

深入浅出理解数据分析系列之:python绘图和可视化
- 一、figure和add_subplot
- 二、subplots和subplots_adjust
- 三、颜色、标记和线型
- 四、刻度和标签
- 五、图例和注解
- 六、将图标保存到文件
- 七、线型图
- 八、柱状图
- 九、堆积图
- 十、直方图和密度图
- 十一、散点图
- 十二、处理地图数据
一、figure和add_subplot
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
fig = plt.figure()
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
plt.plot(randn(50).cumsum(),'k--')
plt.show()
_ = ax1.hist(randn(100),bins=20,color='k',alpha=0.3)
ax2.scatter(np.arange(30),np.arange(30) + 3 * randn(30))
plt.show()
- k–是一个线型选项,绘制黑色虚线图
- fig.add_subplot所返回的对象是AxesSubplot对象,直接调用实例方法就可以在其他空着的格子里面画图了

二、subplots和subplots_adjust
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
fig,axes = plt.subplots(2,2,sharex=True,sharey=True)
for i in range(2):
for j in range(2):
axes[i,j].hist(randn(500),bins=50,color='b',alpha=0.5)
plt.subplots_adjust(wspace=0.5,hspace=0.5)
plt.show()
print(axes)
print(axes[0,1])
- plt.subplots可以创建一个新的Figure,并返回一个含有已创建的subplot对象的NumPy数组
- sharex和sharey指定subplot应该具有相同的X轴或Y轴
- wspace和hspace用于控制宽度和高度的百分比,可以用作subplot之间的间距
三、颜色、标记和线型
