

一、导入和主要方法
1、导入wordcloud包
生成词云图之后还要显示出来,所以还会用到matplotlib
如果要设置mask蒙版,还需要从imageio导入imread()函数
如果需要设置词云中字体的颜色,还会用到matplotlib中的colors
import wordcloud
import matplotlib.pyplot as plt
from imageio import imread
from matplotlib import colors
2、主要方法
wc = wordcloud.WordCloud(...)
wc.fit_words(frequencies)
wc.generate(text)
wc.to_file()
wc.to_array(filename)
其中” 根据词频生成 “和” 根据文本生成 “两种方法中只能选取一种。
(1)wordcloud.WordCloud()参数说明
这个也是参数最多的地方
font_path : string
//字体路径,词云图默认不支持中文,所以一般都要设置该参数
stopwords :字符串列表
//设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS
mask : nd-array
//如果不设置,则词云是正规矩形。
//如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。
//一般结合imread(),将图片中不是白色的地方作为轮廓。
width : int
//输出的画布宽度,默认为400像素,越宽,词云中包含的关键词越多
height : int
//输出的画布高度,默认为200像素
prefer_horizontal : float (default=0.90)
//词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 )
max_words : number (default=200)
//要显示的词的最大个数
min_font_size : int (default=4)
//显示的最小的字体大小
colormap : string or matplotlib colormap, default="viridis"
//给每个单词随机分配颜色,若指定color_func,则忽略该方法
background_color : color value (default="black")
//背景颜色,如background_color='white',背景颜色为白色。
max_font_size : int or None (default=None)
//显示的最大的字体大小
relative_scaling : float (default=.5)
//词频和字体大小的关联性
****************一些不常用的参数**************
color_func : callable, default=None
//生成新颜色的函数,如果为空,则使用 self.color_func
regexp : string or None (optional)
//使用正则表达式分隔输入的文本
font_step : int (default=1)
//字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差。
scale : float (default=1)
//按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。
其中也写参数的具体设置在后面的例子中看。
(2)wc.fit_words(frequencies)
frequencies是一个字典,键为单词,值为出现的次数
(3)wc.generate(text)
text没啥好说的,就是一段文字
二、实例
包括了,字体设置、颜色设置、蒙版设置、
1、例一:wc.fit_words(frequencies)先去停用词
from wordcloud import WordCloud
import jieba
from collections import Counter
from imageio import imread
import matplotlib.pyplot as plt
"""获取文本内容"""
with open("济南的冬天.txt","r",encoding="utf-8") as fp:
content = fp.read()
words_temp = jieba.lcut(content)
words = []
"""读取停用词"""
with open("C:/停用词/哈工大停用词.txt","r",encoding="utf-8") as fp:
stopwords = [s.rstrip() for s in fp.readlines()]
"""去掉切分词语中的停用词"""
for w in words_temp:
if w not in stopwords:
words.append(w)
frequency = dict(Counter(words))
font = "C:/Fonts/AaMingYueJiuLinTian.ttf"
mask_image = imread("20160303160528046.png")
wc = WordCloud(font_path=font,
background_color="white",
mask=mask_image)
wc.fit_words(frequency)
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file("C:/Users/lenovo/Desktop/pic/6.png")


