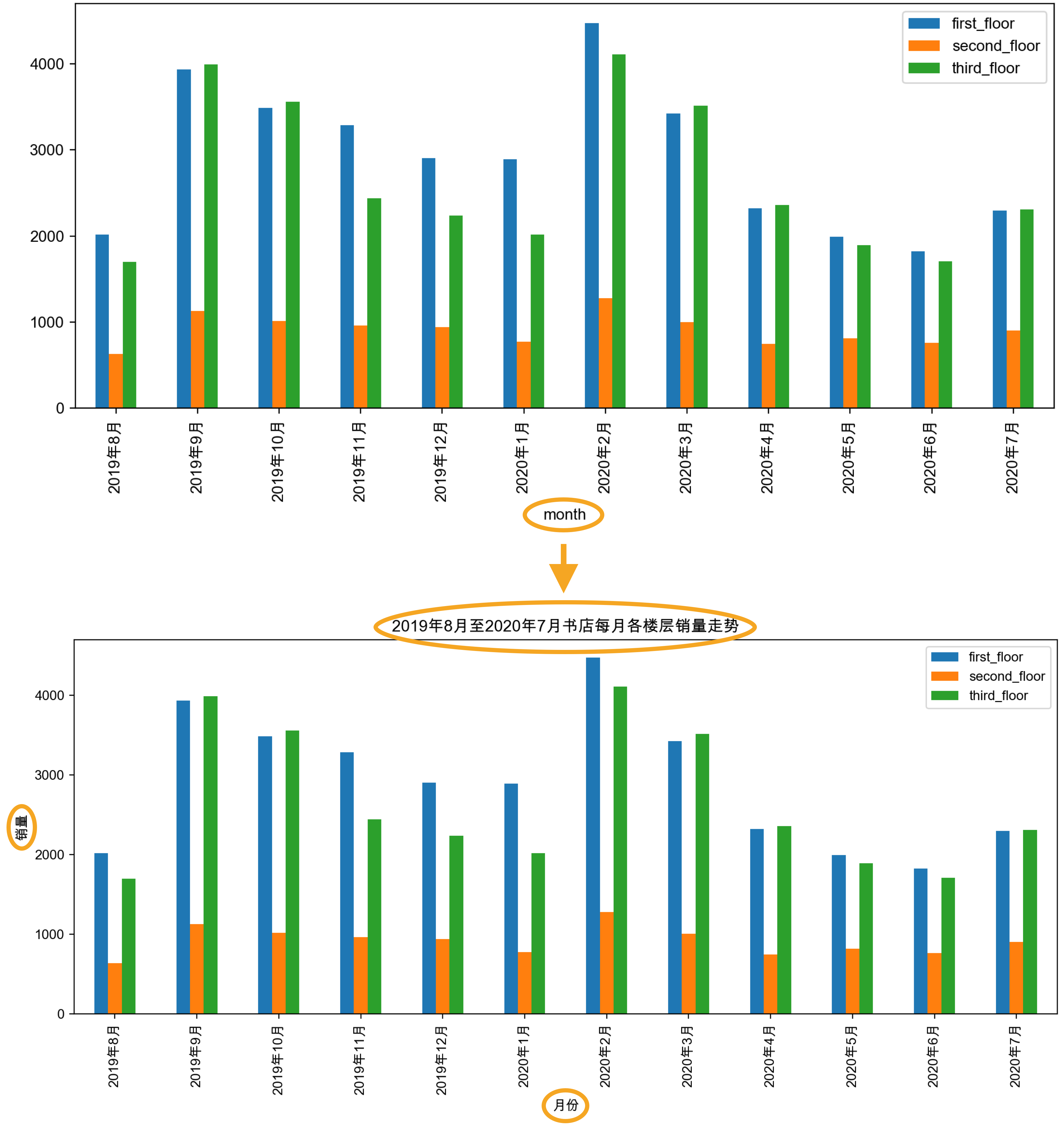
通过 plt.xlabel()、 plt.ylabel()和 plt.title()函数设置 坐标轴标题和 图像标题:
使用plt.xlabel()函数,将x轴标题设置为"月份"
plt.xlabel("月份")
使用plt.ylabel()函数,将y轴标题设置为"销量"
plt.ylabel("销量")
使用plt.title()函数,将图表标题设置为"2019年8月至2020年7月书店每月各楼层销量走势"
plt.title("2019年8月至2020年7月书店每月各楼层销量走势")
「Dataframe的一列\Series」-绘制柱状图
Dataframe的一列\Series . plot.bar()
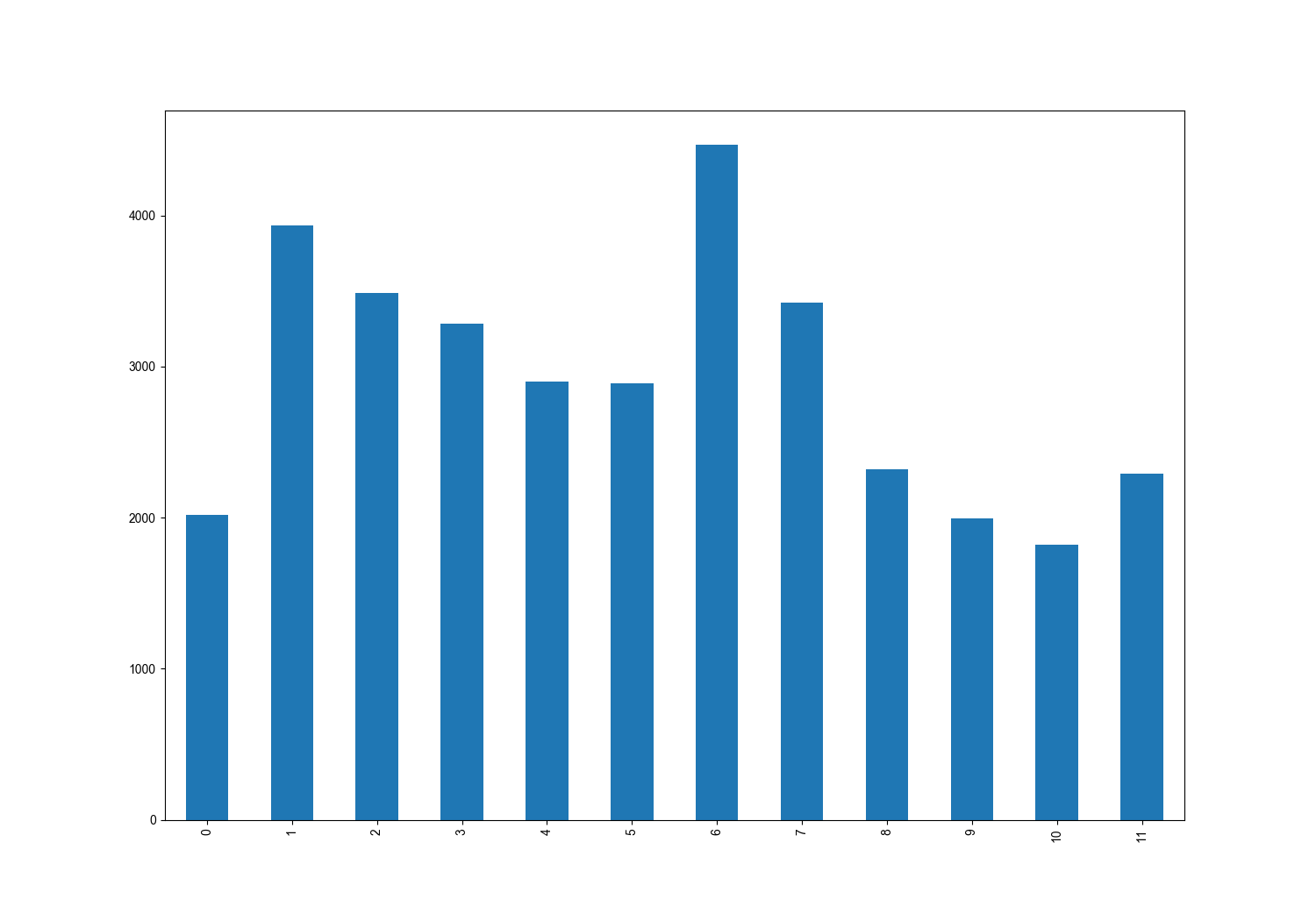
直接对Dataframe的一列\Series,i.e.只有一列数据,使用 plot.bar(),直接绘制出普通的柱状图。该函数自动将index作为x轴的值,values作为y轴的值。
直接对"first_floor"列,使用plot.bar()函数,绘制柱状图
data["first_floor"].plot.bar()
百分比堆积柱状图
显示单个项目与整体之间的关系,比较各个类别的每个数值所占总数值的比例。
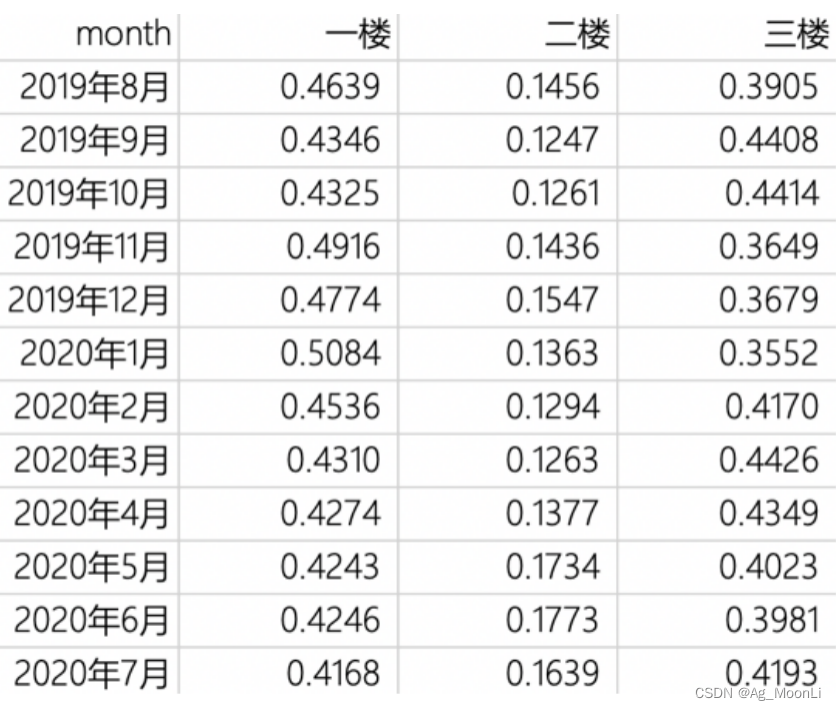
e.g.每层楼的每月销量占当月总销量的比例
Step1 (x轴一般为类别型数据,y轴为数值型)求和得到每个类别的总和数值,并计算占比;