- matplotlib的plot函数接受一组X和Y坐标,还可以接受一个表示颜色和线型的字符串缩写。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
plt.plot(randn(30).cumsum(),'bo--')
plt.plot(randn(30).cumsum(),color='b',linestyle='dashed',marker='o')
plt.show()
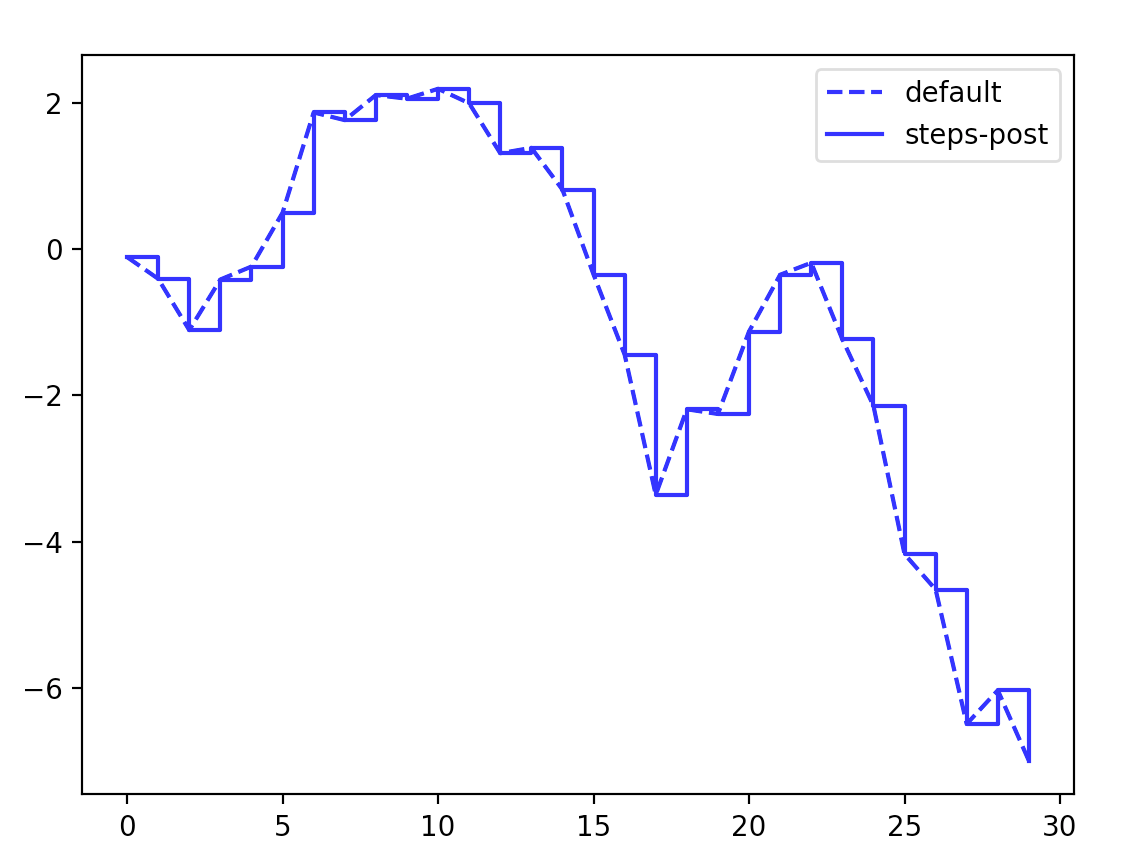
- 在线型图中,非实际数据点默认是按线性方式插值的。
data = randn(30).cumsum()
plt.plot(data,'b--',label='default')
plt.plot(data,'b-',drawstyle='steps-post',label='steps-post')
plt.legend(loc='best')
plt.show()
四、刻度和标签
- xlim:控制图表的范围
- xticks:控制刻度位置
- xticklabels:控制刻度标签
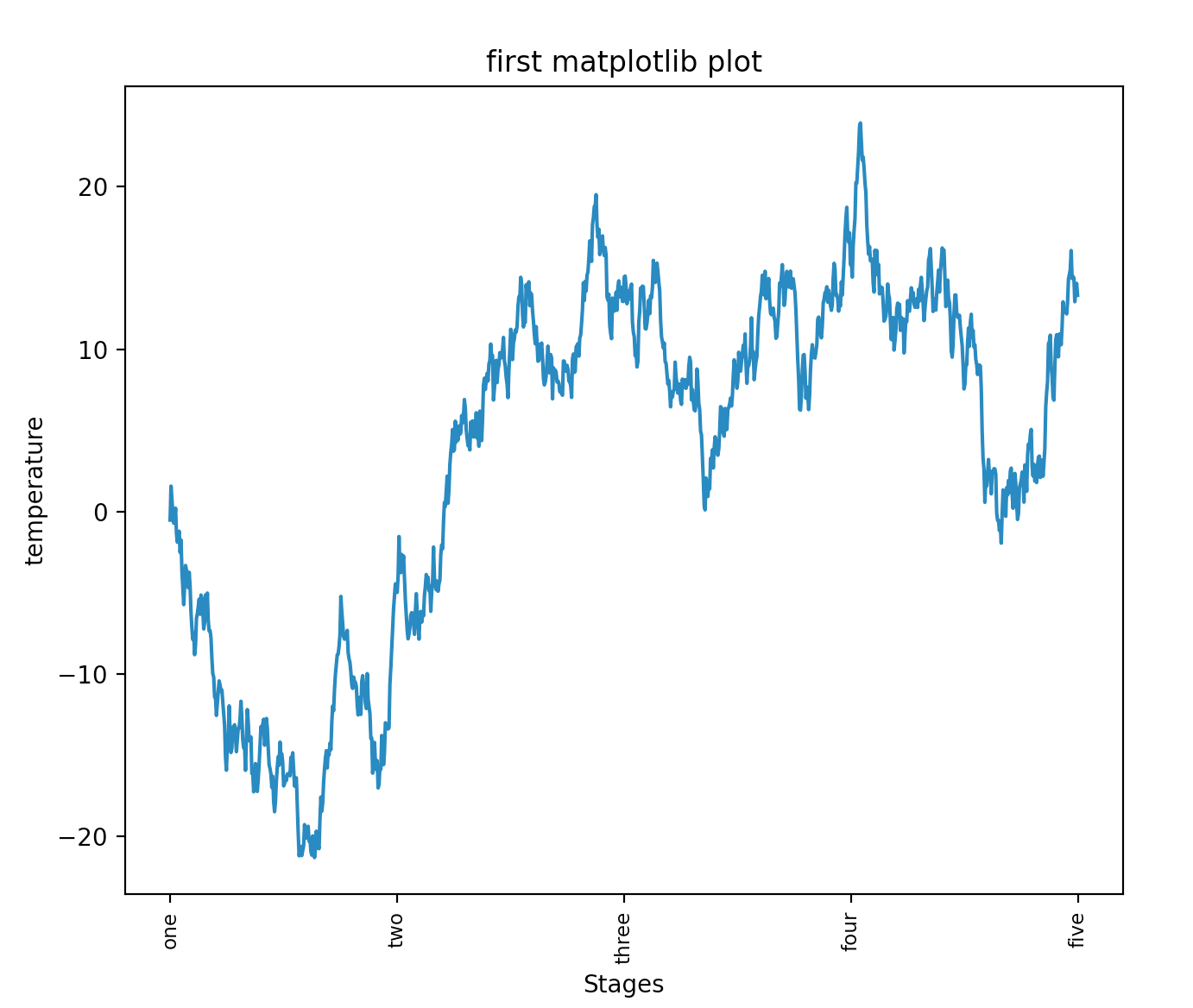
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(randn(1000).cumsum())
ticks = ax.set_xticks([0,250,500,750,1000])
labels = ax.set_xticklabels(['one','two','three','four','five'],rotation=90,fontsize='small')
ax.set_title("first matplotlib plot")
ax.set_xlabel('Stages')
ax.set_ylabel("temperature")
plt.show()
五、图例和注解
- 图例是另一种用于标识图标元素的重要工具
- 最简单的方式是在添加subplot的时候传入label参数
- 可以调用ax.legend()或plt.legend()来自动创建图例
- 注解可以通过text、arrow和annotate等函数进行添加。text可以将文本绘制在图表的指定坐标(x,y),还可以加上自定义格式
