

目录
航班乘客变化分析
%matplotlib inline
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import pandas as pd
import matplotlib
matplotlib.rc('figure', figsize = (10, 5))
matplotlib.rc('font', size = 10)
matplotlib.rc('axes', grid = False)
matplotlib.rc('axes', facecolor = 'white')
data = pd.read_csv("flights.csv")
data.head()
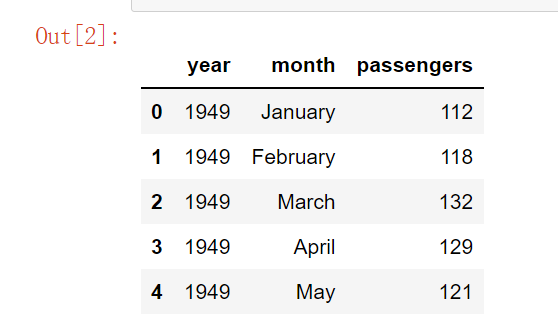

- 分析年度乘客总量变化情况(折线图)
- 分析乘客在一年中各月份的分布(柱状图)
ex11 = data.groupby('year').sum()
ex12 = data.groupby('month').sum()
plt.figure(figsize=(15,5))
plt.subplot(1,2,1)
plt.plot(ex11['passengers'])
plt.title('The number of passengers in each year')
plt.xlabel('year')
plt.ylabel('number')
plt.xticks(ex11.index)
plt.subplot(1,2,2)
x = [i+1 for i in range(len(ex12['passengers']))]
plt.bar(x,ex12['passengers'].values)
plt.title('The number of passengers in each month')
plt.xlabel('month')
plt.ylabel('number')
plt.xticks(x)
plt.show()
鸢尾花花型尺寸分析
- 萼片(sepal)和花瓣(petal)的大小关系(散点图)
- 不同种类(species)鸢尾花萼片和花瓣的大小关系(分类散点子图)
- 不同种类鸢尾花萼片和花瓣大小的分布情况(柱状图或者箱式图)
data = pd.read_csv("iris.csv")
data.head()
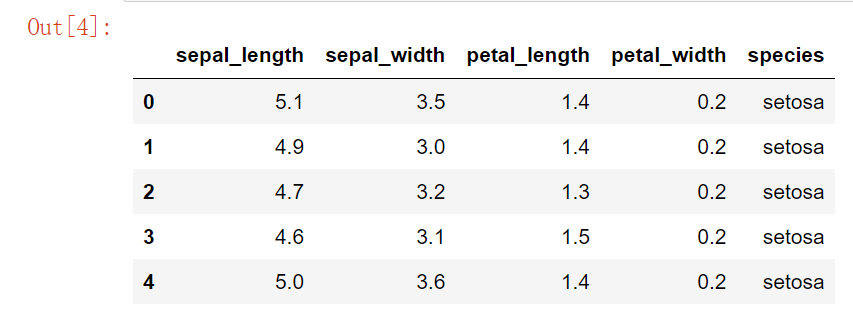
def scatterplot1(x,y,n, x_data, y_data, x_label, y_label, title):
plt.subplot(x,y,n)
plt.scatter(x_data, y_data, s=10, color = '#539caf', alpha=0.75)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.figure(figsize=(10,10))
scatterplot1(2,2,1, data['sepal_length'].values,
data['petal_length'].values,
's_l', 'p_l', 's_l VS. p_l')
scatterplot1(2,2,2, data['sepal_length'].values,
data['petal_width'].values,
's_l', 'p_w', 's_l VS. p_w')
scatterplot1(2,2,3, data['sepal_width'].values,
data['petal_length'].values,
's_w', 'p_l', 's_w VS. p_l')
scatterplot1(2,2,4, data['sepal_width'].values,
data['petal_width'].values,
's_w', 'p_w', 's_w VS. p_w')
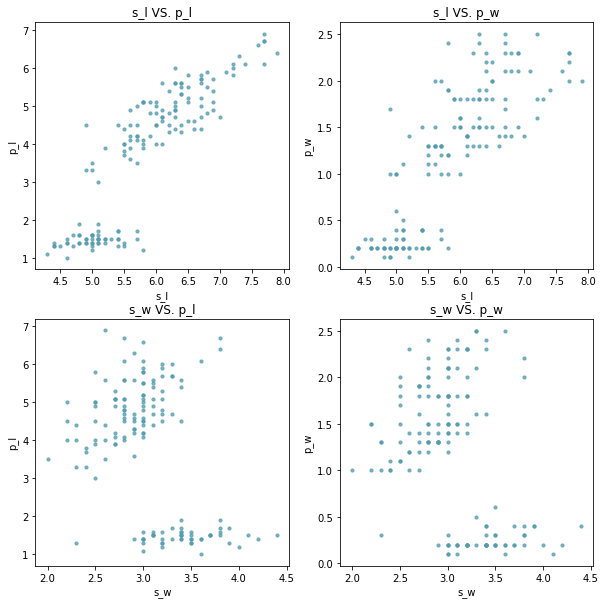