plot.bar(" 指定为x轴的columns ",[" 指定为y轴的columns1 "," 指定为y轴的columns2 ", ··· ], stacked=True )
Step2 将pandas模块中的簇形柱状图绘制函数 plot.bar()函数的参数 stacked设置为True;
stacked=True会使DataFrame中每一行的值垂直堆叠放置,形成堆积柱状图
Step3 通过 plt.xlabel()、 plt.ylabel()和 plt.title()函数设置坐标轴标题和图像标题:
导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
使用pd.read_csv()函数 读取路径为 "/Users/yequ/书店每月销量数据百分比.csv" 的CSV文件,并赋值给变量data
data = pd.read_csv("/Users/yequ/书店每月销量数据百分比.csv")
通过给 plt.rcParams["font.sans-serif"] 赋值 将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
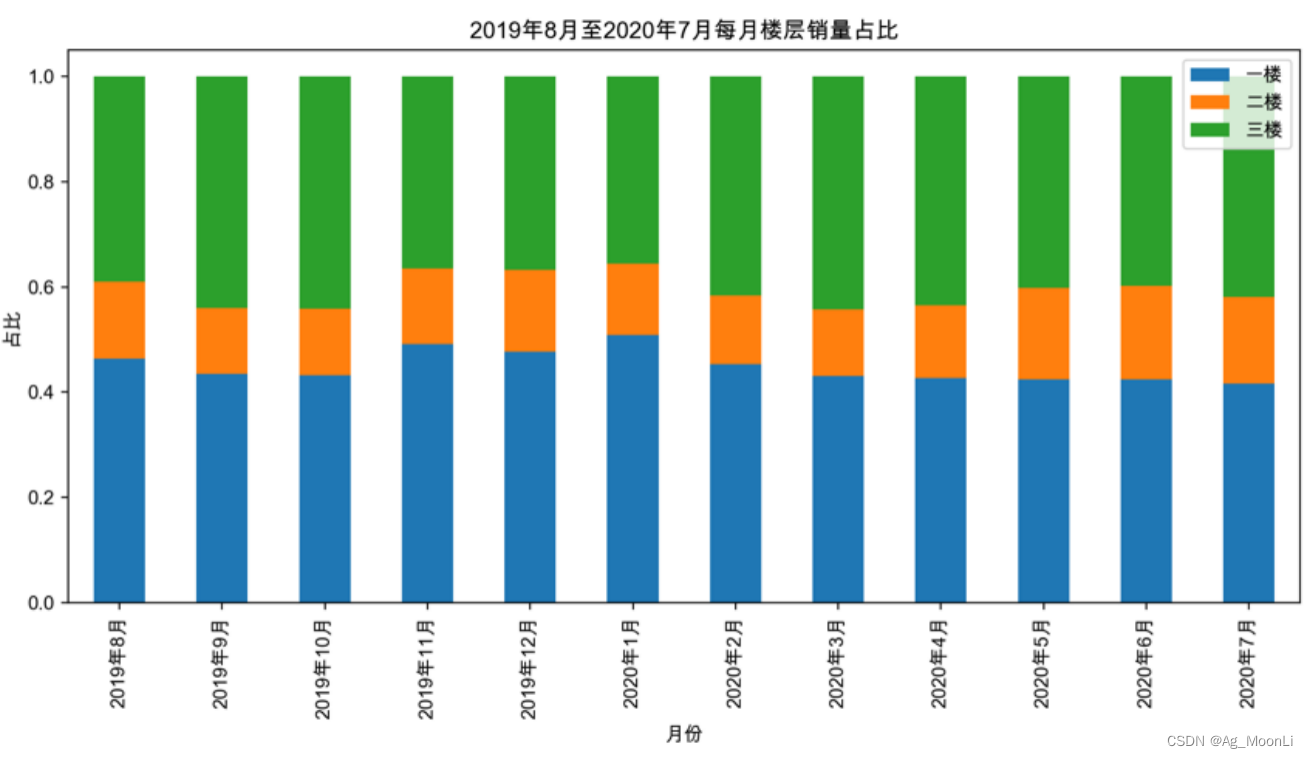
使用plot.bar()函数 根据data变量,以"month"为x轴,["一楼","二楼","三楼"]为y轴 绘制百分比堆积柱状图
data.plot.bar("month",["一楼","二楼","三楼"],stacked=True)
使用plt.xlabel()函数,将x轴标题设置为"月份"
