

概述
自己看着玩玩,如有侵权,请联系我,立刻删除
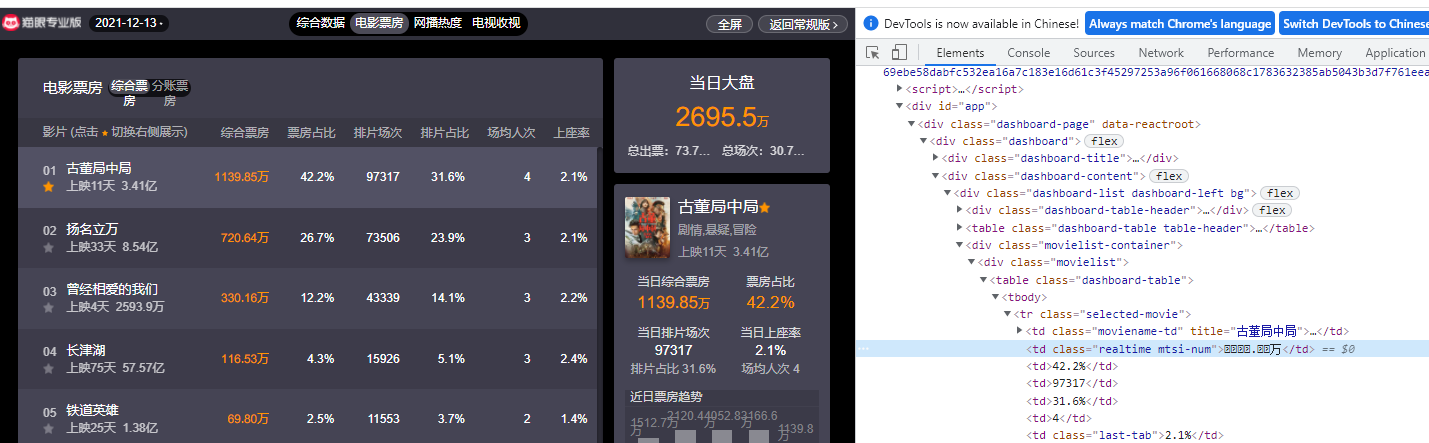

爬取关键点
1.猫眼票房字体动态加密,需要破解
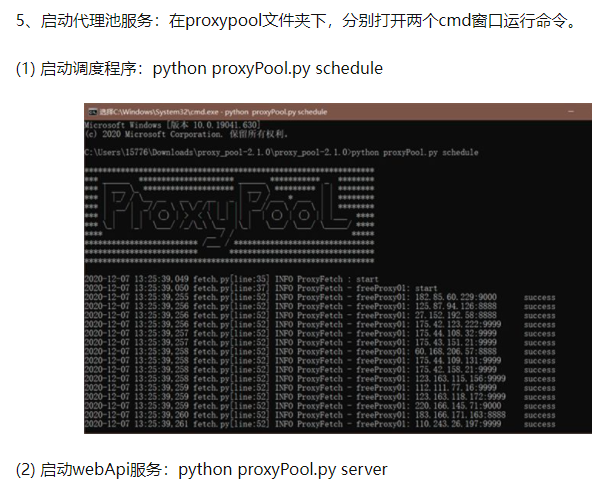
2.截止今日20210101-20211214,有350天左右,需要ip代理池,Proxypool,代理池搭建链接如下:
通过github搭建代理池
3.需要构造浏览器头段,user-agent
随机生成浏览器
4.猫眼专业版,中间有几天浏览器页面看不到,采用后面额外处理的方法
5.主要采用selenium+pyquer+request+无头Edge的方法
提前告知
缺点:爬取350页需要2小时,主要是留给浏览器加载JS的时间,每页留了10s
; 破解动态字体加密 font.py
关键点,需要对woff文件由一定的了解
猫眼加密文件为
- 使用requests,下载woff文件,
- 采用fontTools,获取字体编码
- 采用matplotlib,绘制编码出来的坐标图
- 采用ddddocr(一种轻便OCR),识别图像数据
- 最终:编码与数字对应起来, 得到编码映射字典
#font.py
from fontTools.ttLib import TTFont
import matplotlib.pyplot as plt
import numpy as np
import ddddocr
from os import remove
def get_fontdict(woff_path, woffname):
#打开woff文件,获取编码列表,字体坐标列表
base_font = TTFont(r'{}\{}'.format(woff_path, woffname))
#获取字体编码
#['uniEA9E', 'uniE528', 'uniE4A0', 'uniF0D8', 'uniF19A', 'uniEC3C', 'uniF7BE', 'uniF702', 'uniEE91', 'uniEC82']
font_name = base_font.getGlyphOrder()[2:]
#获取每个字体编码对应的坐标
zb = [base_font['glyf'][i].coordinates for i in font_name]
#OCR
ocr = ddddocr.DdddOcr()
#识别出的数字列表
font_id = []
#将每个坐标绘制,绘制两个出来,并使用ocr进行识别数字
fig, ax = plt.subplots()
for index, one in enumerate(zb):
x, y = [i[0] for i in one], [i[1] for i in one]
#plt.scatte(x, y, c='r')
plt.plot(x, y)
x_n = [i + np.max(x) + 100 for i in x]
#plt.scatter(x_n, y, c='r')
plt.plot(x_n, y)
plt.fill(x, y, 'black')
plt.fill(x_n, y, 'black')
# 去边框
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
# 去刻度
plt.axis('off')
plt.fill(x, y, 'black')
#存储图片
plt.savefig(r'{}\img-{}.png'.format(woff_path, index))
#time.sleep(2)
plt.close()
#识别图片
with open(r'{}\img-{}.png'.format(woff_path, index), 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
font_id.append(res)
#删除图片
remove(r'{}\img-{}.png'.format(woff_path, index))
font_dict = {}
for i in range(len(font_name)):
font_dict[font_name[i].lower()] = font_id[i][0]
return font_dict
使用及结果如下:
aa = get_fontdict(r'C:\Users\26053\Desktop\论文\Python\github\猫眼专业版','test.woff')
print(aa)
#{'unie0a8': '1', 'uniebad': '9', 'unie340': '4', 'unie6a7': '6', 'unieba2': '3', 'unif4a0': '0', 'unif740': '7', 'uniec65': '2', 'unif1c9': '8', 'unie804': '5'}
挖掘开始
开启IP池
搭建好proxypool后,启动,启动方式参考上面搭建IP代理池的链接
引入库
使用selenium作为浏览器爬取,所见所得
使用msedge驱动,这个地方需要自己安装msedge驱动
import selenium
from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.common.exceptions import TimeoutException,NoSuchElementException
import pandas as pd
import time
import requests
from msedge.selenium_tools import EdgeOptions
from msedge.selenium_tools import Edge
from fake_useragent import UserAgent