上例是手动先去除掉分词结果中的停用词,然后统计词频,再直接画图。
下面这个例子,没有手动去除停用词,直接统计词频,但是在WordCloud函数中设置了stopwords参数,这样更加方便,而且和上面的方法使用的还是同一个停用词表。(但是画出的图好像不大一样)
2、例二:wc.fit_words(frequencies)在WordCloud()中去停用词
"""获取文本内容"""
with open("济南的冬天.txt","r",encoding="utf-8") as fp:
content = fp.read()
words = jieba.lcut(content)
"""读取停用词"""
with open("C:/停用词/哈工大停用词.txt","r",encoding="utf-8") as fp:
stopwords = [s.rstrip() for s in fp.readlines()]
frequency = dict(Counter(words))
font = "C:/Fonts/AaMingYueJiuLinTian.ttf"
mask_image = imread("20160303160528046.png")
wc = WordCloud(font_path=font,
background_color="white",
mask=mask_image,
stopwords=stopwords)
wc.fit_words(frequency)
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file("C:/Users/lenovo/Desktop/pic/6.png")
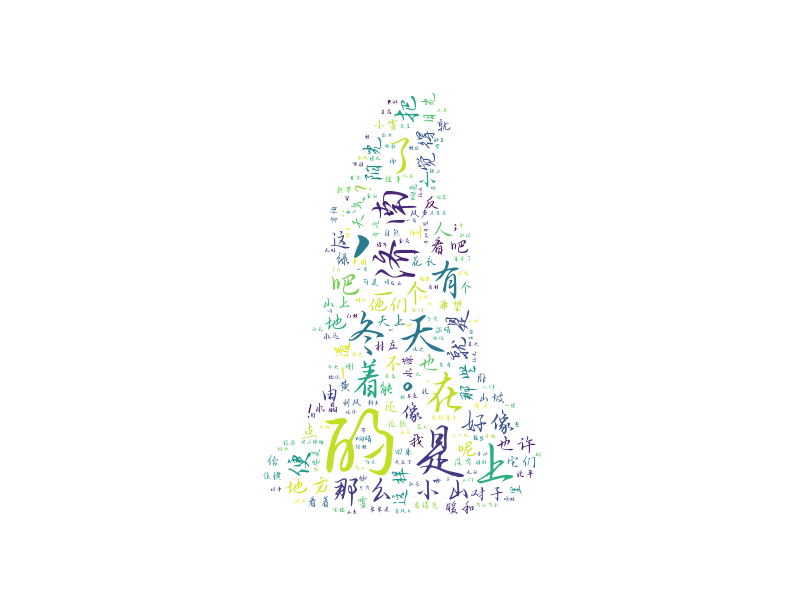
小总结: wc.fit_words(frequencies)逻辑:
- 分词(加载用户词典、去停用词)、统计词频
- 生成wordcloud对象
- 处理(plt画图、保存图像)
3、例三:wc.generate(text)
"""获取文本内容"""
with open("济南的冬天.txt","r",encoding="utf-8") as fp:
content = fp.read()
font = "C:/Fonts/AaMingYueJiuLinTian.ttf"
mask_image = imread("20160303160528046.png")
wc = WordCloud(font_path=font,
background_color="white",
mask=mask_image)
wc.generate(content)
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file("C:/Users/lenovo/Desktop/pic/7.png")

在上例中,我也尝试了在WordCloud()方法中设置了stopwords参数,但是一点效果也没有。
小总结: wc.generate(text)处理逻辑
- 读取文本
- 生成WordCloud对象
- 处理(展示、保存)
三、颜色设置
最后再来看看词云的颜色设置,默认情况下,词云的颜色是随机的;
方法一:
wordcloud.ImageColorGenerator(image, default_color=None)返回一个颜色生成器,把这个值赋值给WordCloud()中的color_func参数,效果就是单词的颜色和图像中对应位置的色彩一样。
也可以使用colormap参数手动设置需要使用的颜色,
方法二:
WordCloud()的colormap参数值需要使用matplotlib的colors库中的ListedColormap方法。要注意方法一和二的两个参数值不能同时使用。
方法一:
from wordcloud import ImageColorGenerator
font = "C:/Fonts/AaMingYueJiuLinTian.ttf"
mask_image = imread("20160303160528046.png")
bg_color = ImageColorGenerator(mask_image, default_color=None)
wc = WordCloud(font_path=font,
background_color="white",
mask=mask_image,
color_func=bg_color)
wc.fit_words(frequency)
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file("C:/Users/lenovo/Desktop/pic/8.png")
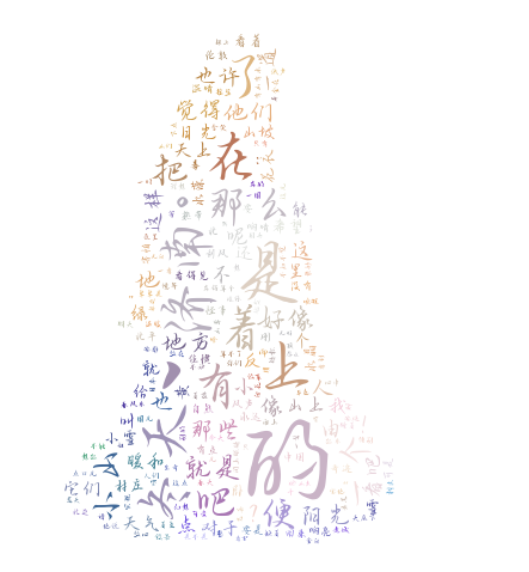
方法二
from matplotlib import colors
color_list = ['#FF0000','#a41a1a']
colormap = colors.ListedColormap(color_list)
font = "C:/Fonts/AaMingYueJiuLinTian.ttf"
mask_image = imread("20160303160528046.png")
wc = WordCloud(font_path=font,
background_color="white",
mask=mask_image,
colormap=colormap)
wc.fit_words(frequency)
plt.imshow(wc)
plt.axis("off")
plt.show()
wc.to_file("C:/Users/lenovo/Desktop/pic/8.png")

Original: https://blog.csdn.net/qq_48003414/article/details/117427378
Author: IRON POTATO
Title: wordcloud生成词云图(含形状、颜色设置)
原创文章受到原创版权保护。转载请注明出处:https://www.johngo689.com/764765/
转载文章受原作者版权保护。转载请注明原作者出处!