plt.xlabel("月份")
使用plt.ylabel()函数,将y轴标题设置为"占比"
plt.ylabel("占比")
使用plt.title()函数,将图表标题设置为"2019年8月至2020年7月书店每月销量占比"
plt.title("2019年8月至2020年7月书店每月销量占比")
使用plt.show()函数显示图像
plt.show()
并列子图
matplotlib的画布(Figure)对象至少包含一个子图,也就是一个 坐标图形(Axes)对象。
一幅图像中,有多少个坐标图形,就有多少个子图。
通过matplotlib.pyplot模块在子图上进行绘制
plt.subplot(子图的行数,子图的列数,子图的序号 )
在matplotlib.pyplot模块中,绘制子图最常用 plt.subplot()函数。
plt.subplot()函数中有以下三个参数:
1. 子图的行数
2. 子图的列数
3. 子图的序号
前两个参数决定了图表的整个绘图区域会被分成几行几列。
子图的序号从1开始,按照从左到右,从上到下的顺序排列,最后一个参数指定了创建的子图对象所在的区域。
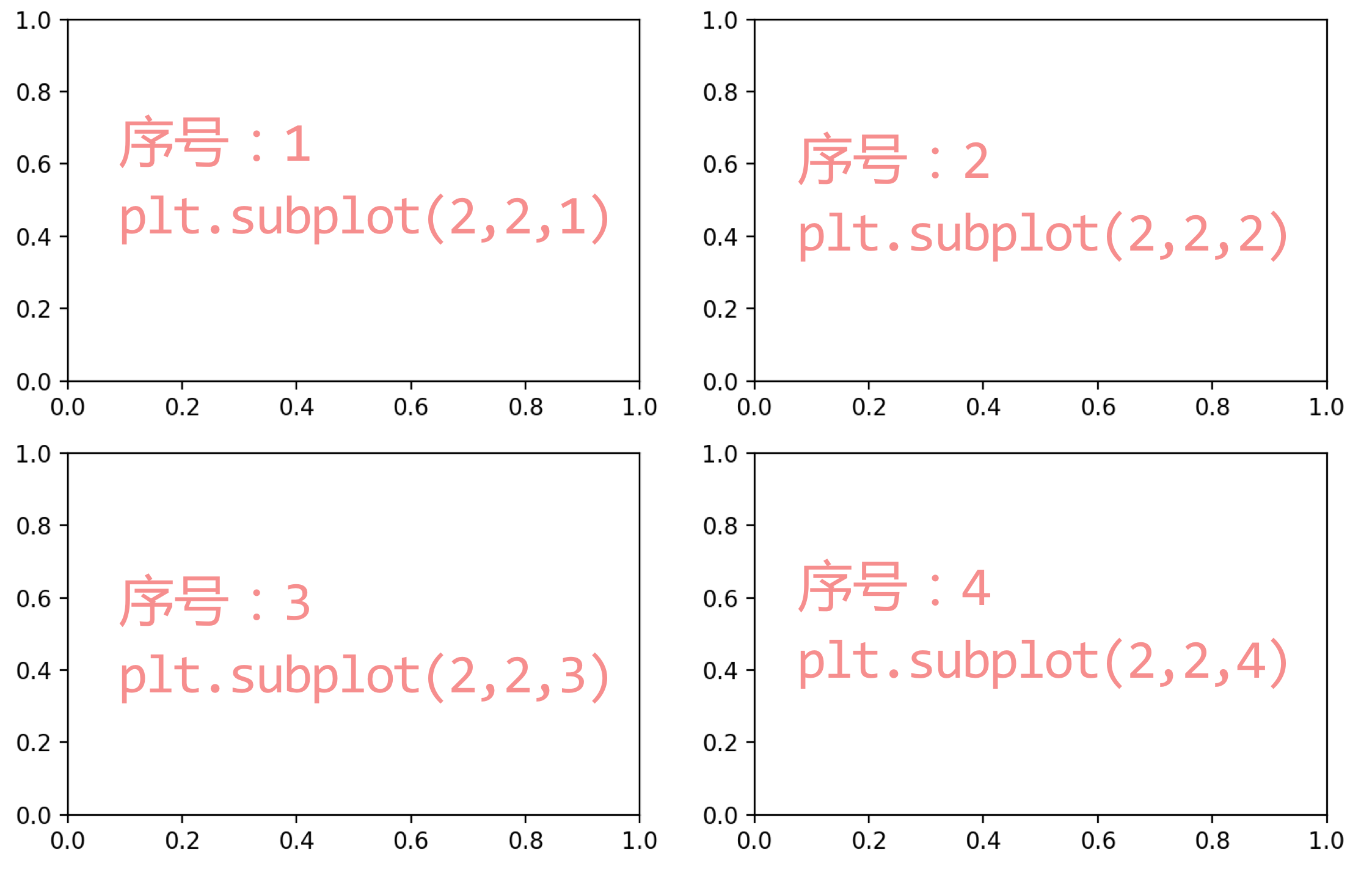
e.g. plt.subplot(2,2,1)将图像规则地划分为一个2×2(两行两列)的子图,并选择其中序号为1的子图。
「子图的划分不规则」,如图:
可以先将整个图像按照2×2划分,上面两个子图分别是 (2, 2, 1) 和 (2, 2, 2)。