def scatterplot2(x,y,n,data, xlabel, ylabel, x_label, y_label, title):
plt.subplot(x,y,n)
data_s = data[data.species == 'setosa']
data_ver = data[data.species == 'versicolor']
data_vir = data[data.species == 'virginica']
plt.scatter(data_s[xlabel],
data_s[ylabel], s=10, color = '#539caf', alpha=0.75)
plt.scatter(data_ver[xlabel],
data_ver[ylabel], s=10, color = 'red', alpha=0.75)
plt.scatter(data_vir[xlabel],
data_vir[ylabel], s=10, color = 'black', alpha=0.75)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.figure(figsize=(12,12))
scatterplot2(2,2,1,data, 'sepal_length', 'petal_length',
's_l', 'p_l', 's_l VS. p_l')
scatterplot2(2,2,2,data, 'sepal_length', 'petal_width',
's_l', 'p_w', 's_l VS. p_w')
scatterplot2(2,2,3,data, 'sepal_width', 'petal_length',
's_w', 'p_l', 's_w VS. p_l')
scatterplot2(2,2,4,data, 'sepal_width', 'petal_width',
's_w', 'p_w', 's_w VS. p_w')
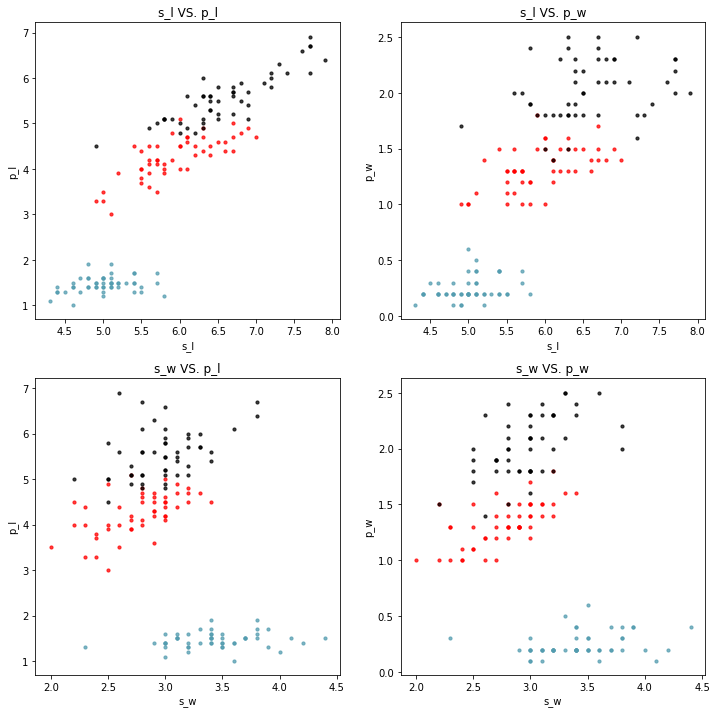
data_s = data[data.species == 'setosa']
data_ver = data[data.species == 'versicolor']
data_vir = data[data.species == 'virginica']
features = ['sepal_length','sepal_width','petal_length','petal_width']
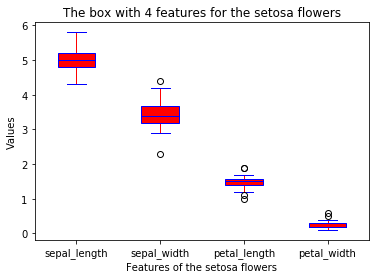
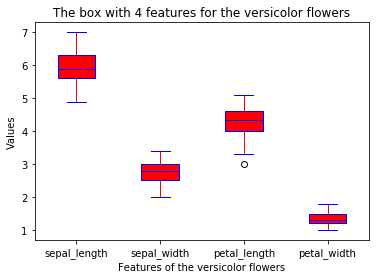
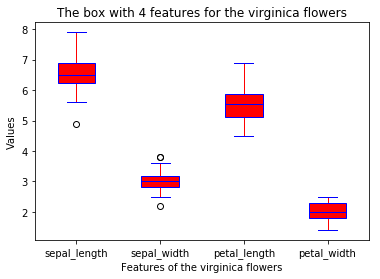
def boxplot(x_data, y_data, base_color, median_color):
bp_data = []
for feature in x_data:
bp_data.append(y_data[feature].values)
_, ax = plt.subplots()
ax.boxplot(bp_data,
patch_artist = True,
medianprops = {'color': base_color},
boxprops = {'color': base_color,
'facecolor': median_color},
whiskerprops = {'color': median_color},
capprops = {'color': base_color})
ax.set_xticklabels(x_data)
ax.set_ylabel('Values')
ax.set_xlabel('Features of the %s flowers'
% y_data.species.values[0])
ax.set_title('The box with 4 features for the %s flowers'
% y_data.species.values[0] )
boxplot(x_data = features