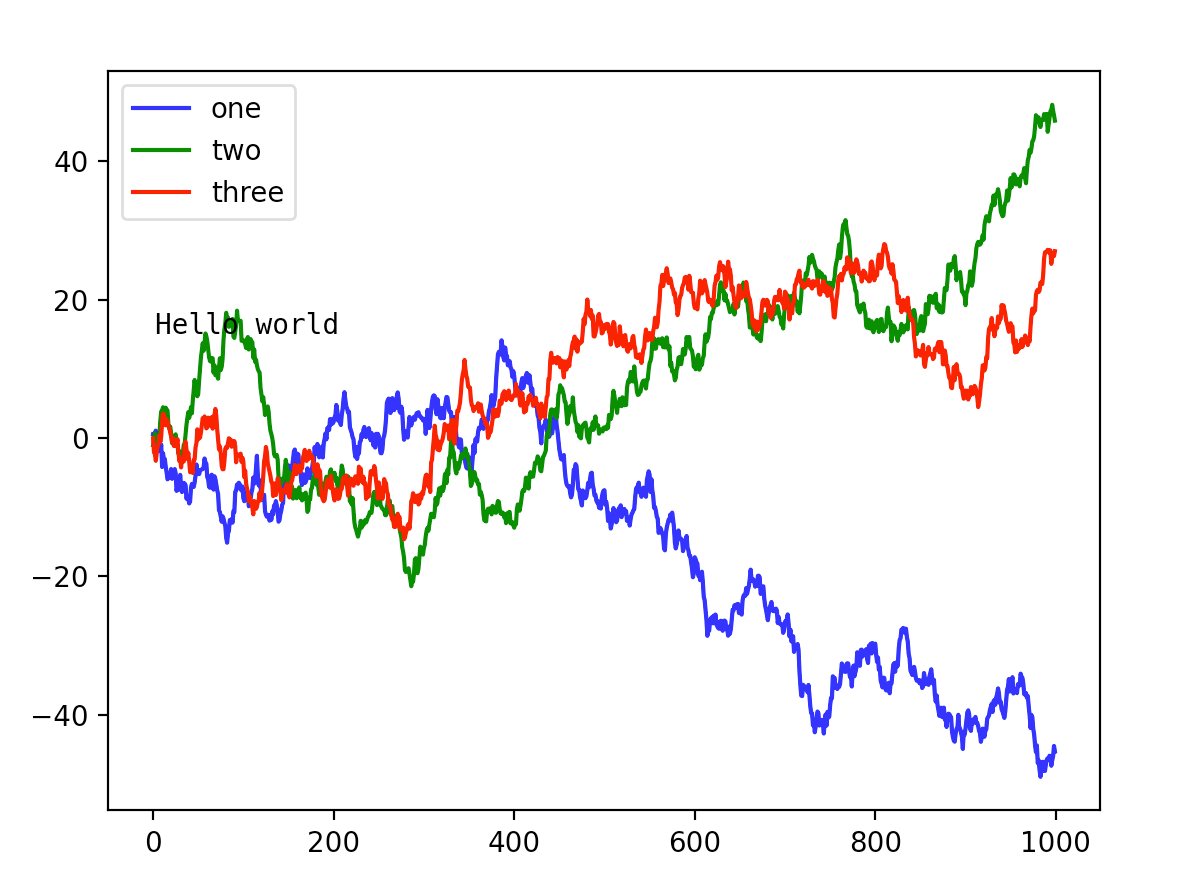
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(randn(1000).cumsum(),'b',label='one')
ax.plot(randn(1000).cumsum(),'g',label='two')
ax.plot(randn(1000).cumsum(),'r',label='three')
ax.legend(loc='best')
ax.text(2,15,'Hello world',family='monospace',fontsize=10)
plt.show()
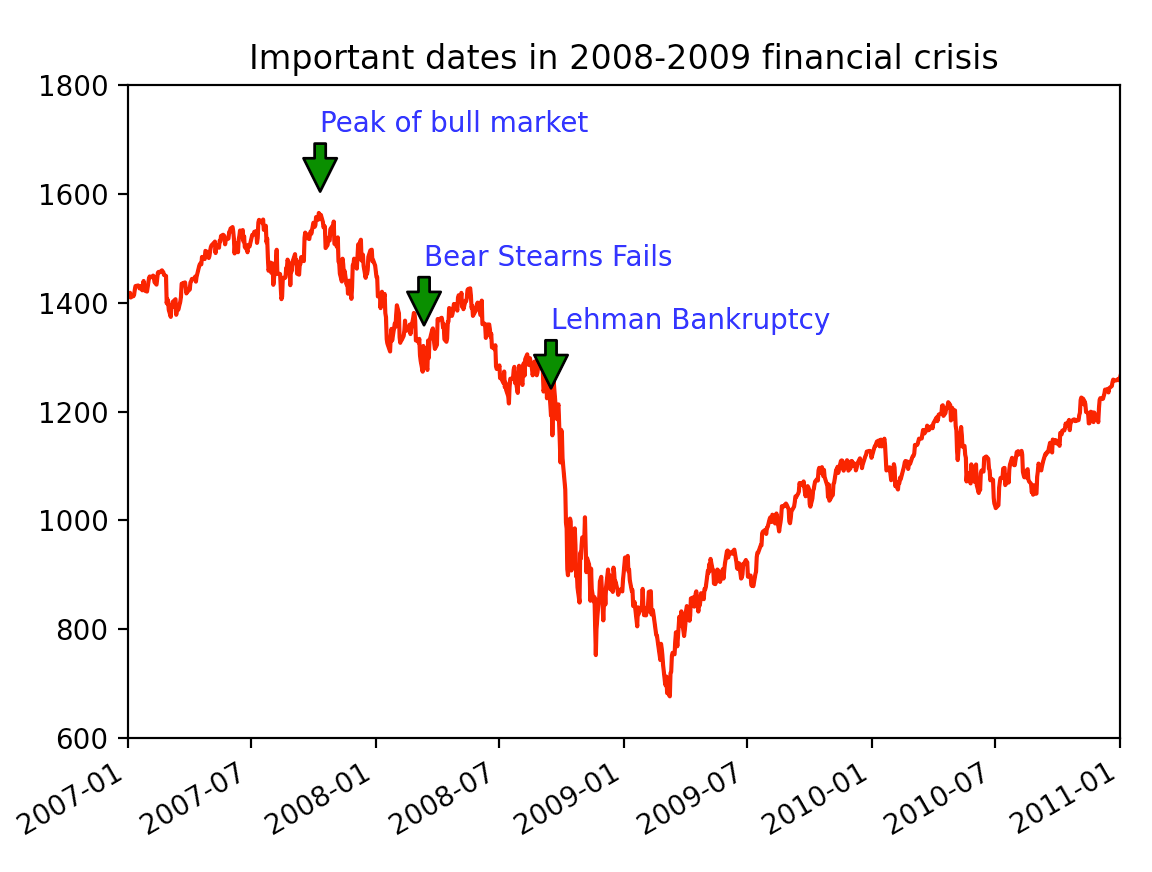
from datetime import datetime
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
data = pd.read_csv('/Users/data/k8s/spx.csv',index_col=0,parse_dates=True)
spx = data['SPX']
spx.plot(ax=ax,style='r-')
crisis_data = [
(datetime(2007,10,11),'Peak of bull market'),
(datetime(2008,3,12),'Bear Stearns Fails'),
(datetime(2008,9,15),'Lehman Bankruptcy')
]
for date,label in crisis_data:
print(spx.asof(date))
ax.annotate(label,xy=(date,spx.asof(date) + 50),
xytext=(date,spx.asof(date) + 200),
arrowprops=dict(facecolor='green'),
horizontalalignment='left',
verticalalignment='top',color='blue'
)
ax.set_xlim(['1/1/2007','1/1/2011'])
ax.set_ylim([600,1800])
ax.set_title('Important dates in 2008-2009 financial crisis')