第三个图占用了 (2, 2, 3) 和 (2, 2, 4),需要对其重新划分, 将整个图像按照2×1划分。
创建一个2×2的图表框架后,准备在每个子图里进行绘图。
在对应的 plt.subplot()函数下,接上绘图的代码即可,matplotlib.pyplot会自动选择当前状态下的子图进行绘制。
使用plt.subplot()函数添加4个子图 两行两列
选择序号为1子图
plt.subplot(2,2,1)
使用plt.plot()函数绘制折线图
plt.plot(data["month"],data["sum"])
选择序号为2子图
plt.subplot(2,2,2)
使用plt.scatter()函数
以df["ads_fee"]为x轴的值和df["sales"]为y轴的值,绘制散点图
plt.scatter(df["ads_fee"],df["sales"])
选择序号为3的子图
plt.subplot(2,2,3)
选择序号为4子图
plt.subplot(2,2,4)
避免坐标轴遮挡-旋转x轴刻度
运行出来的图像,序号为1的子图上的折线图,横坐标刻度出现了重叠遮挡的情况。
plt.xticks <span>(rotation=</span><span>度数</span><span>)</span>
使用 plt.xticks()函数,将度数作为整数赋值给 rotation 参数,传入该函数中,来旋转x轴的刻度。
e.g.将横坐标的刻度旋转90度
使用plt.xticks()函数旋转x轴的刻度至90度
plt.xticks(rotation=90)
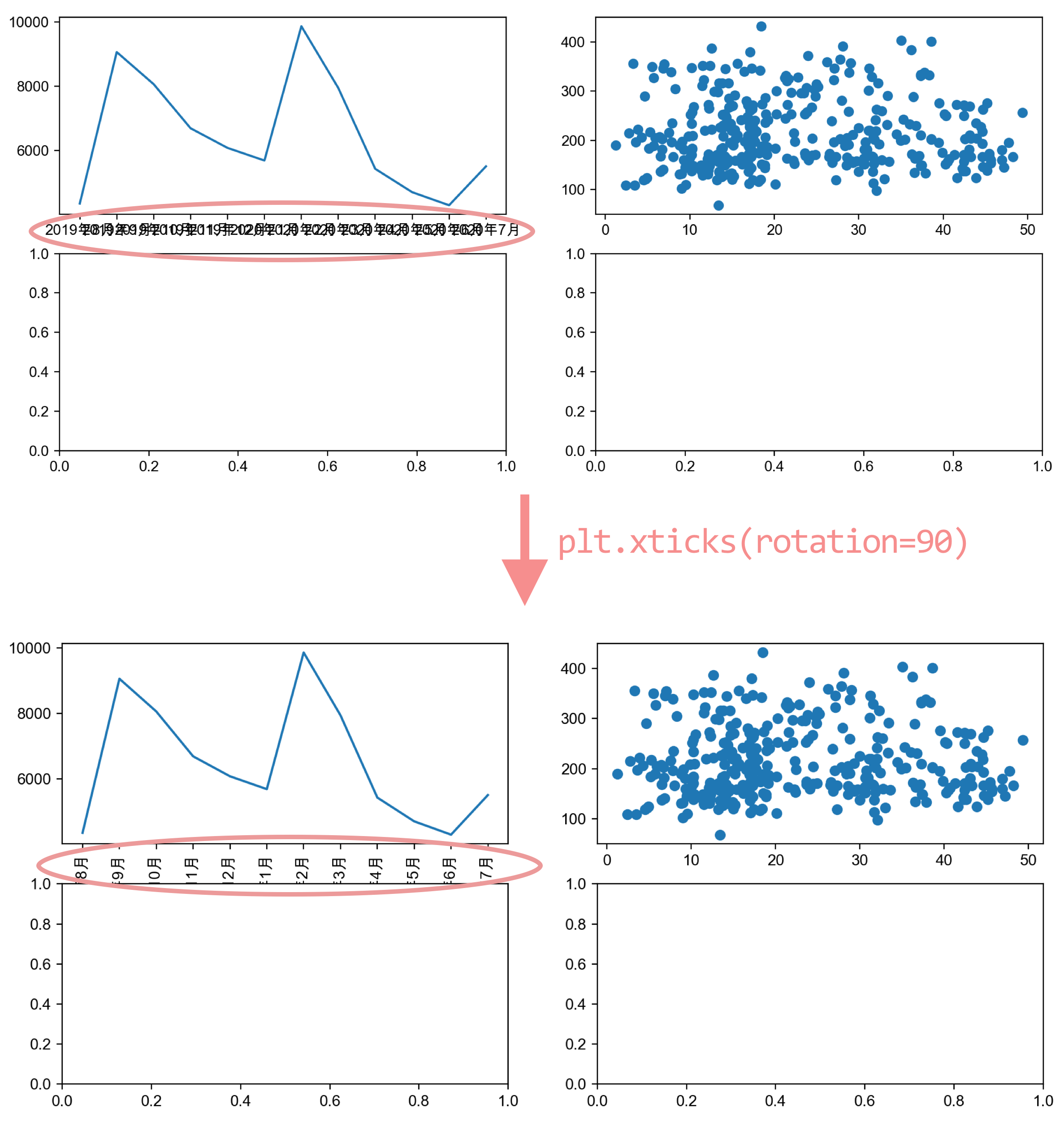