from font import *
import re
import os
调用useragent/ip
#ua,使用本地的json文件
ua = UserAgent(path=r'C:\Users\26053\Desktop\论文\Python\github\长津湖\ua.json')
#headers = {'User-Agent': ua.random}
#使用IP代理池接口
#5010:settings中设置的监听端口,不是Redis服务的端口
#get:直接获取一个可用代理
#count:获取代理池中可用dialing的数量
def get_proxy():
proxy=requests.get("http://127.0.0.1:5010/get/").json().get('proxy')
return proxy
#proxies={'http':'http://'+get_proxy()} #requests
保存下载woff文件,获取解密后的字体
woff文件直接保存到当前文件夹路径
curr_path=os.getcwd()
#c:\Users\26053\Desktop\论文\Python\github\猫眼专业版
save .woff
def writeFont(font_file,woff_name):
cur_path = r'{}\{}'.format(curr_path, woff_name)
with open(cur_path, 'wb') as f:
f.write(font_file)
#print('已保存')
浏览器的page_source,解析出woff链接,使用requestsf抓取,保存下来,调用font.py,得到编码映射
def parse_font(source): #参数来源浏览器的页面资源
page_font_style=source.find('#font-style-sheet').text() #确定本页字体的渲染密码本连接
woff_url='https:' + re.search(',url\(".*\.woff"\)', page_font_style).group().split('"')[1]
woff_name=woff_url[-13:]
#requests参数
headers = {'User-Agent': ua.random}
proxies={'http':'http://'+get_proxy()} #requests
woff_content=requests.get(url=woff_url,headers=headers,proxies=proxies).content #获取woff的二进制文件
#woff文件保存下来
writeFont(woff_content,woff_name)
#解析woff文件
#获取字体映射字典
font_dict=get_fontdict(curr_path,woff_name) #调用font.py
#解析完成后,删除woff文件
remove(r'{}\{}'.format(curr_path, woff_name))
return font_dict
提前定义我们需要的票房文本,使用字典替换
def finally_font(font_dict,data): #字典编码映射,待解析的文件段
#将待解析的字体使用字典解析
data = repr(data).replace(r'\u', 'uni')
for key, value in font_dict.items():
data = data.replace(key, value)
return data
解析页面资源
对每一页,使用解析库PyQuery,用css选择器定位数据

def get_data(source):
font_dict=parse_font(source)
#当日时间
curr_time=source.find('.cal-current').text()
movie_list=source.find('tbody')
amount_list=[]
for movieinfo in movie_list.find('tr').items():
dic={}
dic['日期']=curr_time
dic['影片']=movieinfo.find('.moviename-td').attr('title')
dic['当前信息']=movieinfo.find('.moviename-info').text()
#按照字典映射,对综合票房字体进行解密
encrypt=movieinfo.find('.realtime.mtsi-num').text()
dic['综合票房']=finally_font(font_dict,encrypt)
#兄弟节点,全部提取
tdlist=movieinfo.find('.realtime.mtsi-num').siblings()
infolist=[]
for data in tdlist.items():
infolist.append(data.text())
dic['票房占比']=infolist[-5]
dic['排片场次']=infolist[-4]
dic['排片占比']=infolist[-3]
dic['场均人次']=infolist[-2]
dic['上座率'] =infolist[-1]
amount_list.append(dic)
return amount_list
主抓取函数
- 确定url:猫眼专业版,初始url:https://piaofang.maoyan.com/dashboard/movie? date=2021-12-14,后面的日期变动,查看的就是当日的信息数据
- 确定页面翻页方式:修改后面的date,从2021-01-01一直到2021-12-15,抓取每一页