plt.show()
六、将图标保存到文件
plt.savefig('figpath.png',dpi=400,bbox_inches='tight')
- fname:文件型对象,pdf、png等
- dpi:图像分辨率(每英寸点数),默认为100
- facecolor:图像的背景色,默认为’w’(白色)
- format:显示设置文件格式(png、pdf、svg)
- bbox_inches:图表需要保存的部分,如果设置为tight,则将尝试剪除图表周围的空白部分
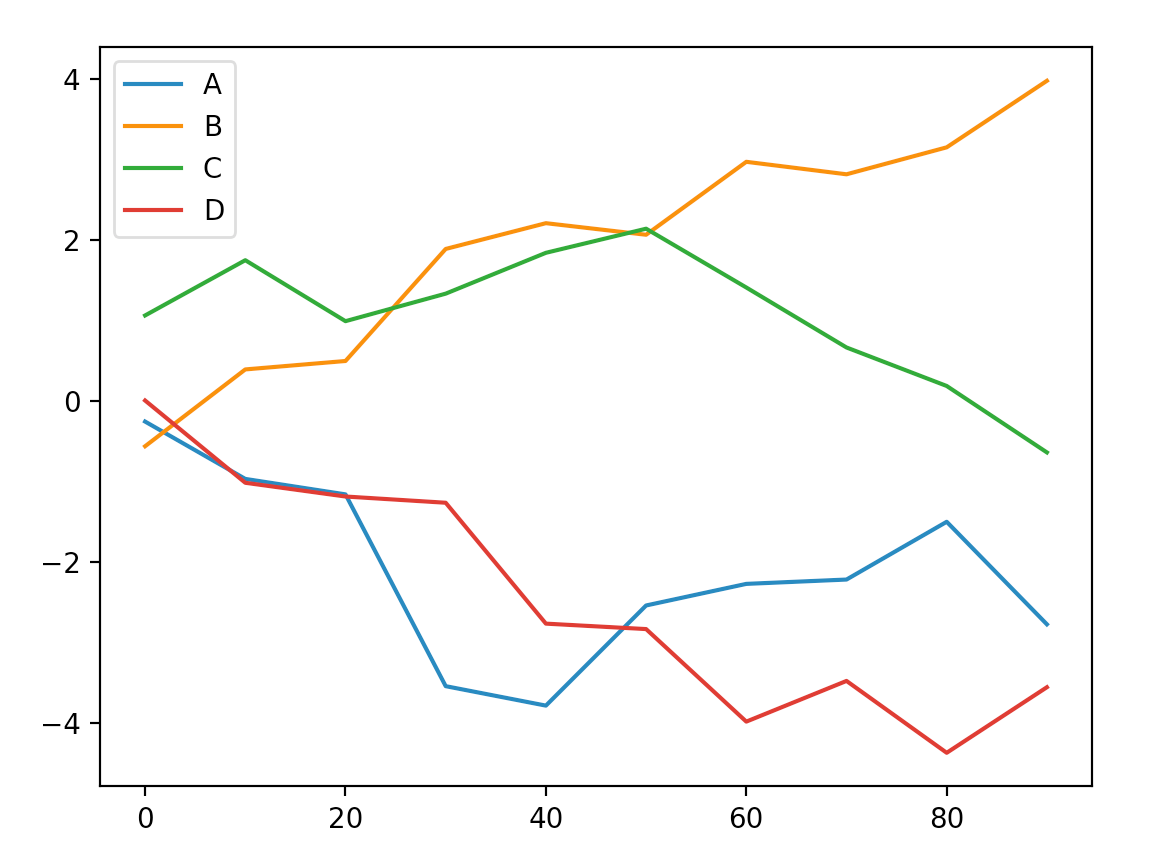
七、线型图
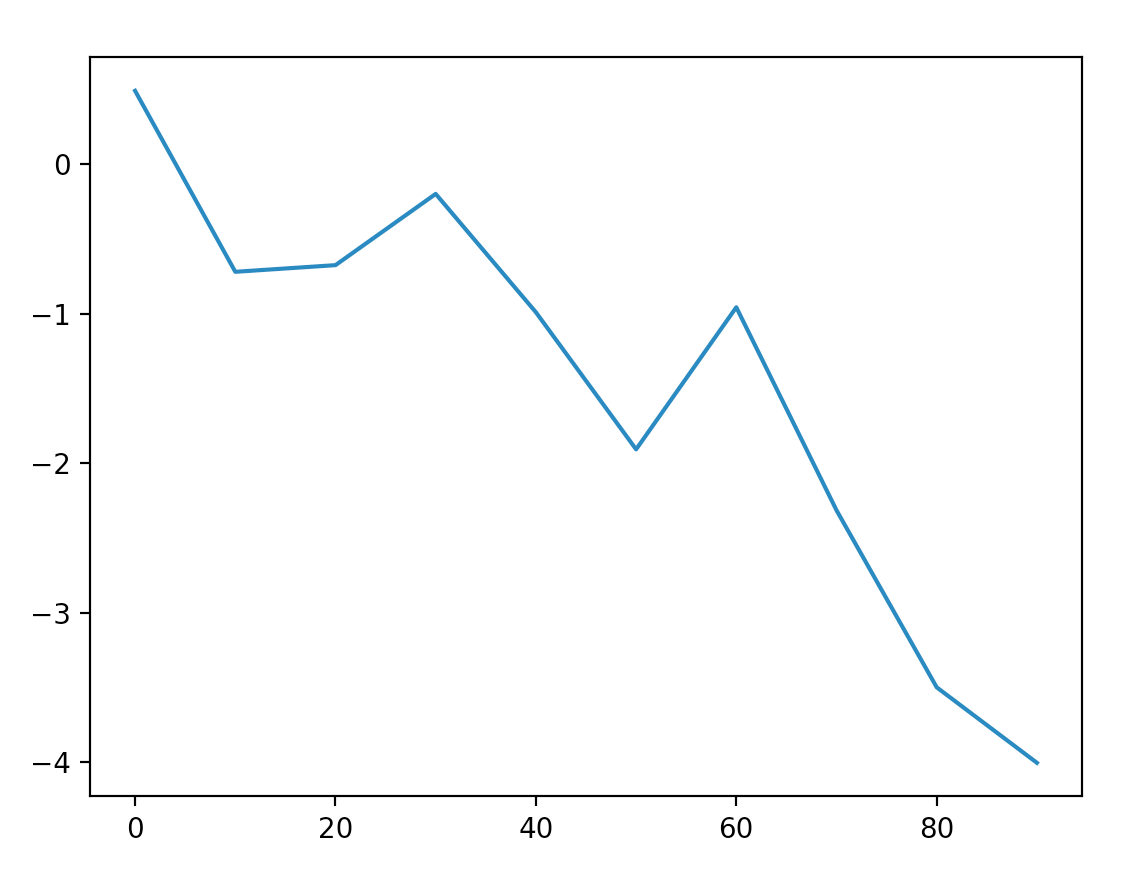
from pandas import Series
s = Series(np.random.randn(10).cumsum(),index=np.arange(0,100,10))
s.plot()
plt.show()
from pandas import DataFrame
df = DataFrame(np.random.randn(10,4).cumsum(0),columns=['A','B','C','D'],index=np.arange(0,100,10))
df.plot()
plt.show()
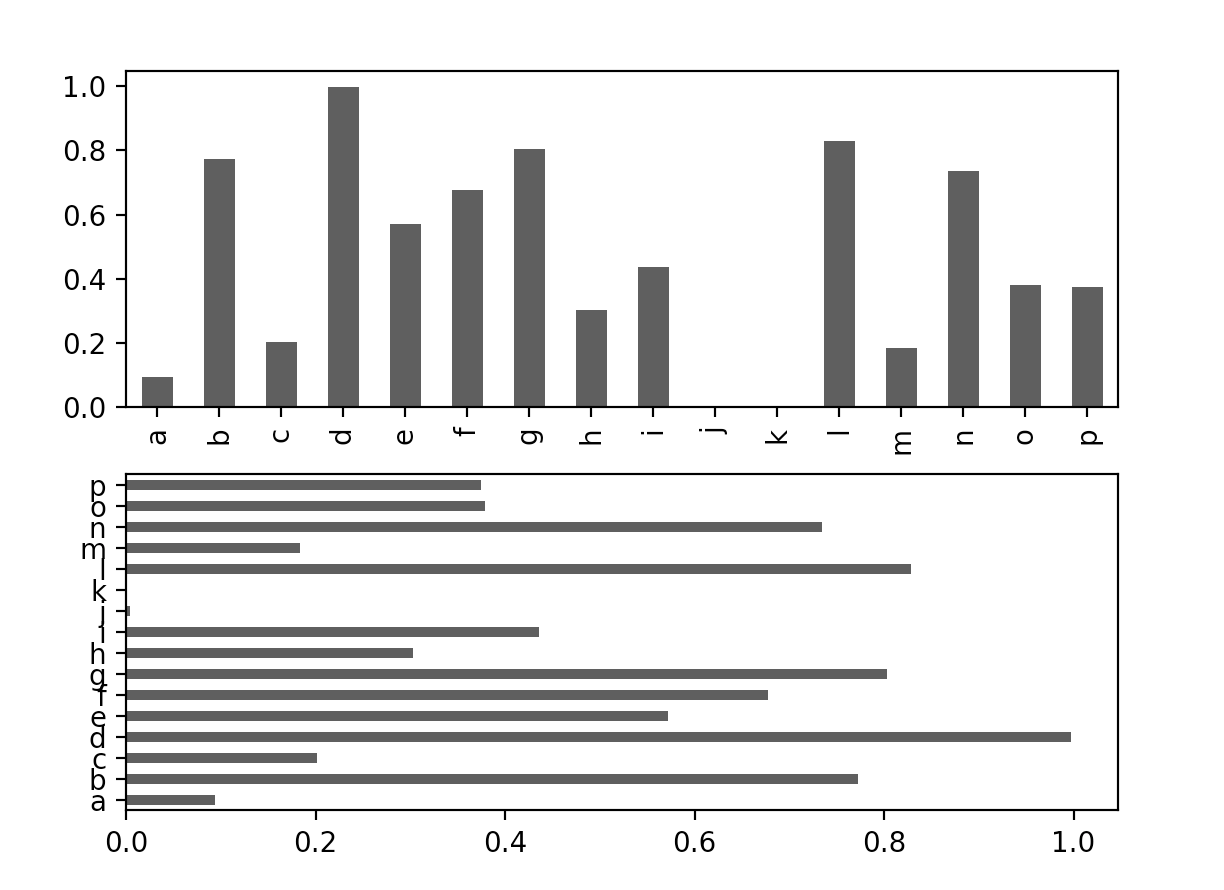
八、柱状图
from pandas import Series
fig,axes = plt.subplots(2,1)
data = Series(np.random.rand(16),index=list('abcdefghijklmnop'))
data.plot(kind='bar',ax=axes[0],color='k',alpha=0.7)
data.plot(kind='barh',ax=axes[1],color='k',alpha=0.7)
plt.show()
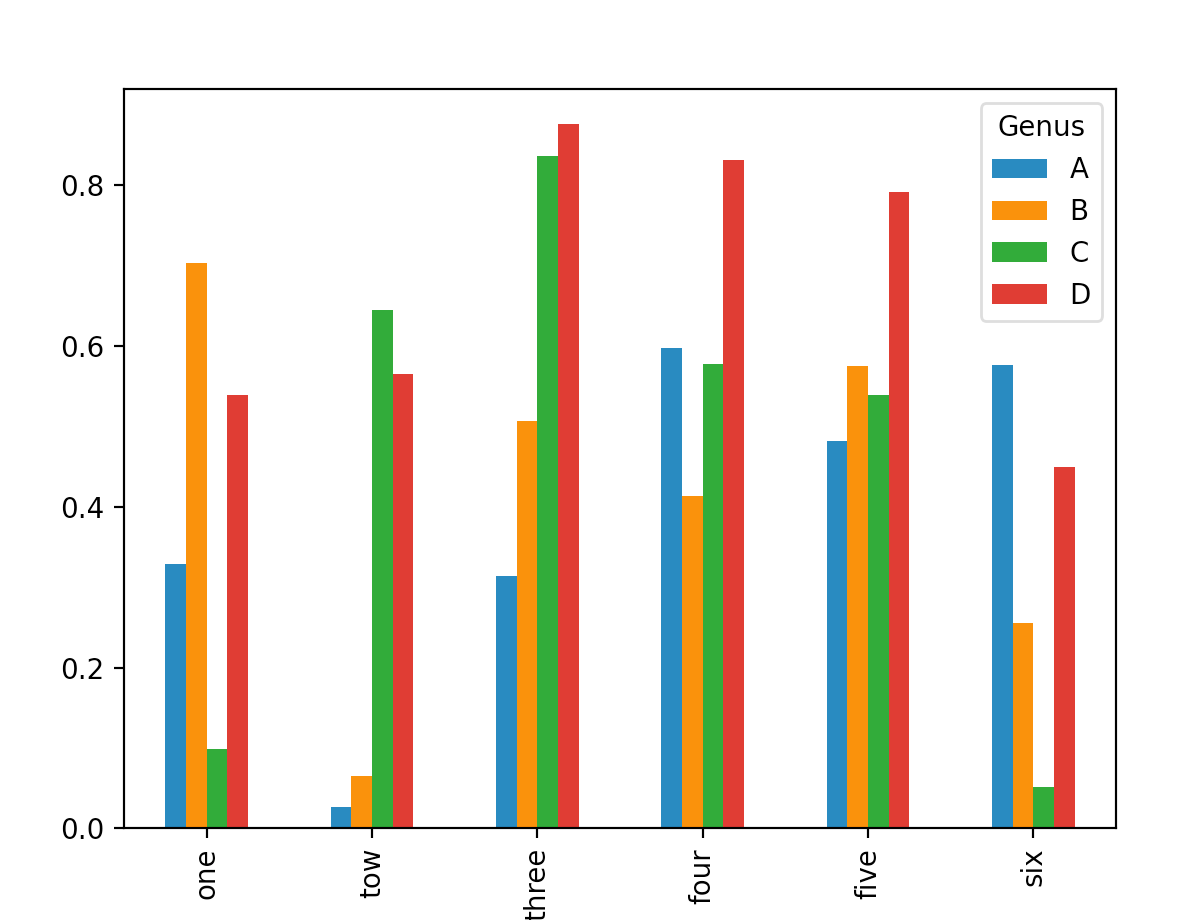
Genus A B C D
one 0.329152 0.703758 0.098856 0.538845
tow 0.026217 0.065790 0.645374 0.565871
three 0.314664 0.507080 0.836806 0.875972