避免坐标轴遮挡-调整子图布局
旋转后,图像序号为1的x轴刻度又被序号为3的图像遮挡了。
plt.tight_layout()
在用plt.show()函数展示图像前,使用 plt.tight_layout()函数,来调整子图的布局,避免重叠
使用plt.tight_layout()函数来调整子图布局
plt.tight_layout()
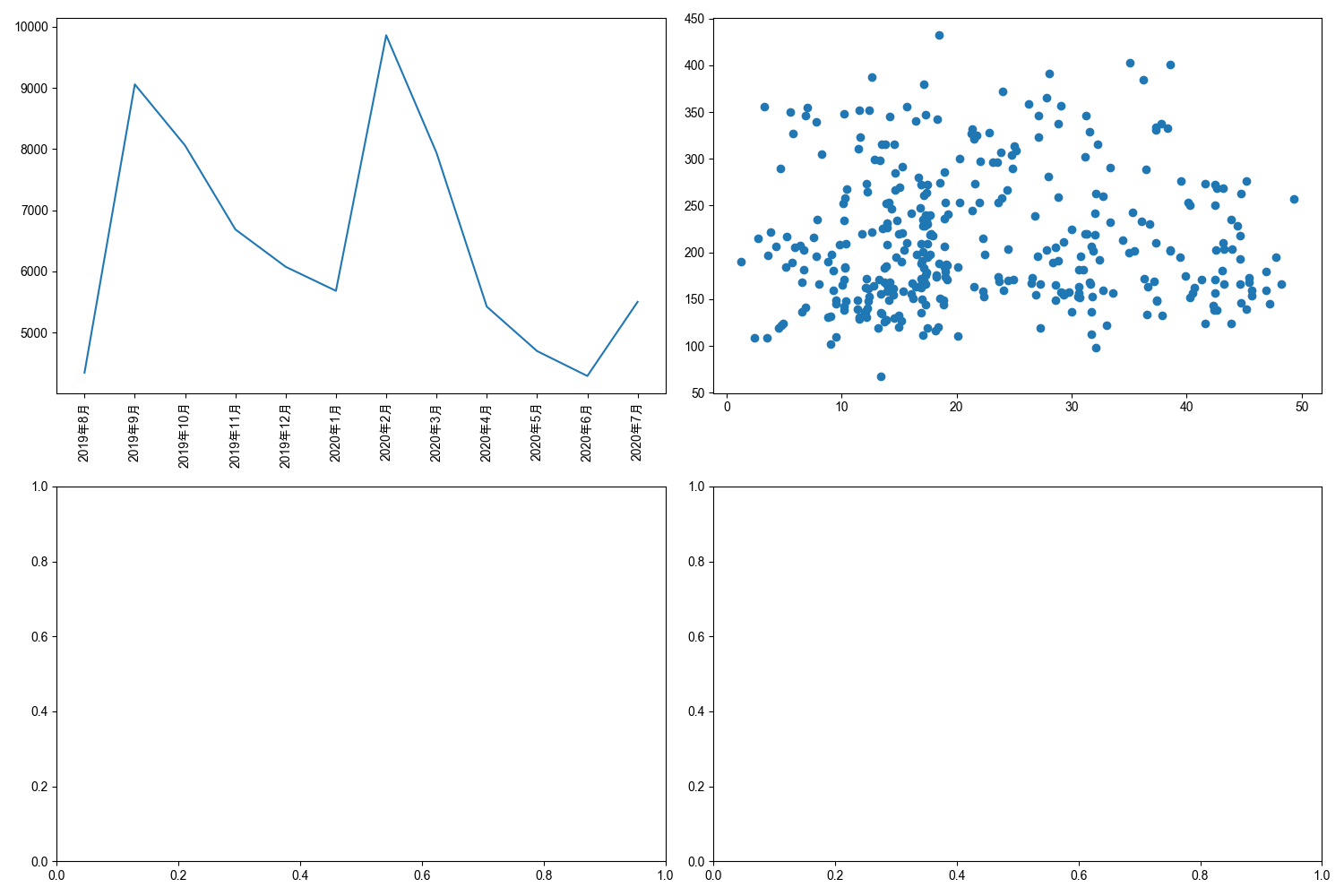
以上,通过matplotlib.pyplot模块在子图上进行绘制。
在子图上使用pandas模块绘图
ax=plt.gca()
在子图上使用pandas模块绘图,需要在绘图的函数中,传入 ax=plt.gca()。
ax 参数用来指定 坐标图形(axes)对象,而 plt.gca()则是用来返回 当前状态下的坐标图形(axes)对象。
由于pandas模块不能像matplotlib.pyplot一样默认将图像绘制到当前的子图坐标轴上,所以需要传入 ax=plt.gca(),来确保图像绘制在当前子图的坐标轴中。
e.g,选择序号为3的子图,根据data的数据,使用pandas模块的 plot.bar()函数,以其中的”month”为x轴,来绘制对比”first_floor”、”second_floor”和”third_floor”销量的簇形柱状图:
选择序号为3的子图
plt.subplot(2,2,3)
使用plot.bar()函数和ax=plt.gca()
根据data中的数据
以"month"为x轴,["first_floor","second_floor","third_floor"]为y轴