, y_data = data_s
, base_color = 'b'
, median_color = 'r')
boxplot(x_data = features
, y_data = data_ver
, base_color = 'b'
, median_color = 'r')
boxplot(x_data = features
, y_data = data_vir
, base_color = 'b'
, median_color = 'r')
餐厅小费情况分析
data = pd.read_csv("tips.csv")
data.head()
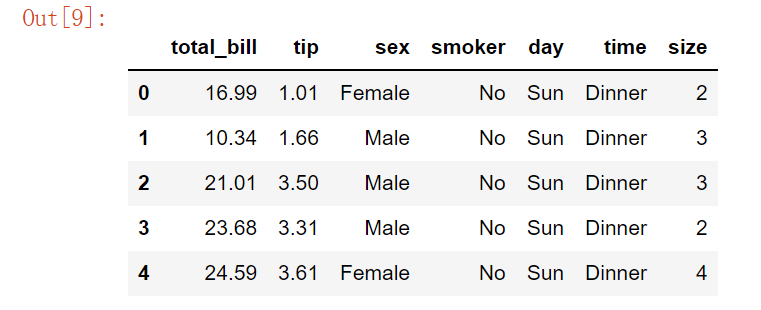
- 小费和总消费之间的关系(散点图)
- 男性顾客和女性顾客,谁更慷慨(分类箱式图)
- 抽烟与否是否会对小费金额产生影响(分类箱式图)
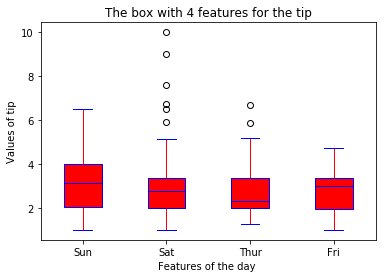
- 工作日和周末,什么时候顾客给的小费更慷慨(分类箱式图)
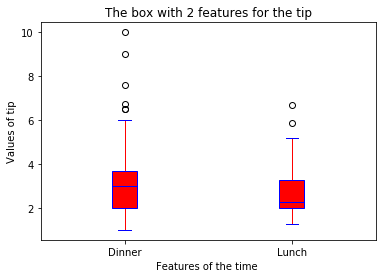
- 午饭和晚饭,哪一顿顾客更愿意给小费(分类箱式图)
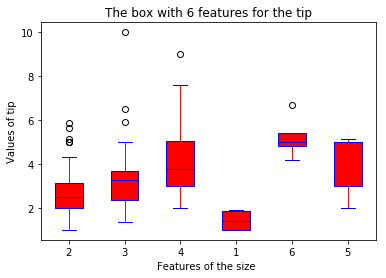
- 就餐人数是否会对慷慨度产生影响(分类箱式图)
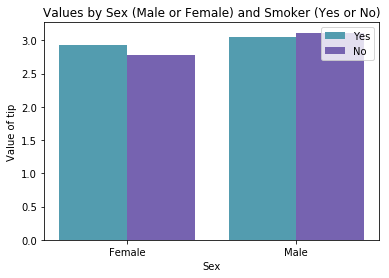
- 性别+抽烟的组合因素对慷慨度的影响(分类柱状图)
def scatterplot(x_data, y_data, x_label, y_label, title):
plt.scatter(x_data, y_data, s=10, color = '#539caf', alpha=0.75)
plt.title(title)
plt.xlabel(x_label)
plt.ylabel(y_label)
scatterplot(data.total_bill, data.tip, 'total bill', 'tip', 'total bill vs. tip')
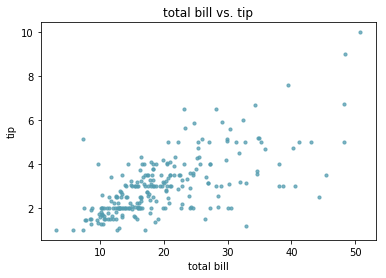
def boxplot(x_data, y_data, y_value, base_color, median_color):
x_feature = data[x_data].unique()
bp_data = []
for item in x_feature:
bp_data.append(data[data[x_data] == item][y_value].values)
_, ax = plt.subplots()
ax.boxplot(bp_data,
patch_artist = True,
medianprops = {'color': base_color},
boxprops = {'color': base_color,
'facecolor': median_color},
whiskerprops = {'color': median_color},
capprops = {'color': base_color})
ax.set_xticklabels(x_feature)
ax.set_ylabel('Values of %s' % y_value)
ax.set_xlabel('Features of the %s '
% x_data)
ax.set_title('The box with %d features for the %s'
% (len(x_feature), y_value) )
boxplot(x_data = 'sex'
, y_data = data
, y_value = 'tip'
, base_color = 'b'
, median_color = 'r')
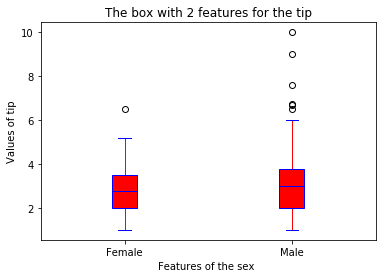
boxplot(x_data = 'smoker'
, y_data = data
, y_value = 'tip'
, base_color = 'b'