four 0.597416 0.413164 0.578153 0.831303
five 0.482613 0.575113 0.539586 0.791811
six 0.577144 0.255826 0.051190 0.449595
from pandas import DataFrame
df = DataFrame(np.random.rand(6,4),index=['one','tow','three','four','five','six'],
columns=pd.Index(['A',"B",'C','D'],name='Genus'))
print(df)
df.plot(kind='bar')
plt.show()
- DataFrame,柱状图会将每一行的值分为一组
九、堆积图
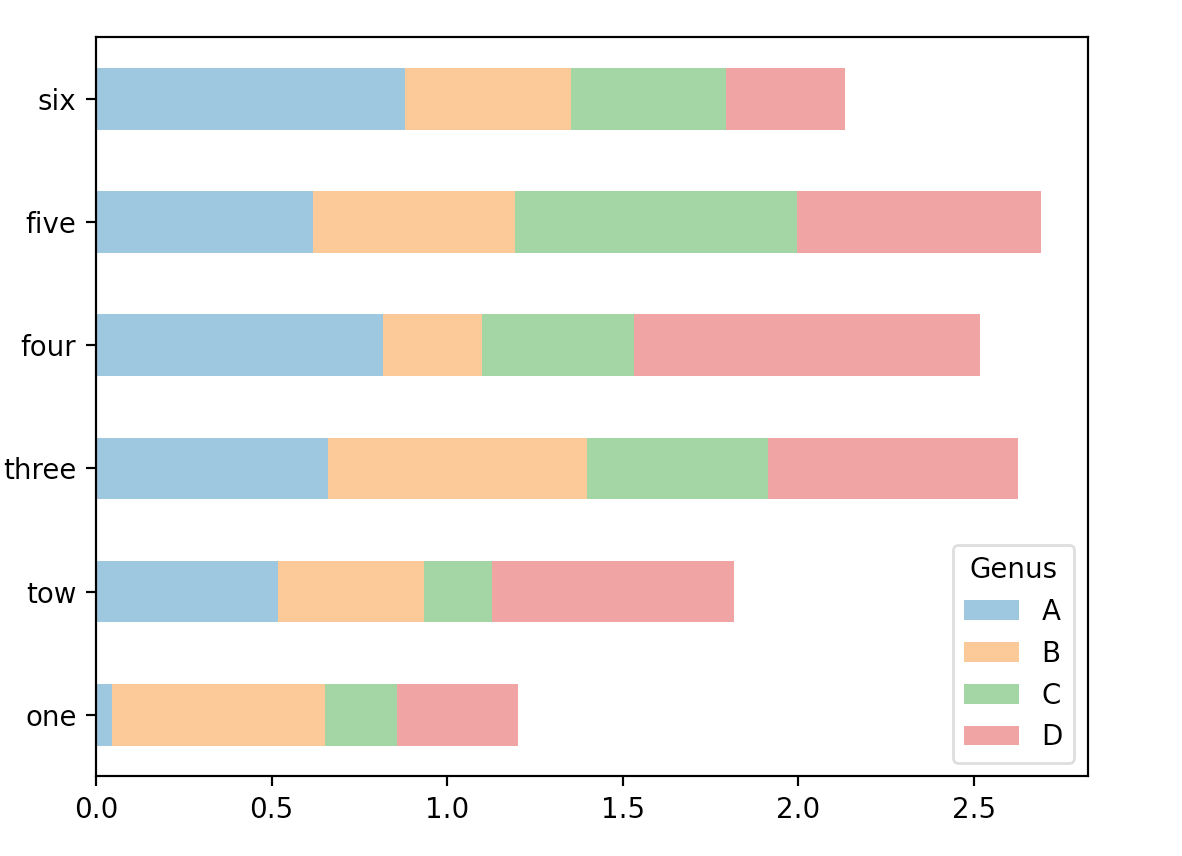
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
df = DataFrame(np.random.rand(6,4),index=['one','tow','three','four','five','six'],
columns=pd.Index(['A',"B",'C','D'],name='Genus'))
print(df)
df.plot(kind='barh',stacked=True,alpha=0.5)
plt.show()
Genus A B C D
one 0.231098 0.380012 0.957876 0.003035
tow 0.346600 0.381683 0.436983 0.292212
three 0.292736 0.640845 0.918077 0.692523
four 0.257667 0.785213 0.054649 0.955289
five 0.194543 0.186177 0.294800 0.775628
six 0.003387 0.032146 0.236350 0.332921
- DataFrame各列的名称Genus被用作了图例的标题。设置stacked=True即可为DataFrame生成堆积柱状图,这样每行的值就会被堆积在一起。
十、直方图和密度图
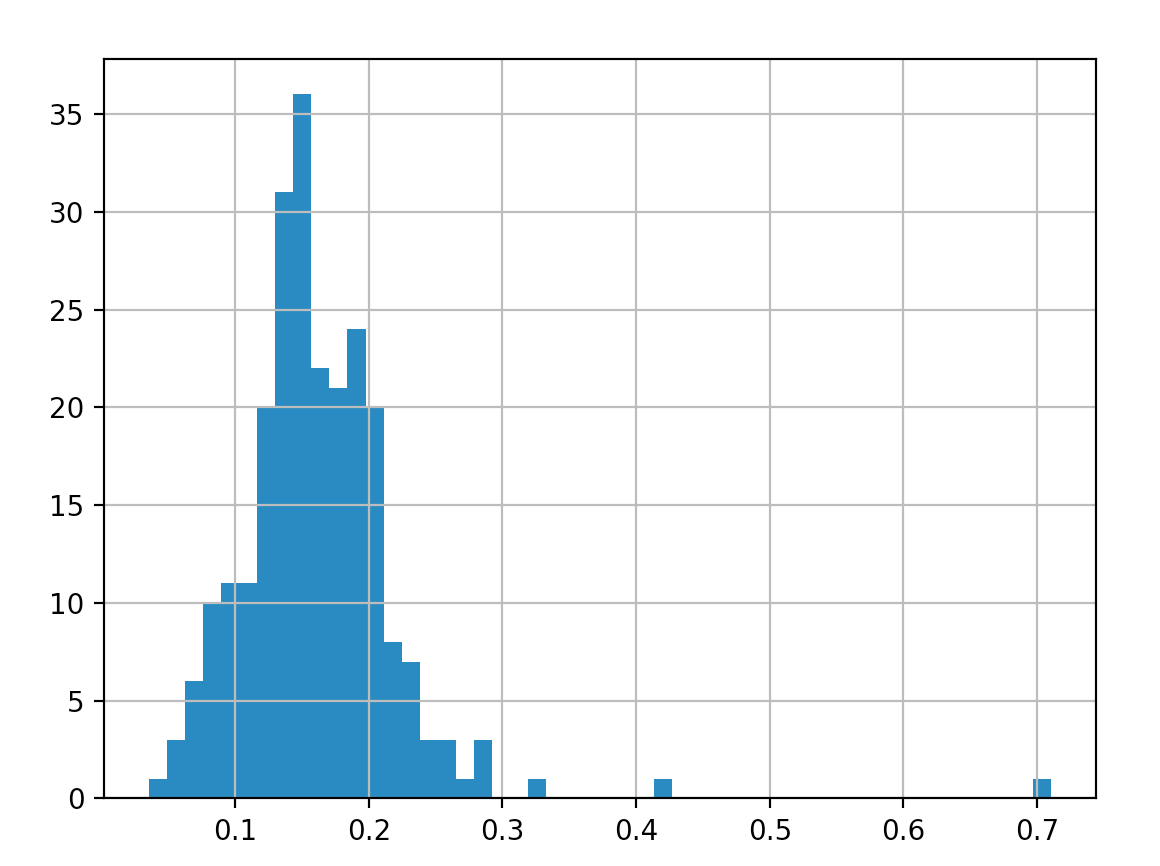