绘制簇形柱状图
data.plot.bar("month",["first_floor","second_floor","third_floor"],ax=plt.gca())
使用常用的参数和函数,完善每个子图的图像。
导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
导入pandas,并使用"pd"作为该模块的简写
import pandas as pd
读取路径为 "/Users/yequ/书店每月销量数据.csv" 的CSV文件,并将结果赋值给变量data
data = pd.read_csv("/Users/yequ/书店每月销量数据.csv")
读取路径为 "/Users/yequ/书店图书销量和广告费用.csv" 的CSV文件,并将结果赋值给变量df
df = pd.read_csv("/Users/yequ/书店图书销量和广告费用.csv")
使用pd.read_csv()函数
读取路径为 "/Users/yequ/书店每月销量数据百分比.csv" 的CSV文件,并赋值给变量percentData
percentData = pd.read_csv("/Users/yequ/书店每月销量数据百分比.csv")
通过 rcParams 参数将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
使用plt.subplot()函数添加4个子图
子图有两行两列
选择序号为1子图
plt.subplot(2,2,1)
使用plt.plot()函数绘制折线图
plt.plot(data["month"],data["sum"])
使用plt.xticks()函数旋转x轴的刻度至90度
plt.xticks(rotation=90)
使用plt.xlabel()函数,将x轴标题设置为"月份"
plt.xlabel("月份")
使用plt.ylabel()函数,将y轴标题设置为"销量"
plt.ylabel("销量")
选择序号为2子图
plt.subplot(2,2,2)
使用plt.scatter()函数
以df["ads_fee"]为x轴的值和df["sales"]为y轴的值,绘制散点图
plt.scatter(df["ads_fee"],df["sales"])
使用plt.xlabel()函数,将x轴标题设置为"广告费用"
plt.xlabel("广告费用")
使用plt.ylabel()函数,将y轴标题设置为"销量"
plt.ylabel("销量")
选择序号为3的子图
plt.subplot(2,2,3)
使用plot.bar()函数和ax=plt.gca()
根据data中的数据
以"month"为x轴,["first_floor","second_floor","third_floor"]为y轴
绘制簇形柱状图
data.plot.bar("month",["first_floor","second_floor","third_floor"],ax=plt.gca())
使用plt.xlabel()函数,将x轴标题设置为"月份"
plt.xlabel("月份")
使用plt.ylabel()函数,将y轴标题设置为"销量"