, median_color = 'r')
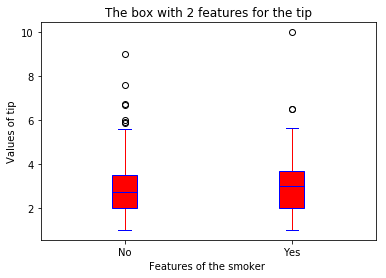
boxplot(x_data = 'day'
, y_data = data
, y_value = 'tip'
, base_color = 'b'
, median_color = 'r')
boxplot(x_data = 'time'
, y_data = data
, y_value = 'tip'
, base_color = 'b'
, median_color = 'r')
boxplot(x_data = 'size'
, y_data = data
, y_value = 'tip'
, base_color = 'b'
, median_color = 'r')
import pandas as pd
import numpy as np
mean_by_sex_smoker = pd.pivot_table(data=data,
values='tip',
index='sex',
columns='smoker',
fill_value=0,
aggfunc='mean')
def groupedbarplot(x_data, y_data_list, y_data_names, colors, x_label, y_label, title):
print(mean_by_sex_smoker)
_, ax = plt.subplots()
total_width = 0.8
ind_width = total_width / len(y_data_list)
alteration = np.arange(-total_width/2+ind_width/2,
total_width/2+ind_width/2, ind_width)
x_data = [i for i in range(len(x_data))]
for i in range(0, len(y_data_list)):
ax.bar(x_data + alteration[i], y_data_list[i], color = colors[i],
label = y_data_names[i], width = ind_width)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.set_xticks(np.linspace(0,1,len(mean_by_sex_smoker)))
ax.set_xticklabels(mean_by_sex_smoker.index)
ax.legend(loc = 'upper right')
groupedbarplot(x_data = mean_by_sex_smoker.index.values
, y_data_list = [mean_by_sex_smoker['Yes'],
mean_by_sex_smoker['No']]
, y_data_names = ['Yes', 'No']
, colors = ['#539caf', '#7663b0']
, x_label = 'Sex'
, y_label = 'Value of tip'
, title = 'Values by Sex (Male or Female) and Smoker (Yes or No)')
泰坦尼克号海难幸存状况分析
- 不同仓位等级中幸存和遇难的乘客比例(堆积柱状图)
- 不同性别的幸存比例(堆积柱状图)
- 幸存和遇难乘客的票价分布(分类箱式图)
- 幸存和遇难乘客的年龄分布(分类箱式图)
- 不同上船港口的乘客仓位等级分布(分组柱状图)
- 幸存和遇难乘客堂兄弟姐妹的数量分布(分类箱式图)
- 幸存和遇难乘客父母子女的数量分布(分类箱式图)
- 单独乘船与否和幸存之间有没有联系(堆积柱状图或者分组柱状图)
data = pd.read_csv("titanic.csv")
data.head()
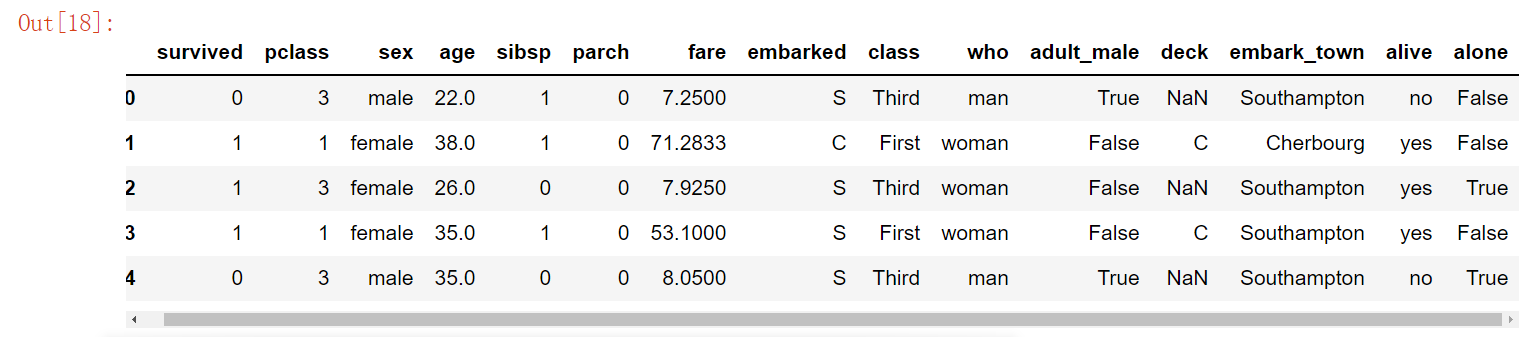