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
from scipy.stats import gaussian_kde
tips = pd.read_csv('/Users/data/tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips['tip_pct'].hist(bins=50)
plt.show()
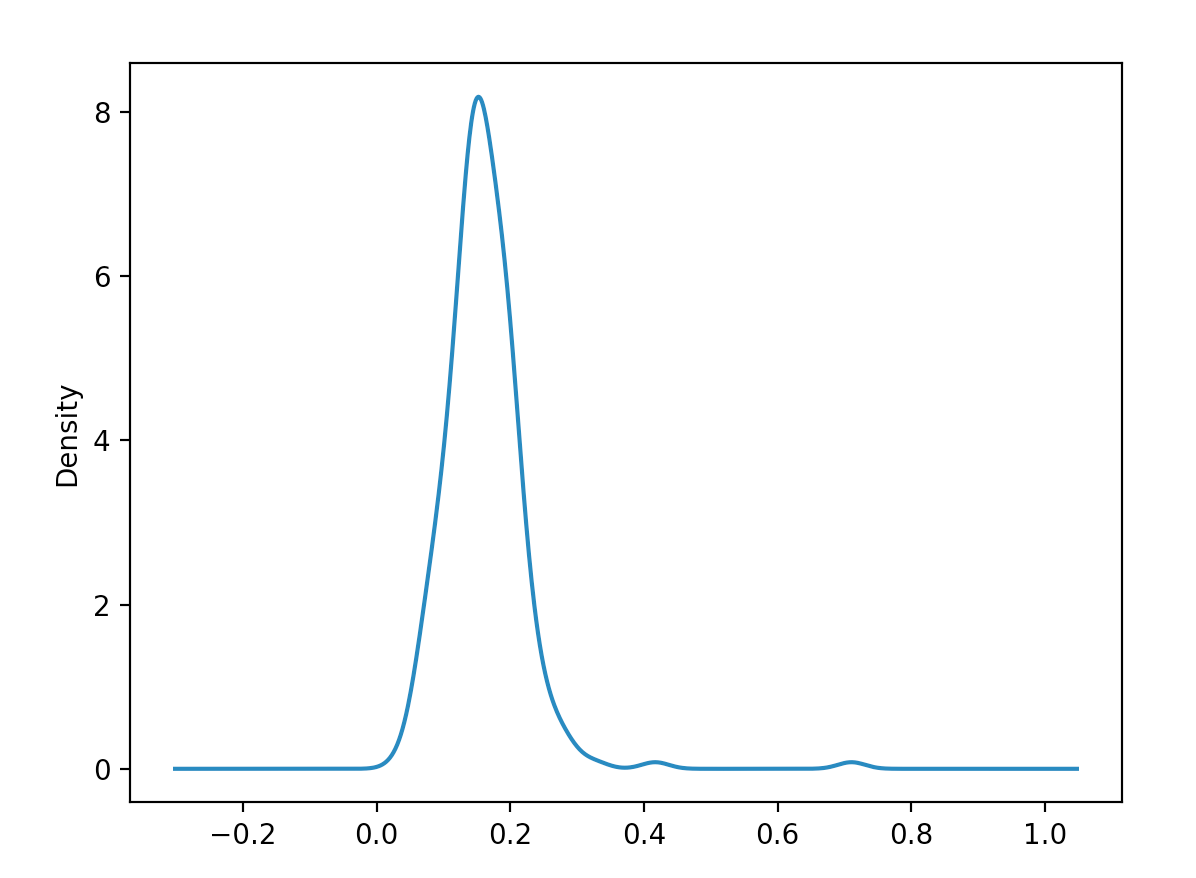
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
from scipy.stats import gaussian_kde
tips = pd.read_csv('/Users/data/tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
tips['tip_pct'].plot(kind='kde')
plt.show()
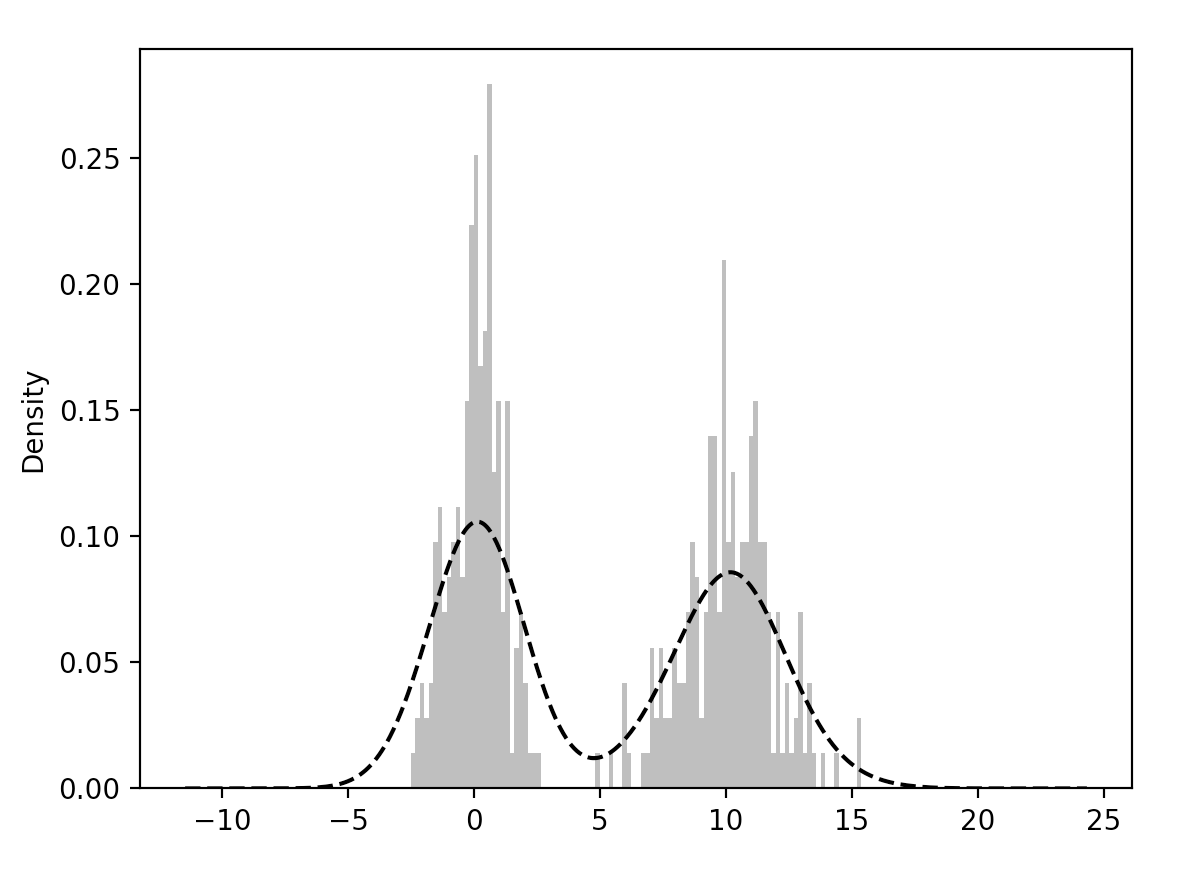
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
from pandas import Series
comp1 = np.random.normal(0,1,size=200)
comp2 = np.random.normal(10,2,size=200)
values = Series(np.concatenate([comp1,comp2]))
values.hist(bins=100,alpha=0.3,color='k',density=True)
values.plot(kind='kde',style='k--')
plt.show()
十一、散点图
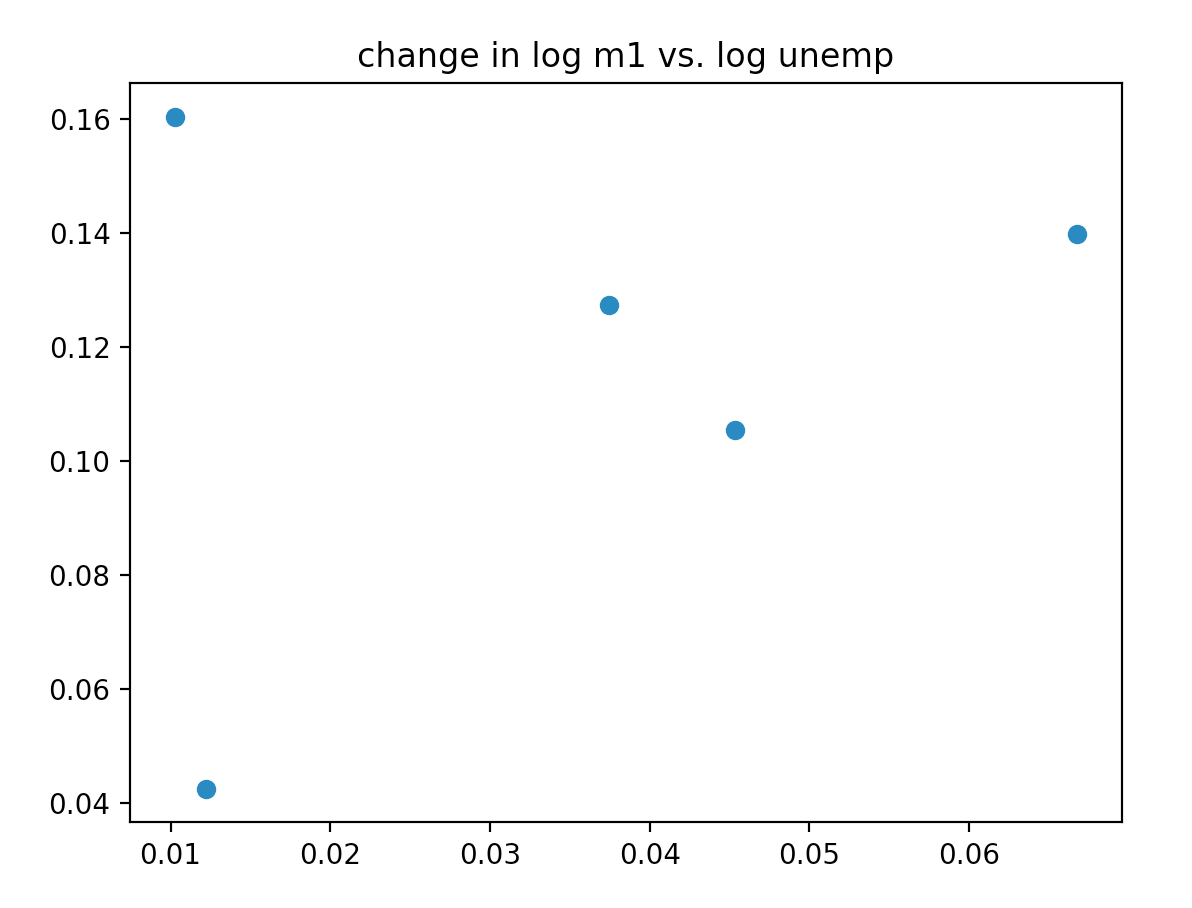
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
macro = pd.read_csv('/Users/data/macrodata.csv')
data = macro[['cpi','m1','tbilrate','unemp']]