plt.ylabel("销量")
选择序号为4子图
plt.subplot(2,2,4)
使用plot.bar()函数,stacked=True和ax=plt.gca()
根据percentData中的数据
以"month"为x轴,绘制对比["一楼","二楼","三楼"]的百分比堆积柱状图
percentData.plot.bar("month",["一楼","二楼","三楼"],stacked=True,ax=plt.gca())
使用plt.xlabel()函数,将x轴标题设置为"月份"
plt.xlabel("月份")
使用plt.ylabel()函数,将y轴标题设置为"占比"
plt.ylabel("占比")
使用plt.tight_layout()函数来调整子图布局
plt.tight_layout()
使用plt.show()函数显示图像
plt.show()
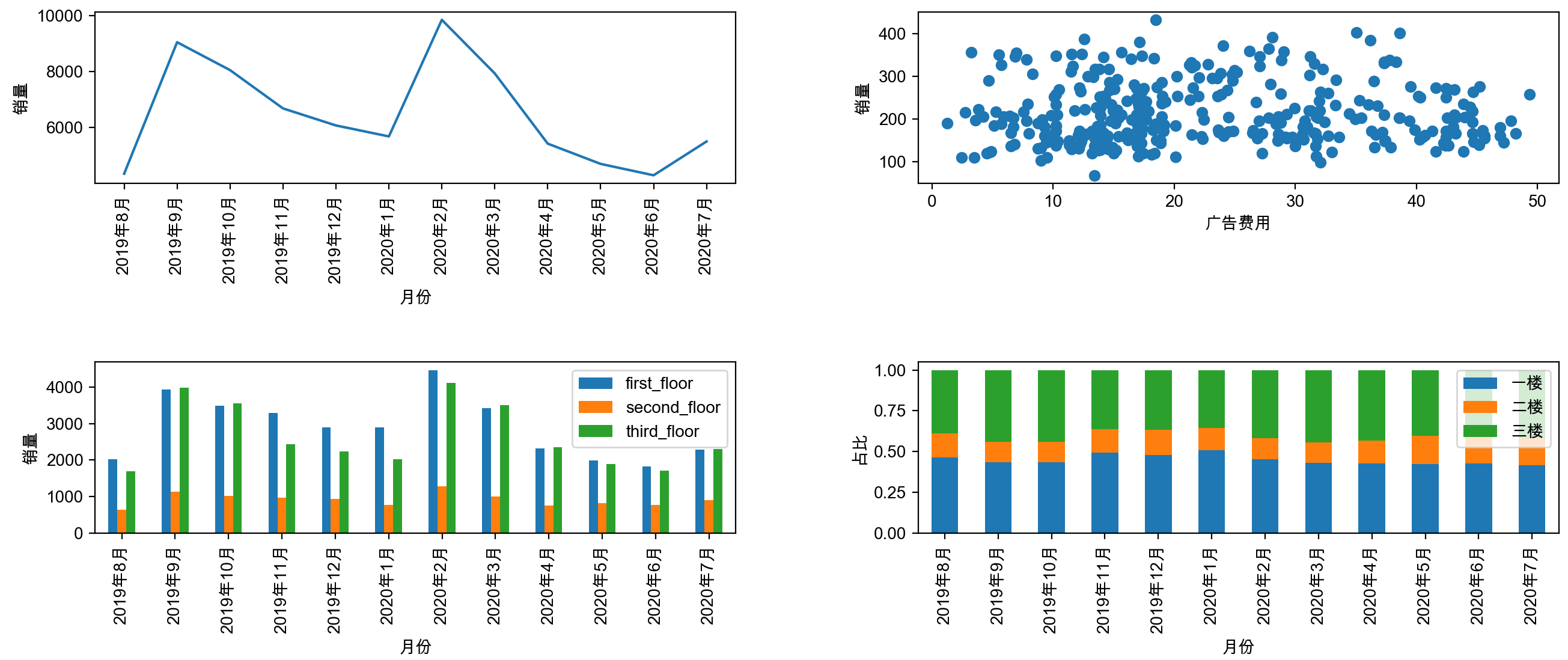
以上可视化主要是用于观察和分析数据关系,需要将其用于报告展现的图表详见《Python数据可视化》。
Original: https://blog.csdn.net/m0_62366803/article/details/125196404
Author: Ag_MoonLi
Title: #18 可视化基础4-簇形柱状图、百分比堆积柱状图、并列子图
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/767825/
转载文章受原作者版权保护。转载请注明原作者出处!