- 浏览器配置:selenium+edge,无头浏览器,
- 对每一页资源,直接调用上述的所有函数,解析出想要的数据
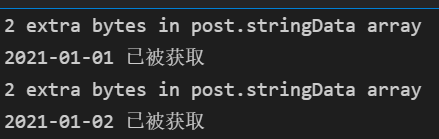
- *额外的:猫眼专业版在2021年2月15日附近出现2天的空白时间,可能是网站在维护,没有数据
并且,抓取过程中,由于网速波动,会出现几次页面抓取不成功的情况,整体抓完之后,再重新抓那几天的数据
primary_url='https://piaofang.maoyan.com/dashboard/movie?date='
def get_source(init_url,start,end):
#时间属性,每一页
get_time=pd.date_range(start=start,end=end)
str_time=get_time.strftime("%Y-%m-%d")
data_list=[]
for i in range(len(str_time)):
url=init_url+str_time[i]
#浏览器配置
edge_options = EdgeOptions()
# 设置无界面模式,也可以添加其它设置
edge_options.use_chromium = True
edge_options.add_argument('headless')
#不出现自动测试字样
edge_options.add_experimental_option('excludeSwitches', ['enable-automation'])
browser = Edge(options=edge_options, executable_path='msedgedriver.exe')
browser.get(url)
time.sleep(10)
source=pq(browser.page_source)
try:
data=get_data(source)
except:
browser.quit()
print(str_time[i],'页面错误**************************')
pass
data_list.append(data)
browser.quit()
print(str_time[i],'已被获取')
return data_list
使用
#获取2021年1月到12月的信息
start='1/1/2021'
end='12/14/2021'
data_year=get_source(init_url=primary_url,start=start,end=end)
结果

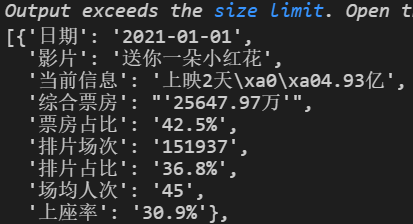
#提取嵌套列表
#将嵌套列表中的所有数据全部取出来
datalist=[]
for item in data_year:
if isinstance(item,list):#如果元素是列表
for data in item:
datalist.append(data)
else:
datalist.append(item)
datalist
保存为csv文件
df=pd.DataFrame(datalist)
df.to_csv('猫眼专业版电压票房数据.csv')
额外操作
由于selenium页面渲染等其他原因,中间会有几天数据抓取错误,但是使用浏览器可以重新查看,
额外如下:重获取3月17,4月19,8月28数据
重获取出错几天
start1='3/17/2021'
end1='3/18/2021'
#data_year=get_source(init_url=primary_url,start=start,end=end)
three_month=get_source(init_url=primary_url,start=start1,end=end1)
start2='4/19/2021'
end2='4/18/2021'
four_month=get_source(init_url=primary_url,start=start2,end=end2)
start3='8/28/2021'
end3='8/29/2021'
eight_month=get_source(init_url=primary_url,start=start3,end=end3)
提取出错几天数据
extend_list=[]
extend_list.extend(three_month)
extend_list.extend(four_month)
extend_list.extend(eight_month)
#提取嵌套列表
#将嵌套列表中的所有数据全部取出来
extendlist=[]
for item in extend_list:
if isinstance(item,list):#如果元素是列表
for data in item:
extendlist.append(data)
else:
extendlist.append(item)
extendlist
将重获取的数据与前面的数据在竖直方向合并,生成最终的结果文件
extend_df=pd.DataFrame(extendlist)
finally_data=pd.concat([df,extend_df],axis=0) #竖方向合并
finally_data.to_csv('猫眼专业版电压票房数据_finally.csv')
Original: https://blog.csdn.net/qh_aichun/article/details/121933382
Author: 铁憨憨0304
Title: 2021年挖掘猫眼专业版电影票房数据
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/766688/
转载文章受原作者版权保护。转载请注明原作者出处!