def stackedbarplot(gb, y_data_names, colors, x_label, y_label, title):
num_gb_surv_ornot = data[['survived',gb]].groupby(gb).sum()
num_gb_surv_ornot['unservived'] = data[gb].value_counts()
num_gb_surv_ornot['survived']
num_gb_surv_ornot['total'] = data[gb].value_counts()
num_gb_surv_ornot['survived_prop'] = num_gb_surv_ornot['survived']/num_gb_surv_ornot['total']
num_gb_surv_ornot['unsurvived_prop'] = num_gb_surv_ornot['unservived']/num_gb_surv_ornot['total']
print(num_gb_surv_ornot)
x_data = [i+1 for i in range(len(data[gb].unique()))]
y_data_list = [num_gb_surv_ornot['survived_prop'],
num_gb_surv_ornot['unsurvived_prop']]
_, ax = plt.subplots()
for i in range(0, len(y_data_list)):
if i == 0:
ax.bar(x_data, y_data_list[i], color = colors[i],
align ='center', label = y_data_names[i])
else:
ax.bar(x_data, y_data_list[i], color = colors[i],
bottom = y_data_list[i - 1], align = 'center',
label = y_data_names[i])
ax.set_xticks(np.linspace(1,len(num_gb_surv_ornot),
len(num_gb_surv_ornot)))
ax.set_xticklabels(num_gb_surv_ornot.index)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.legend(loc = (1,1))
stackedbarplot(gb = 'pclass'
, y_data_names = ['Survived', 'Unservived']
, colors = ['#539caf', '#7663b0']
, x_label = 'Pclass'
, y_label = 'Proportion of survived/unsurvived'
, title = 'Proportion of survived/unsurvived by Pclass (1, 2, 3)')

stackedbarplot(gb = 'sex'
, y_data_names = ['Survived', 'Unservived']
, colors = ['#539caf', '#7663b0']
, x_label = 'Sex'
, y_label = 'Proportion of survived/unsurvived'
, title = 'Proportion of survived/unsurvived by Pclass (1, 2, 3)')
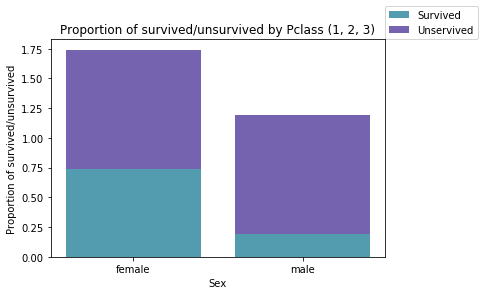
def boxplot(x_data, y_data, y_value, base_color, median_color):
x_feature = data[x_data].unique()
bp_data = []
for item in x_feature:
bp_data.append(y_data[y_data[x_data] == item] [y_value].values)