trans_data = np.log(data).diff().dropna()
trans_data = trans_data[-5:]
plt.scatter(trans_data['m1'],trans_data['unemp'])
plt.title('change in log %s vs. log %s' %('m1','unemp'))
plt.show()
pd.plotting.scatter_matrix(trans_data,diagonal='kde',color='k',alpha=0.3)
plt.show()
十二、处理地图数据
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from numpy.random import randn
data = pd.read_csv('/Users/data/Haiti.csv')
data = data[(data.LATITUDE > 18) & (data.LATITUDE < 20) & (data.LONGITUDE > -75) & (data.LONGITUDE < -70) & data.CATEGORY.notnull()]
def to_cat_list(catstr):
stripped = (x.strip() for x in catstr.split(','))
return [x for x in stripped if x]
def get_all_categories(cat_series):
cat_sets = (set(to_cat_list(x)) for x in cat_series)
return sorted(set.union(*cat_sets))
def get_english(cat):
code,names = cat.split('.')
if '|' in names:
names = names.split(' | ')[1]
return code,names.strip()
print(get_english('2. Urgences logistiques | Vital Lines'))
all_cats = get_all_categories(data.CATEGORY)
print(all_cats)
english_mapping = dict(get_english(x) for x in all_cats)
print(english_mapping)
print(english_mapping['2a'])
def get_code(seq):
return [x.split('.')[0] for x in seq if x]
all_codes = get_code(all_cats)
print(all_codes)
['1', '1a', '1b', '1c', '1d', '2', '2a', '2b']
code_index = pd.Index(np.unique(all_codes))
dummy_frame = DataFrame(np.zeros((len(data),len(code_index))),index=data.index,columns=code_index)
print(dummy_frame.iloc[:,:6])
list1 = ["A", "B", "C", "D", "E"]
list2 = ["a", "b", "c", "d", "e"]
print(zip(list1,list2))
for x,y in zip(list1,list2):
print(x,y)
for row,cat in zip(data.index,data.CATEGORY):
print(row,cat)
codes = get_code(to_cat_list(cat))
print(codes)
dummy_frame.loc[row,codes] = 1
print(dummy_frame)
data = data.join(dummy_frame.add_prefix('category_'))
print(dummy_frame.add_prefix('category_'))
data = data.iloc[:,10:15]
print(data)
Original: https://blog.csdn.net/zhengzaifeidelushang/article/details/122233471
Author: 最笨的羊羊
Title: 深入浅出理解数据分析系列之:python绘图和可视化
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/767109/
转载文章受原作者版权保护。转载请注明原作者出处!