_, ax = plt.subplots()
ax.boxplot(bp_data,
patch_artist = True,
medianprops = {'color': base_color},
boxprops = {'color': base_color, 'facecolor': median_color},
whiskerprops = {'color': median_color},
capprops = {'color': base_color})
ax.set_xticklabels(x_feature)
ax.set_ylabel('Values of %s' % y_value)
ax.set_xlabel('Features of the %s '
% x_data)
ax.set_title('The box with %d features for the %s'
% (len(x_feature), y_value) )
boxplot(x_data = 'survived'
, y_data = data
, y_value = 'fare'
, base_color = 'b'
, median_color = 'r')
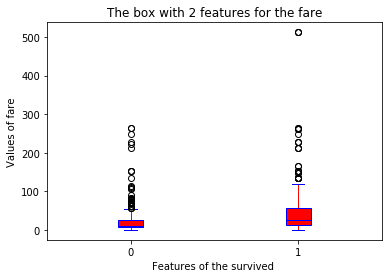
boxplot(x_data = 'survived'
, y_data = data[['survived','age']].dropna()
, y_value = 'age'
, base_color = 'b'
, median_color = 'r')
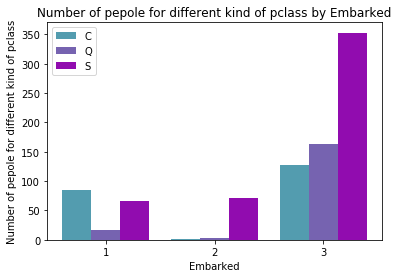
size_by_embarked_pclass = pd.pivot_table(data,index='embarked',columns='pclass',aggfunc='size')
def groupedbarplot(x_data, y_data_list, y_data_names, colors, x_label, y_label, title):
print(size_by_embarked_pclass)
_, ax = plt.subplots()
total_width = 0.8
ind_width = total_width / len(y_data_list)
alteration = np.arange(-total_width/2+ind_width/2,
total_width/2+ind_width/2, ind_width)
x_data = [i for i in range(len(x_data))]
for i in range(0, len(y_data_list)):
ax.bar(x_data + alteration[i], y_data_list[i], color = colors[i],
label = y_data_names[i], width = ind_width)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.set_xticks(np.linspace(0,2,3))
ax.set_xticklabels(size_by_embarked_pclass.columns)
ax.legend(loc = 'upper left')
groupedbarplot(x_data = size_by_embarked_pclass.index.values
, y_data_list = [size_by_embarked_pclass[1],
size_by_embarked_pclass[2],
size_by_embarked_pclass[3]]
, y_data_names = ['C', 'Q', 'S']
, colors = ['#539caf', '#7663b0', '#910caf']
, x_label = 'Embarked'
, y_label = 'Number of pepole for different kind of pclass'
, title = 'Number of pepole for different kind of pclass by Embarked')
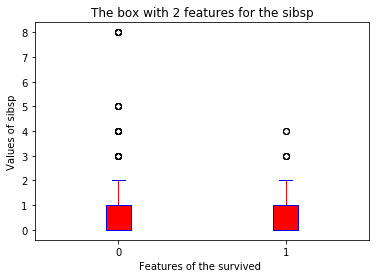
boxplot(x_data = 'survived'
, y_data = data
, y_value = 'sibsp'
, base_color = 'b'
, median_color = 'r')
data['sibsp'].value_counts()
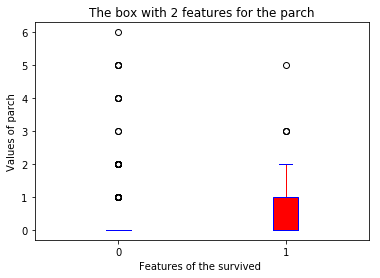
boxplot(x_data = 'survived'
, y_data = data
, y_value = 'parch'
, base_color = 'b'
, median_color = 'r')
data['parch'].value_counts()
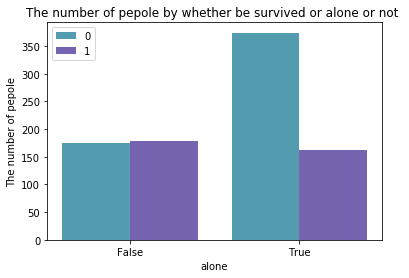
size_by_alone_survived = pd.pivot_table(data,index='alone',columns='survived',aggfunc='size')
def groupedbarplot(x_data, y_data_list, y_data_names, colors, x_label,
y_label, title):
print(size_by_alone_survived)
_, ax = plt.subplots()
total_width = 0.8
ind_width = total_width / len(y_data_list)
alteration = np.arange(-total_width/2+ind_width/2,
total_width/2+ind_width/2, ind_width)
x_data = [i for i in range(len(x_data))]
for i in range(0, len(y_data_list)):
ax.bar(x_data + alteration[i], y_data_list[i], color = colors[i],
label = y_data_names[i], width = ind_width)
ax.set_ylabel(y_label)
ax.set_xlabel(x_label)
ax.set_title(title)
ax.set_xticks(np.linspace(0,1,2))
ax.set_xticklabels(size_by_alone_survived.index)
ax.legend(loc = 'upper left')
groupedbarplot(x_data = size_by_alone_survived.index.values
, y_data_list = [size_by_alone_survived[0],
size_by_alone_survived[1]]
, y_data_names = ['0', '1']
, colors = ['#539caf', '#7663b0']
, x_label = 'alone'
, y_label = 'The number of pepole'
, title = 'The number of pepole by whether be survived or alone or not ')
源码获取:关注微信公众号” AI阅读知识图谱“,回复” Python数据可视化“获取已更新内容全部代码。
Original: https://blog.csdn.net/qq_34740277/article/details/119866818
Author: AI阅读和图谱
Title: Python数据可视化 |4、可视化案例练习题目(基于Matplotlib)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/765948/
转载文章受原作者版权保护。转载请注明原作者出处!